


高性能模板库Eigen架构分析及性能优化实践
发表于 2026/05/06
0
1. Eigen库设计结构
Eigen库是一个用于线性代数运算的C++模板库。它提供了高性能的矩阵运算和线性代数操作,被广泛应用于科学计算、机器学习和计算机图形学等领域。
1.1 Eigen类层次结构设计
Eigen通过特有的类层次结构来组织代码,在实现功能复用的同时,也通过奇异递归模板模式(CRTP) 来避免运行时开销。它用CRTP静态多态代替virtual函数,将所有函数调用解析从运行时提前到编译期,消除了虚函数表查找的额外开销。整个继承体系也刻意避免多重继承,确保固定尺寸的小型矩阵/向量完全在栈上分配,实现零动态内存开销。
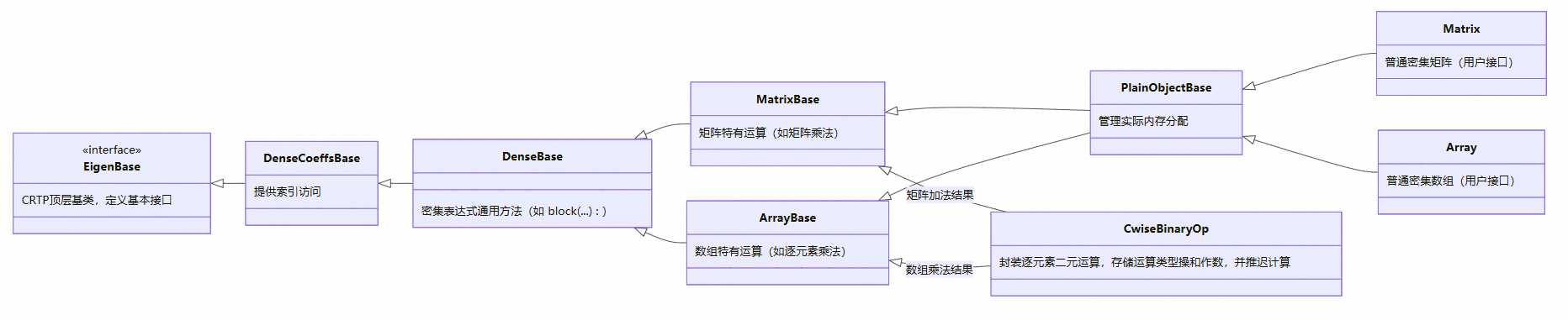
1.2 Eigen中的表达式模板
表达式模板是一种编译期优化技术,作为Eigen的核心设计之一,主要用于:
- 消除临时变量:将
A = B + C + D这类多步运算融合为单次循环,避免中间临时对象的创建与销毁。 - 实现惰性求值:运算符不立即计算,而是构建一个“表达式树”,直到最终赋值时才进行计算。
简单来说,对于表达式 A = B + C + D,传统C++类会产生多个临时变量,而Eigen 并不立即执行加法并产生临时变量,该语句会返回一个轻量级的表达式对象,它仅仅记录了“我要做加法”的意图以及指向 B、C、D 的指针。只有在最后执行赋值操作 = 时,编译器才会通过递归模板展开,将整个表达式融合成一个单一的循环。这消除了中间临时对象的内存分配和拷贝开销。
// 传统实现会产生临时变量 tmp1, tmp2...
// Eigen表达式模板的等效优化结果:
for (int i = 0; i < size; ++i) {
v1[i] = v2[i] + v3[i] + v4[i];
}1.3 Eigen模块化设计
Eigen并非一个庞大的单体库,而是由一系列功能独立的模块组成,用户可以在需要时引入相应模块。
| 模块 | 头文件 | 功能简介 |
|---|---|---|
| Core | #include <Eigen/Core> | 核心基础,包含Matrix、Array等基础数据结构及运算。 |
| Dense | #include <Eigen/Dense> | 最常用,包含Core及大部分密集矩阵运算模块。 |
| Geometry | #include <Eigen/Geometry> | 几何模块,用于3D空间变换(如四元数、旋转矩阵)。 |
| LU | #include <Eigen/LU> | LU分解。 |
| Cholesky | #include <Eigen/Cholesky> | Cholesky分解,适用于正定矩阵。 |
| QR | #include <Eigen/QR> | QR分解。 |
| SVD | #include<Eigen/SVD> | 奇异值分解(SVD)。 |
| Eigenvalues | #include <Eigen/Eigenvalues> | 特征值与特征向量分解。 |
| Sparse | #include <Eigen/Sparse> | 稀疏矩阵存储与运算。 |
| IterativeSolvers | #include <Eigen/IterativeSolvers> | 稀疏矩阵的迭代求解器(如共轭梯度法) |
1.4 Eigen对接第三方算子库
当处理超大规模矩阵运算时,Eigen 自身的 GEMM等内核可能不及其他针对特定场景手写优化的库。Eigen 允许在不修改用户代码的前提下,将内部计算调用透明地替换为外部高性能库。
1.4.1 通用 BLAS/LAPACK 对接
Eigen 3.3及以上版本可以链接任何符合 C 接口(LAPACKE)或 Fortran 接口的 BLAS/LAPACK 实现。启用步骤:
- 编译前定义宏:
EIGEN_USE_BLAS:启用 BLAS 后端(用于矩阵乘法、三角矩阵求解等)。
EIGEN_USE_LAPACKE :启用 LAPACK 后端(用于分解、求解特征值等)。(注意:这些宏须在包含任何 Eigen 头文件之前定义)
- 链接对应的库:
对于KML库: -lkblas -lklapack
实际上,Eigen 内部调用 BLAS 时,会通过 BLASFUNC 宏处理 Fortran 名称修饰,并自动调整行/列主序参数。
1.4.2 自定义后端与扩展点
高级用户可以编写自己的 Eigen::internal 函数特化,替换 Eigen 的默认内核。例如,自己特化 general_matrix_matrix_product 来调用某个私有加速库。这需要对 Eigen 内部 API 有深入了解,但提供了最大的灵活性。
2. Eigen库性能优化实践
在 EIGEN_USE_BLAS机制基础上,可以进一步扩展并优化多类Eigen接口,以提升应用场景下的整体性能。
2.1 Eigen库适配鲲鹏数学库
对于矩阵加法等基础算子,在不修改Eigen源码的前提下,新增AssignEvaluator_KUNPENG.h文件,通过重载核心赋值函数,将符合条件的密集矩阵/数组运算,替换为KML的调用。实现上延续Eigen宏定义的方式作为路径选择开关,用户调用方式与原生 Eigen 接口保持一致,仅需在编译阶段将宏定义 -DEIGEN_USE_BLAS 替换为-DKUNPENG_USE 即可启用相应优化路径。
2.1.1 拦截点设置
Eigen 在执行形如 dst = expr; 或 dst += src; 的运算时,会经过内部函数 call_dense_assignment_loop(或 call_assignment_no_alias)来分派实际的循环计算。在AssignEvaluator_KUNPENG.h,提供与 Eigen 内部同名的重载版本,以矩阵加法算子为例:
// 声明blas中的函数
extern "C" {
void cblas_somatadd(int order, int transa, int transb, int m, int n,
float alpha, const float *a, int lda,
float beta, const float *b, int ldb,
float *c, int ldc);
}
namespace Eigen {
namespace internal {
// 特化/重载:拦截 dst = A + B (float, 单精度)
template <int DstRows, int DstCols, int DstOptions, int DstMaxRows, int DstMaxCols, int SrcRows1, int SrcCols1,
int SrcOptions1, int SrcMaxRows1, int SrcMaxCols1, int SrcRows2, int SrcCols2, int SrcOptions2, int SrcMaxRows2,
int SrcMaxCols2>
EIGEN_DEVICE_FUNC EIGEN_STRONG_INLINE void call_dense_assignment_loop(
Eigen::Matrix<float, DstRows, DstCols, DstOptions, DstMaxRows, DstMaxCols> &dst,
const Eigen::CwiseBinaryOp<Eigen::internal::scalar_sum_op<float, float>,
Eigen::Matrix<float, SrcRows1, SrcCols1, SrcOptions1, SrcMaxRows1, SrcMaxCols1> const,
Eigen::Matrix<float, SrcRows2, SrcCols2, SrcOptions2, SrcMaxRows2, SrcMaxCols2> const> &src,
const Eigen::internal::assign_op<float, float> &func)
{
resize_if_allowed(dst, src, func);
// ---------- 快速路径条件判断 ----------
// 提取存储顺序、实际维度、主步长
StorageOptions srcMajor = ...
StorageOptions dstMajor =...
const int lhsRows = ...
const int lhsCols = ...
......
// 连续内存且布局一致时,调用外部加速库
if (srcMajor == dstMajor && lhsRows == dstRows && lhsCols == dstCols &&
lhsMajorStride == dstMajorStride && dstMajorStride == 1)
{
// 转换 Eigen 存储顺序枚举到 CBLAS 风格
CBLAS_ORDER order = (srcMajor == ColMajor) ? CblasColMajor : CblasRowMajor;
// 调用KML接口:C = 1*A + 1*B
cblas_somatadd(order, CblasNoTrans, CblasNoTrans,
lhsRows, lhsCols,
1.0f, (const float*)src.lhs().data(), lhsRows,
1.0f, (const float*)src.rhs().data(), lhsRows,
dst.data(), dstRows);
}
else
{
// ---------- 回退路径:使用 Eigen 通用内核 ----------
typedef evaluator<Matrix<float, DstRows, DstCols, DstOptions, DstMaxRows, DstMaxCols>> DstEvaluator;
typedef evaluator<CwiseBinaryOp<
scalar_sum_op<float, float>,
Matrix<float, SrcRows1, SrcCols1, SrcOptions1, SrcMaxRows1, SrcMaxCols1> const,
Matrix<float, SrcRows2, SrcCols2, SrcOptions2, SrcMaxRows2, SrcMaxCols2> const
>> SrcEvaluator
......
}
}
} // namespace internal
} // namespace Eigen代码说明:
此处提供了与 Eigen 内部完全同名的函数模板,但参数类型更加具体(单精度矩阵加法表达式),因此编译器会优先选择这个版本。在确认矩阵存储连续、布局相同且步长为 1 后,直接调用 cblas_somatadd。其他不满足条件的表达式都会滑入 else 分支,进入Eigen原生实现。上层代码无感,只要包含这个重载头文件,所有形如 MatrixXf C = A + B ; 的调用都会自动获得加速。
2.1.2 宏定义开关
在Eigen/src/Core文件中,自定义KUNPENG_USE 预处理器宏,编译时可动态开启。当该宏被定义时,预处理器会将 AssignEvaluator_KUNPENG.h(即上一步的重载头文件)包含进编译单元,从而在编译阶段用KML加速函数替换掉 Eigen 原生的若干密集矩阵赋值循环。
#ifdef KUNPENG_USE
#include "src/Core/AssignEvaluator_KUNPENG.h"
#endif2.2 Eigen算子向量化——以tanh激活函数为例
在ARM架构上,tanh函数默认使用NEON指令集进行向量化处理,NEON的向量长度固定为128位。SVE支持128位到2048位的可变长度向量,SVE可以一次性处理更多的tanh计算来提升性能。代码实现中,通过模板特例化的方式,在tanh的计算过程进行了SVE向量化,使用sve intrinsic优化实现核心计算kernel。Eigen张量运算(如A=tanh(B))会被拆解为一个表达式树,其执行过程:
- TensorAssignOp:赋值操作节点(根节点),左子节点:TensorMap< A >,右子节点TensorCwiseUnaryOp<tanh,B>
- TensorMap: 内存映射张量节点(叶子节点),负责直接操作内存。
- TensorCwiseUnary< tanh >:tanh一元运算节点(中间节点)
修改涉及文件:TensorEvaluator.h、TensorExecutor.h
TensorEvaluator.h
Eigen 的TensorEvaluator是张量表达式求值的核心组件,为每个表达式节点提供独立的求值逻辑,负责将张量表达式(如赋值、一元运算)转换为实际的内存操作 / 计算操作。此次SVE优化主要修改下列求值逻辑:
- TensorAssignOp:张量赋值操作(将tanh结果赋值给TensorMap)(修改自TensorAssign.h)
//新增部分:
struct TensorEvaluator<
const TensorAssignOp<
Eigen::TensorMap<PlainObjectType, Options_, MakePointer_>,
const Eigen::TensorCwiseUnaryOp<Eigen::internal::scalar_tanh_op<float>, ArgType>>, Device> {
//...
// 提供两种数据包(packet)处理方式:SVE(Single Vector Extension)优化路径和常规路径
EIGEN_DEVICE_FUNC EIGEN_STRONG_INLINE void evalPacketSve(Index i) const {
m_leftImpl.writeSve(i, m_rightImpl.packetSve(i));
}
EIGEN_DEVICE_FUNC EIGEN_STRONG_INLINE void evalPacketOpt(Index i, bool useSve) const {
if (useSve) {
evalPacketSve(i);
return;
}
evalPacket(i);
}- Eigen::TensorMap:封装TensorMap的底层内存操作,比如标量读写/packet写入/向量写入/块级内存操作等。在此处新增提供 SVE 优化的读写能力,即赋值操作的目标内存操作部分。
template <typename PlainObjectType, int Options_, template <class> class MakePointer_, typename Device>
struct TensorEvaluator<Eigen::TensorMap<PlainObjectType, Options_, MakePointer_>, Device> {
// ...
EIGEN_DEVICE_FUNC EIGEN_STRONG_INLINE void writeSve(Index index, const svfloat32_t x) const {
eigen_assert(m_data != NULL);
svst1_f32(svptrue_b32(), m_data + index, x);
}
};- TensorCwiseUnaryOp<scalar_tanh_op< float>>:tanh运算的计算逻辑,是主要的SVE向量计算优化点。拦截点:只有开启 SVE 硬件特性且执行 float 类型的 tanh 时,才进入此优化分支。
// 只有开启 SVE 硬件特性且执行 float 类型的 tanh 时,才进入此优化分支
#ifdef __ARM_FEATURE_SVE
template <typename ArgType, typename Device>
struct TensorEvaluator<const TensorCwiseUnaryOp<Eigen::internal::scalar_tanh_op<float>, ArgType>, Device> {
// ...
};预置数学常数表如下:
// 预计算的多项式系数
static constexpr SVE_EXPM1F_DATA G_SVE_EXPM1F_DATA = {
.c2 = 0x1.5558b800p-0005f, .ln2Hi = 0x1.62e4p-1f, // ...
.invLn2 = 0x1.715476p+0f, .shift = 0x1.8000fep23f,
};sve向量化tanh公式实现如下:
// 核心向量化计算逻辑
EIGEN_DEVICE_FUNC EIGEN_STRONG_INLINE svfloat32_t packetSve(Index index) const {
svbool_t pg = svptrue_b32(); // 全真谓词,处理所有通道
svfloat32_t x = svld1_f32(pg, m_argImpl.data() + index); // 一次性加载 512bit(SVE最大) 数据
/* 1. 使用 SVE 优化的 expm1 近似算法计算 e^(2x) - 1 */
svfloat32_t e2m1 = VsExpm1InlineSve(pg, svmul_f32_x(pg, x, svdup_n_f32(2.0f)));
/* 2. 计算分母 e^(2x) + 1 */
svfloat32_t e2a1 = svadd_f32_x(pg, e2m1, svdup_n_f32(2.0f));
/* 3. 向量除法得到 tanh 结果 */
svfloat32_t res = svdiv_f32_x(pg, e2m1, e2a1);
/* 4. 边界处理(饱和处理):当 x 过大时直接置为 1.0 或 -1.0 */
res = svdup_n_f32_m(res, cmpSp, 1.0f);
res = svdup_n_f32_m(res, cmpSpNeg, -1.0f);
return res;
}TensorExecutor.h
执行调度层,负责批量调度Evaluator的求值逻辑
- evalPacketOpt:Evaluator 层定义的分支判断,根据useSve决定是否走SVE;
- useSve:由evaluator.areAllAddressValid()决定(Evaluator 层实现,确保内存地址有效才能用 SVE 向量化)
- adjustPacketSize:SVE 模式下强制设为 16
#ifdef __ARM_FEATURE_SVE
template <typename PlainObjectType, int Options_, template <class> class MakePointer_,
typename XprType, typename Device, typename StorageIndex>
struct EvalRange<
Eigen::TensorEvaluator<
const Eigen::TensorAssignOp<
Eigen::TensorMap<PlainObjectType, Options_, MakePointer_>,
const Eigen::TensorCwiseUnaryOp<Eigen::internal::scalar_tanh_op<float>, XprType>>, Device>,
StorageIndex, /*Vectorizable*/ true> {
typedef Eigen::TensorEvaluator<
const Eigen::TensorAssignOp<
Eigen::TensorMap<PlainObjectType, Options_, MakePointer_>,
const Eigen::TensorCwiseUnaryOp<Eigen::internal::scalar_tanh_op<float>, XprType>>, Device> Evaluator;
static constexpr int PacketSize = unpacket_traits<typename Evaluator::PacketReturnType>::size;
static void run(Evaluator* evaluator_in, const StorageIndex firstIdx, const StorageIndex lastIdx) {
Evaluator evaluator = *evaluator_in;
eigen_assert(lastIdx >= firstIdx);
StorageIndex i = firstIdx;
bool useSve = evaluator.areAllAddressValid();
int adjustPacketSize = useSve ? 16 : PacketSize;
if (lastIdx - firstIdx >= adjustPacketSize) {
eigen_assert(firstIdx % adjustPacketSize == 0);
StorageIndex last_chunk_offset = lastIdx - 4 * adjustPacketSize;
// Give compiler a strong possibility to unroll the loop. But don't insist
// on unrolling, because if the function is expensive compiler should not
// unroll the loop at the expense of inlining.
for (; i <= last_chunk_offset; i += 4 * adjustPacketSize) {
for (StorageIndex j = 0; j < 4; j++) {
evaluator.evalPacketOpt(i + j * adjustPacketSize, useSve);
}
}
last_chunk_offset = lastIdx - adjustPacketSize;
for (; i <= last_chunk_offset; i += adjustPacketSize) {
evaluator.evalPacketOpt(i, useSve);
}
}
for (; i < lastIdx; ++i) {
evaluator.evalScalar(i);
}
}
static StorageIndex alignBlockSize(StorageIndex size) {
// Align block size to packet size and account for unrolling in run above.
if (size >= 16 * PacketSize) {
return (size + 4 * PacketSize - 1) & ~(4 * PacketSize - 1);
}
// Aligning to 4 * PacketSize would increase block size by more than 25%.
return (size + PacketSize - 1) & ~(PacketSize - 1);
}
};
#endif