


KuDNN的矩阵乘之JIT实现详解
发表于 2026/05/15
0
概述
本文讲从KuDNN::Gemm接口入手,解析JIT的实现原理,分析其如何生成代码和执行。
基本结构层次
kudnn的目录结构为
src/dnn/
├── include/ # Public API headers
│ ├── types/ # Data types, shapes, layouts, enums
│ ├── service/ # Error handling, threading, service APIs
│ ├── operations/ # Operation descriptors (GEMM, Conv, Norm, etc.)
│ └── kudnn.hpp # Main include file
└── src/ # Implementation
├── kernels/ # Compute kernels (convolution, softmax, rmsnorm, reorder, vml)
├── matmul_jit/ # GEMM JIT code generation
│ ├── MatrixComputation/ # JIT Code for SME
│ ├── VectorComputation/ # JIT Code for SVE
│ └── kudnn_gemm_jit.hpp # JIT Base implement
├── aarch64_codegen/ # ARM64 assembly code generation
├── vector_apis/ # SVE vector intrinsics
└── *.cpp # Operation implementations
inlclude/operations目录下声明了GEMM接口类,src/matmul_jit下定义了JIT实现逻辑,JIT包含SME与SVE两类,
KuDNN 的 JIT 代码生成器分为三层:
┌─────────────────────────────────────────────────────────┐
│ kudnn_jit.hpp - JIT 框架层 │
│ - KUDNN_JIT_Generator: 代码生成基类 │
│ - ImplBase<Task>: 任务执行基类 │
│ - SolutionHandler: 实现缓存与选择 │
├─────────────────────────────────────────────────────────┤
│ matmul_jit/kudnn_gemm_jit.hpp - GEMM JIT 实现 │
│ - MatMulKernelCodeGenBase: 内核代码生成器模板 │
│ - MatMulImplBase: GEMM 执行基类 │
├─────────────────────────────────────────────────────────┤
│ aarch64_codegen/ - ARM64 指令生成器 │
│ - cg_codegen.hpp: CodeGenerator (SVE/SME 指令支持) │
└─────────────────────────────────────────────────────────┘
SME 矩阵累加器 核心指令是SME的fmopa外积指令,计算一个2VLx2VL即32x32的向量外积。
权重矩阵 (z2, z3, z6, z7)
↓
源矩阵 ┌───────┬───────┐
(z0,z1,z4,z5) │ za0.s │ za1.s │ ← 累加结果
├───────┼───────┤
│ za2.s │ za3.s │
└───────┴───────┘2. 算法流程
2.1. Gemm实例化
在KuDNN用BLAS一章中介绍了非JIT的实例化过程,在GemmImpl构造函数中会选择是否采用JIT方案,本次将沿着FindSolution函数这一JIT分支深入解析其实现,当前KuDNN仅支持基于sme指令的JIT实现。
{
bool srcJIT = weiJIT = dstJIT = false;
#ifdef KUDNNL_920Pro
srcJIT = srcJIT || (gemmImplInfo.srcInfo.GetType() == Element::TypeT::S8);
...
#endif // KUDNNL_920Pro
if (srcJIT && weiJIT && dstJIT) {
impl = FindSolution(gemmImplInfo, Threading::GetMaxNumThreads());
}
}2.2. 主要类图
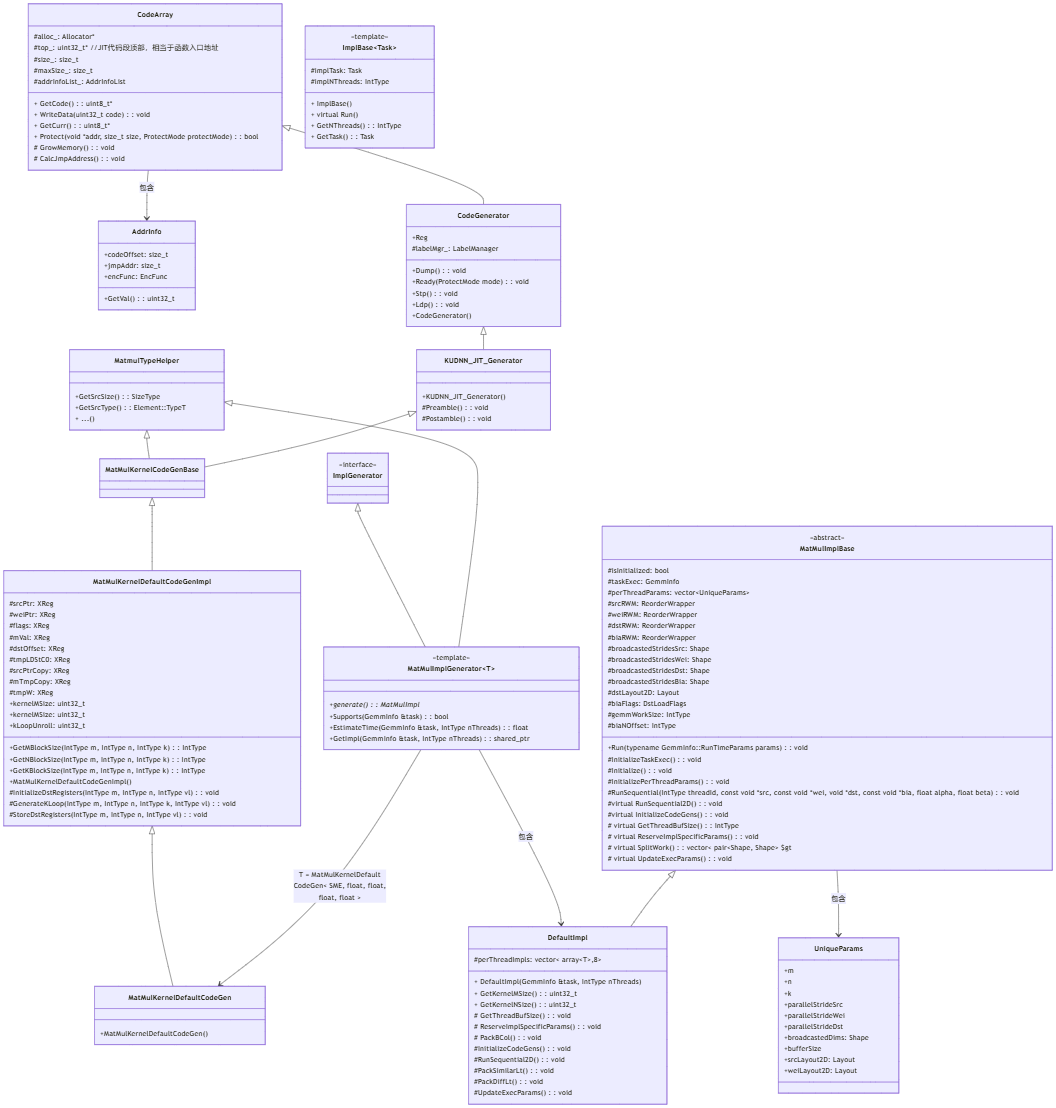
从类图可以看到,CodeArray负责管理JIT代码内存与写入,MatMulKernelDefaultCodeGenImpl定义了JIT代码的生成逻辑,CodeGenerator定义了具体计指令的生成原理。
2.3. 函数流程
以SME架构的F32类型Gemm为例:
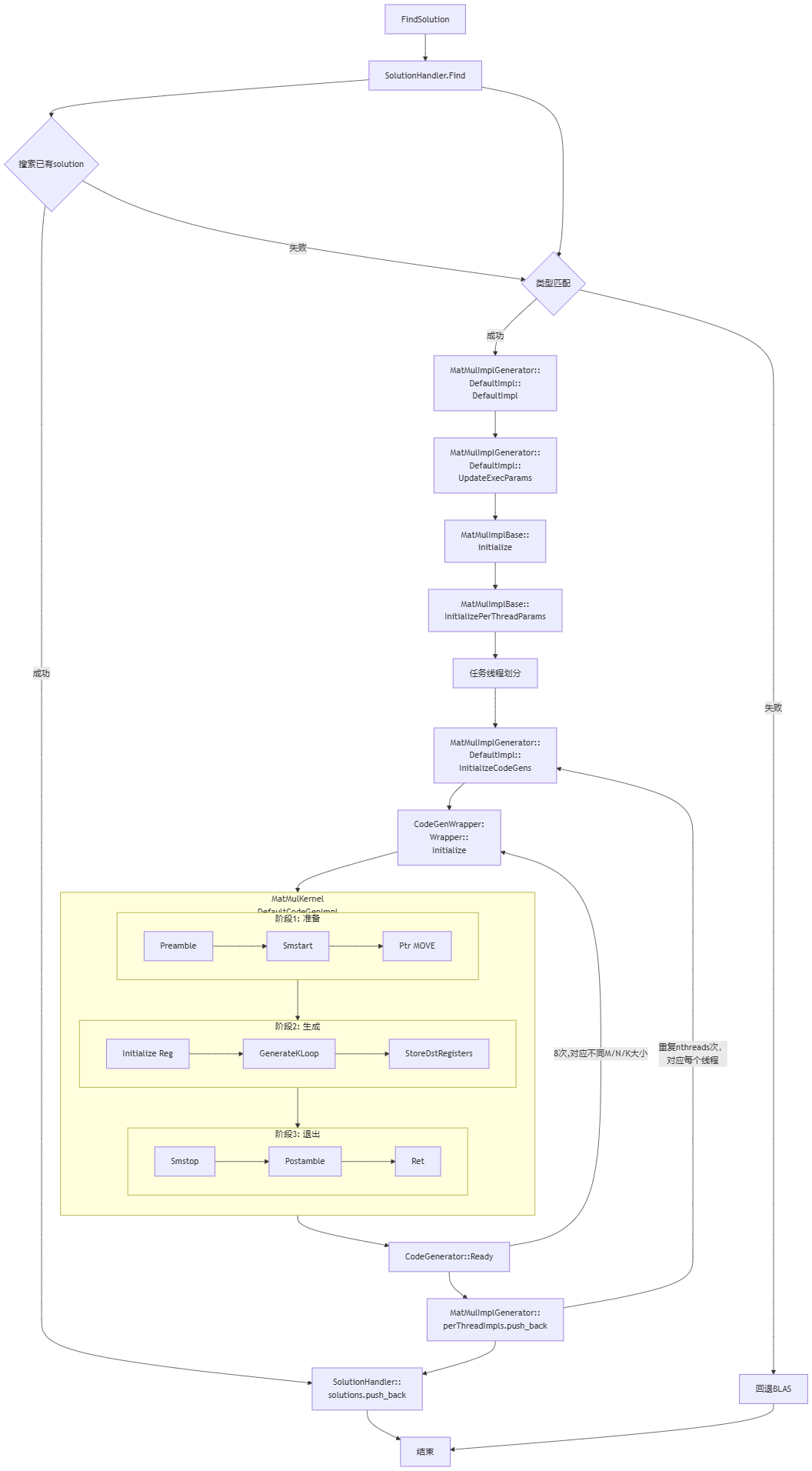
2.4. MatMulKernelDefaultCodeGenImpl::MatMulKernelDefaultCodeGenImpl函数详解
该函数中可以看到熟悉的矩阵乘法的实现逻辑,其过程像一个矩阵乘函数的汇编代码,有callee的寄存器保存,函数参数加载,谓词寄存器设置,开关sme模式,ZA寄存器初始化,K循环计算,ZA数据写回内存,callee函数保存的寄存器恢复,函数return。
{
Service::Unused(srcOffsetArg, weiOffsetArg);
if ((m >= 0) && (n >= 0) && (k >= 0)) {
Preamble(); //函数入栈
Smstart(ARMCG::StreamMode::SMZA); // SME 模式开始
Mov(mVal, m);
Mov(nVal, n);
//参数传递
Mov(biaPtrCopy, biaPtr);
IntType vl = svcntw();
// initialize predicates for loads and stores
Mov(tmp, 0);
// p0, p2 used for SRC, p1, p3 used for WEI
Whilelt(ARMCG::PRegS(NUM_0), tmp, mVal);
Whilelt(ARMCG::PRegS(NUM_1), tmp, nVal);
if ((m > vl) || (n > vl)) {
Incw(tmp);
if (m > vl) {
Whilelt(ARMCG::PRegS(NUM_2), tmp, mVal);
}
if (n > vl) {
Whilelt(ARMCG::PRegS(NUM_3), tmp, nVal);
}
}
// constants to perform continious stores from ZA tiles
Mov(tmpLDStC0, NUM_0);
Mov(tmpLDStC1, NUM_4);
Mov(tmpLDStC2, NUM_8);
Mov(tmpLDStC3, NUM_12);
InitializeDstRegisters(m, n, vl);
GenerateKLoop(m, n, k, vl); // K方向累加计算指令
StoreDstRegisters(m, n, vl); // 写回累加器结果
Smstop(ARMCG::StreamMode::SMZA); // SME 模式结束
Postamble(); //函数出栈
}
Ret();
}2.5. 指令生成
这里以smestart指令为例,Concat通过组合不同的字段得到32位指令,WriteData将指令写到内存。top_是jit code的顶部,地址递增地写入新指令。
void CodeGenerator::Smstart(StreamMode mod)
{
MatrixComputationStart(mod);
}
void CodeGenerator::MatrixComputationStart(StreamMode mod)
{
uint32_t code =
Concat({LeftShift(0x1AA068, BITFIELD_11), LeftShift(mask, BITFIELD_9), LeftShift(0x17F, BITFIELD_0)});
WriteData(code);
}
void CodeArray::WriteData(uint32_t code)
{
if (size_ >= maxSize_) {
if (type_ == Type::MEM_AUTO_GROW) {
GrowMemory();
} else {
throw Error(Err::CODE_IS_TOO_BIG);
}
}
top_[size_++] = code;
}
2.6. CodeGenerator::Ready函数详解
Ready函数的定义位于CodeGenerator类里,计算JIT Code被跳转地址,设置JIT code所在内存属性,确保缓存写入到内存中。
void CodeGenerator::Ready(ProtectMode mode)
{
if (HasUndefinedLabel()) {
throw Error(Err::LABEL_IS_NOT_FOUND);
}
if (IsAutoGrow()) {
CalcJmpAddress();
}
if (UseProtect()) {
SetProtectMode(mode);
}
ClearCache(static_cast<void *>(GetCode()), static_cast<void *>(GetCurr()));
}
2.7. Gemm Run计算
在GemmImpl::Run的定义中,下面的条件分支会因为impl!=nullptr跳转到JIT分支执行
if (impl != nullptr) {
if (impl->GetNThreads() != Threading::GetMaxNumThreads()) {
impl = FindSolution(impl->GetTask(), Threading::GetMaxNumThreads());
}
impl->Run({a, b, c, bias, alpha, beta});
} else {
GemmHelpers::BatchedExtendedGemm(gemmImplInfo, a, b, c, bias, alpha, beta, numThreads);
}
这里有个额外判断,如果线程数发生变化需要重新执行FindSolution函数,因为线程不同其任务划分会发生变化。
函数调用流程如下:
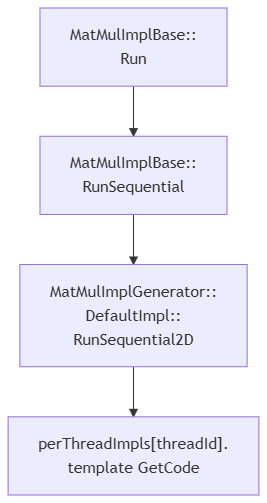
2.8. MatMulImplBase::Run函数
启动多线并行域,计算线程并行调用MatMulImplBase::RunSequential,
2.9. RunSequential函数
RunSequential是单线程内逻辑,根据线程id遍历本线程所分配的batchDims维度,也就是5D tensor的高3维的一部分,依次处理
for (SizeType i0 = 0; i0 < perThreadParams[threadId].broadcastedDims[IDX_0]; ++i0) {
for (SizeType i1 = 0; i1 < perThreadParams[threadId].broadcastedDims[IDX_1]; ++i1) {
for (SizeType i2 = 0; i2 < perThreadParams[threadId].broadcastedDims[IDX_2]; ++i2) {
// 计算src, wei, dst, bias数据指针偏移
// ...
RunSequential2D(threadId, srcPtr, weiPtr, dstPtr, biaExec, buffer, alpha, beta);
}
}
}
2.10. RunSequential2D函数
RunSequential2D函数的主要过程如下,是一个5层循环,外三层依次按块大小遍历M,K,N;内2层遍历分块后的M和N,最终跳转到实例化阶段生成的JIT Code执行。
for (IntType mBlock = 0; mBlock < m; mBlock += CodeGen::GetMBlockSize(m, n, k)) {
for (IntType kBlock = 0; kBlock < k; kBlock += CodeGen::GetKBlockSize(m, n, k)) {
for (IntType nBlock = 0; nBlock < n; nBlock += CodeGen::GetNBlockSize(m, n, k)) {
for (IntType mSubBlock = 0; mSubBlock < mBlockExec; mSubBlock += CodeGen::kernelMSize * vl) {
for (IntType nSubBlock = 0; nSubBlock < nBlockExec; nSubBlock += CodeGen::kernelNSize * vl) {
auto kernel = perThreadImpls[threadId][mIdx * NUM_4 + nIdx * NUM_2 + kIdx].template GetCode<void (*)(const SrcType *, const WeiType *, DstType *, const BiaType *, DstLoadFlags, float)>();
kernel(srcBuffer + mSubBlock * kBlockExec, weiBuffer + nSubBlock * kBlockExec, dstExec, biaExec, biaFlagsExec, beta);
}
}
}
}
}
.templete GetCode会调用CodeGenWrapper类的模板类型MatMulKernelDefaultCodeGen的基类CodeArray的GetCode()函数,返回JIT 代码的入口地址
template <class F>
const F GetCode() const
{
return reinterpret_cast<F>(top_);
}
得到的kernel是个函数指针,指向JIT Code入口地址,kernel只负责计算如下大小的矩阵
nr∗mr∗kc