


使用DevKit-Optimizer定位llama.cpp的伪共享问题
发表于 2026/06/09
0
一、背景
在多线程高并发程序中,缓存一致性开销可能会成为影响程序扩展性的关键因素。现代处理器通常以 cache line 为单位维护缓存一致性,当多个线程分别访问位于同一 cache line 内的不同变量,并且至少存在写操作时,即使这些线程在程序语义上没有访问同一个变量,也可能导致 cache line 在多个 CPU 核之间频繁失效和迁移,这类问题通常称为伪共享(false-sharing)。
llama.cpp 在线程池图计算过程中需要频繁执行 barrier 同步,该伪共享问题修复前, n_barrier、n_barrier_passed 等原子变量在结构体中相邻,容易落入同一个 cache line。多个线程并发更新这些变量时,会导致 cache line 在 CPU 核之间频繁迁移,形成伪共享。
详见:问题issue: https://github.com/ggml-org/llama.cpp/issues/9588 修复PR: https://github.com/ggml-org/llama.cpp/pull/9598
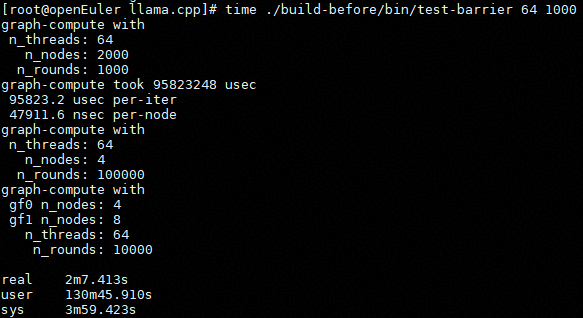
本案例通过DevKit-Optimizer源码优化工具采集,分析定位到 ggml_barrier 路径中的同一 64B cache line访问。通过增加 cache line 对齐隔离这些高频原子变量后,64 线程场景下单轮耗时从约 95823.2 us 降至 20351.1 us,性能提升约 4.71 倍。
二、工具介绍
DevKit-Optimizer源码优化工具是一款在运行C/C++源码时采集性能数据并提供源码优化建议的源码优化工具。该工具能够进行函数级Top-down分析、函数调用链分析和内存分析,帮助开发者梳理业务执行逻辑,快速定位性能瓶颈,提供源码优化建议,从而快速解决业务性能问题,提升开发效率和运维效率。其中,伪共享识别功能仅支持鲲鹏950服务器(支持ARM SPE datasource数据采集)。
命令格式
./devopt.sh [全局选项] <子命令> [子命令选项] [参数]示例1:采集目标进程的基本性能数据
./devopt.sh record -p 12345 -d 30 -f 2000 -o /tmp/optimizer_output上述命令将对 PID 为 12345 的进程进行 30 秒的性能数据采集,采样频率设为 2000 Hz,输出文件保存到 /tmp/optimizer_output 目录。
示例2:精细化内存采集(伪共享检测)
./devopt.sh record -p 12345 -m -i input_file.rawdata上述命令将基于已有的采集数据文件进行精细化内存分析,检测可能存在的伪共享问题。
三、案例:llama.cpp调优
llama.cpp项目地址: https://github.com/ggml-org/llama.cpp
3.1 部署和运行
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp为复现伪共享问题,修改代码:ggml/src/ggml.c

执行命令:
sed -i -E '/atomic_int[[:space:]]+GGML_CACHE_ALIGN[[:space:]]+(n_barrier|n_barrier_passed|current_chunk)/s/[[:space:]]+GGML_CACHE_ALIGN//' ggml/src/ggml-cpu/ggml-cpu.c去掉cache line对齐:

执行带符号信息编译,取消内联:
cmake -B build-before -DCMAKE_BUILD_TYPE=RelWithDebInfo -DCMAKE_EXPORT_COMPILE_COMMANDS=ON -DGGML_OPENMP=OFF -DLLAMA_BUILD_TESTS=ON -DCMAKE_C_FLAGS_RELWITHDEBINFO="-O2 -g3 -ggdb -fno-inline" -DCMAKE_CXX_FLAGS_RELWITHDEBINFO="-O2 -g3 -ggdb -fno-inline"构建tests:
cmake --build build-before --target test-barrier -j运行:
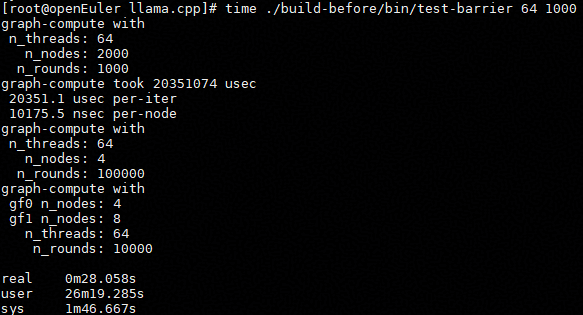
./build-before/bin/test-barrier 64 1000此时,运行结果如下:
3.2 工具采集与分析
3.2.1基础数据采集命令
./devopt.sh -d 1 -p 1370101生成rawdata文件,执行分析基础数据的命令:
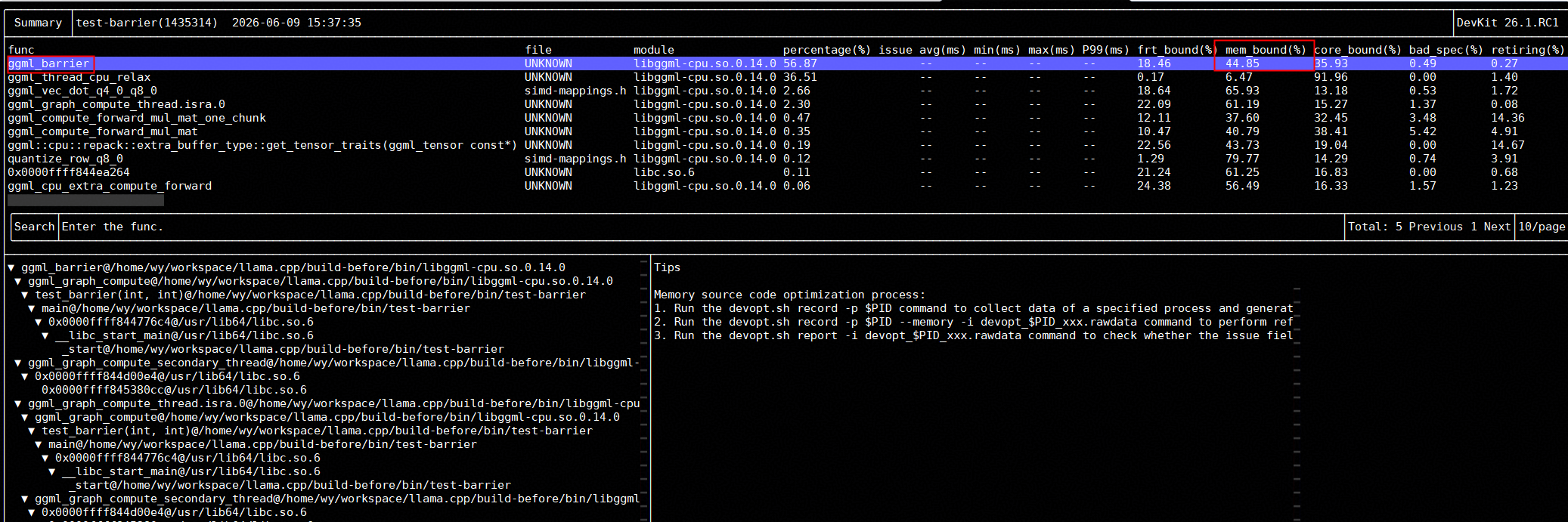
./devopt.sh report -i devopt_1370101_20260609143723.rawdata可以看到,ggml_barrier的mem_bound很高
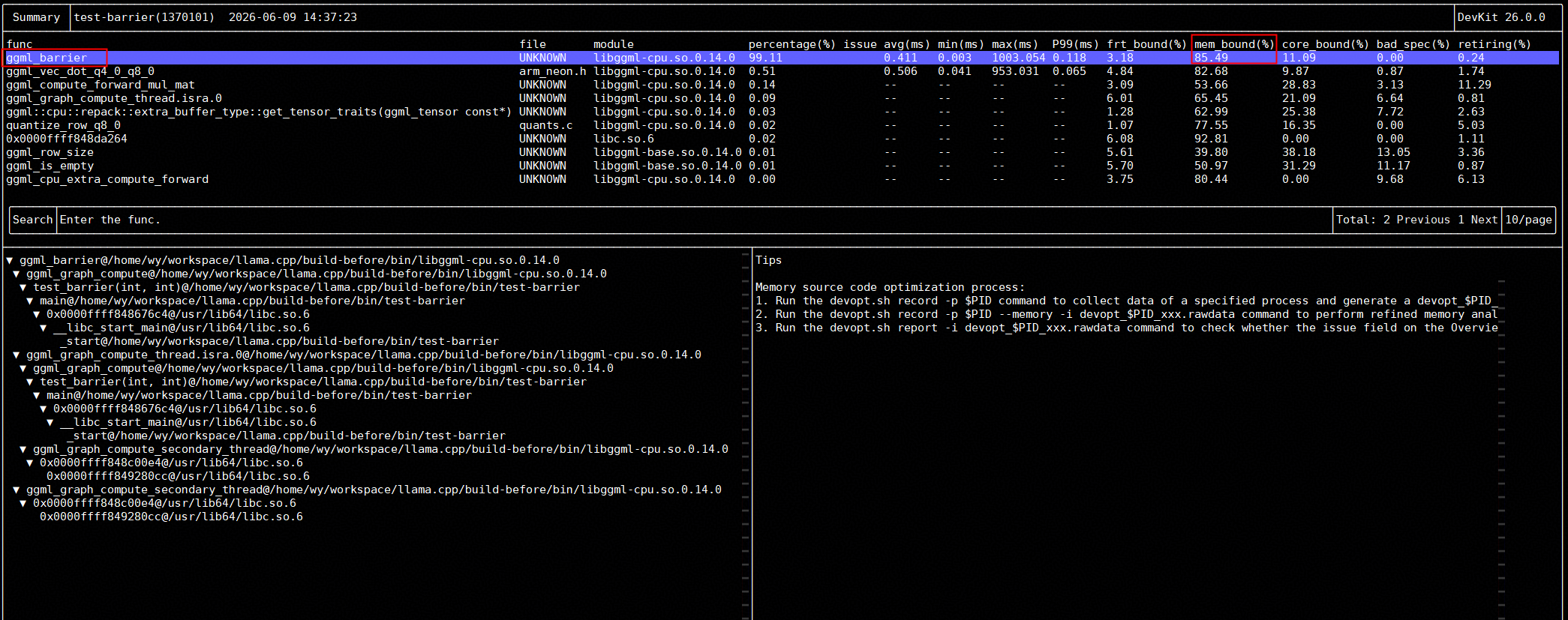
参考Tips提示信息,进行下一步细粒度memory分析。
3.2.2 执行伪共享分析采集命令
指定上一步生成的rawdata文件:
./devopt.sh -d 1 -p 1370101 -m -i devopt_1370101_20260609143723.rawdata由于ggml_barrier对应file为UNKNOWN,无法获知源码信息,执行script命令查看伪共享对结果:
./devopt.sh script -t memory -i devopt_1370101_20260609143723.rawdata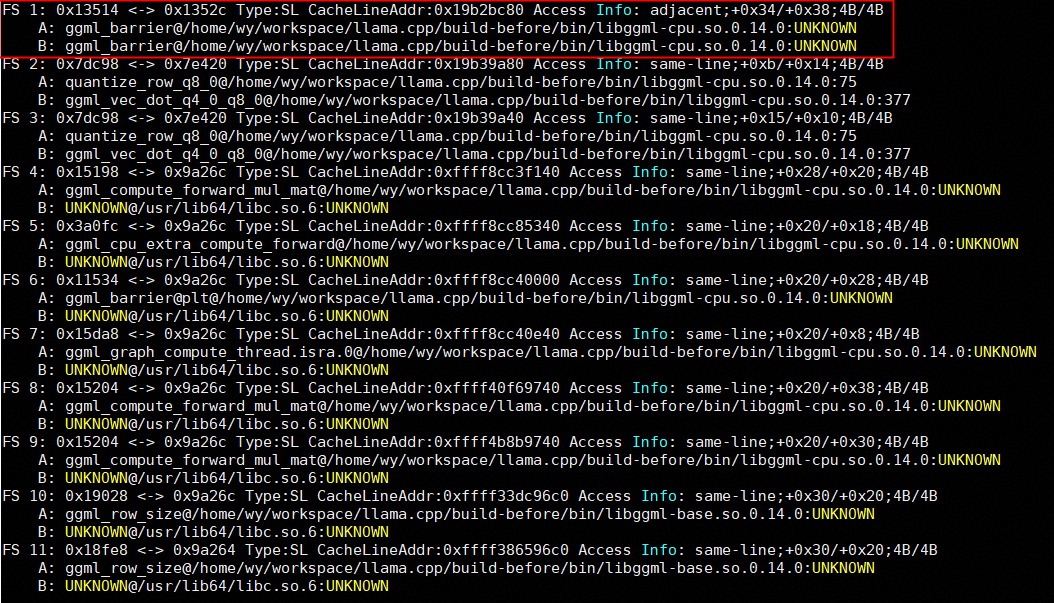
重点分析第一条伪共享对,对应ggml_barrier。
1)此处源码信息为UNKNOWN,执行addrline查看PC对应源码
lib=/home/wy/workspace/llama.cpp/build-before/bin/libggml-cpu.so.0.14.0
addr2line -e "$lib" -a -f -C -i 0x13514 0x1352c
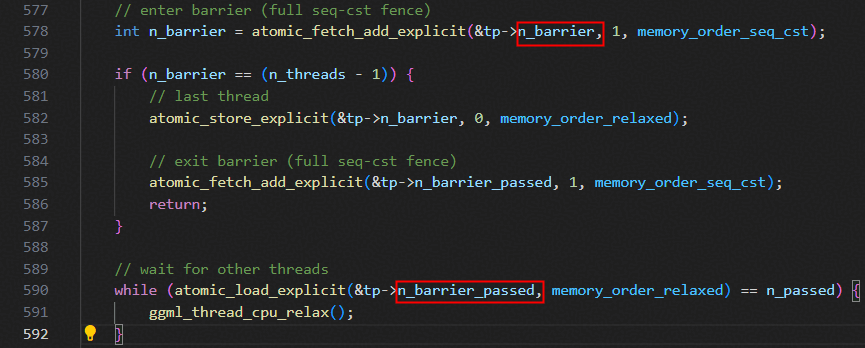
对应源码如下:问题修复前 ggml_threadpool 结构体中 n_barrier 和 n_barrier_passed 两个 atomic_int 字段连续定义,未进行 cache line 对齐隔离。
line578:访问的是 tp->n_barrier
line590:访问的是 tp->n_barrier_passed
2)用gdb验证字段地址
gdb --args ./build-before/bin/test-barrier 64 10执行下列命令:
break ggml_barrier
run
p/x tp
p/x &tp->n_barrier
p/x &tp->n_barrier_passed
p/x &tp->current_chunk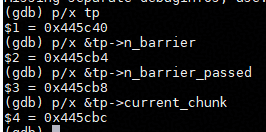
n_barrier cacheline的基址:0x445cb4 & ~0x3f = 0x445c80,偏移:0x445cb4 & 0x3f = 0x34;
n_barrier_passed cacheline的基址:0x445cb8 & ~0x3f = 0x445c80,偏移:0x445cb8 & 0x3f = 0x38
gdb 验证表明, n_barrier 和 n_barrier_passed 位于同一个 64B cache line,分别对应这0x34和0x38这两个偏移(与工具Access Info信息一致)。由于多个线程会频繁更新 n_barrier 并轮询 n_barrier_passed,二者共享 cache line 会产生伪共享,放大 barrier 同步开销。
注:工具中的 CacheLineAddr:0x19b2bc80 和 gdb 中的 0x445b80 不一定相同,因为它们通常来自不同运行进程,受 ASLR、堆地址分配影响
3.3 问题修复
执行命令,添加cache line对齐:
sed -i -E '/atomic_int[[:space:]]+(n_barrier|n_barrier_passed|current_chunk)/{/GGML_CACHE_ALIGN/!s/atomic_int[[:space:]]+/atomic_int GGML_CACHE_ALIGN /}' ggml/src/ggml-cpu/ggml-cpu.c重新编译后,运行结果如下:
此时使用工具再次采集,可以看到ggml_barrier的mem_bound已显著下降
性能数据对比:
| 状态 | n_threads | n_nodes | n_rounds | 总耗时 | per_iter | per_node |
|---|---|---|---|---|---|---|
| 修复伪共享前 | 64 | 2000 | 1000 | 95823248us | 95823.2us | 47911.6ns |
| 修复伪共享后 | 64 | 2000 | 1000 | 20351074us | 20351.1us | 10175.5ns |
修改前 per-iter: 95823.2 us,修改后 per-iter: 20351.1 us,性能提升约 4.71 倍,耗时降低约 78.8%。整体 real 时间也从 2m7.413s 降低到 28.058s,说明 cache line 对齐优化显著降低了多线程同步路径中的伪共享开销。
四、总结
本案例使用DevKit-Optimizer源码优化工具定位 llama.cpp test-barrier场景中的伪共享问题。工具报告ggml_barrier中存在同 cache line 相邻访问,随后结合源码和gdb对 ggml_threadpool 结构体字段地址进行验证,确认 n_barrier 和 n_barrier_passed 两个高频原子变量位于同一 64B cache line 内。针对该问题,对相关字段增加 GGML_CACHE_ALIGN,将同步变量隔离到不同 cache line,从而降低了多线程 barrier 阶段的缓存一致性开销。