


大数据日志分析工具OmniHelper的实践案例
发表于 2026/06/12
0
1 背景
随着某公司实时计算平台升级,公司计划将线上的 Flink 作业逐步迁移至自研的 OmniStream 引擎。OmniStream 在性能、资源弹性和运维体验上均有显著提升,但与原生 Flink 存在一定的语法和语义差异。然而,当前在实际运维中面临以下突出挑战:
第一,传统的评估方式存在明显短板只能通过静态扫描或人工review sql语句去识别不兼容的算子、表达式和内置函数。
第二,我们不仅需要知道“用了哪些不兼容的算子/函数”,更需要知道“这些不兼容元素在真实负载下的影响有多大” —— 一个低频调用的小函数,和每秒执行百万次的热点算子,改造紧迫性完全不同。
于是我们开发了Omnihelper支持对用户Flink上的历史任务进行分析并且支持输出含有Omni不支持的算子/表达式/内置函数的报告。能够清晰的识别哪些算子/表达式/内置函数需要改造。明确哪些算子/表达式/内置函数出现频次高优先级高。
2 工具介绍及获取方式
工具简介:
OmniHelper是专为大数据平台设计的日志分析工具,旨在帮助开发者和运维人员高效分析执行日志中的算子、表达式和函数使用情况。该工具作为Omni生态的配套组件,能够识别原生算子与Omni算子的混合执行情况,分析相关参数类型,识别不支持的算子/表达式/函数并生成结构化的分析报告,为性能优化提供数据支持。
工具获取:
https://gitcode.com/openeuler/OmniAdaptor
使用文档:
https://gitcode.com/openeuler/OmniAdaptor/blob/master/omnihelper/README.md
3 使用效果
3.1 环境部署
python环境要求:
- Python >= 3.9
- 依赖项:tqdm、numpy、pandas、openpyxl、requests
- 可选依赖:requests-kerberos(启用Kerberos认证时需要)
Flink日志分析环境要求:
- 确保Flink集群已启动并可访问REST API。
- 确保Flink Dashboard URL可访问(默认:http://localhost:8081)。
- 如果使用Kerberos认证,确保已安装并配置Kerberos相关依赖:pip install requests-kerberos
3.2 工具使用方法
- 解压BoostKit-omniruntime-omnihelper-*.zip文件:unzip BoostKit-omniruntime-omnihelper-*.zip
- 进入解压后的文件夹,解压对应压缩包。
- Arm架构:tar -zxvf omnihelper_release_arm.tar.gz x86架构:tar -zxvf omnihelper_release_x86.tar.gz
我们以Arm架构为例最终会在目录汇总生成omnihelper相关的内容:
为了提升类型识别的准确性,需导出Flink表结构至resources/flink_table_schema.csv,文件需包含三列:table_name(表名)、field_name(列名)、field_type(数据类型)。含逗号的类型需用双引号包裹。
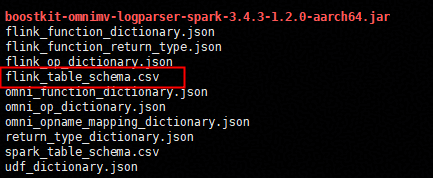
表结构导出示例: 示例中数据表、字段,以及字段类型是nexmark的部分数据,根据实际的SQL内容填充。
table_name,field_name,field_type
datagen,event_type,int
datagen,person,"ROW<id BIGINT, name VARCHAR, emailAddress VARCHAR, city VARCHAR>"
datagen,auction,"ROW<id BIGINT, itemName VARCHAR, initialBid BIGINT, dateTime TIMESTAMP(3)>"
datagen,bid,"ROW<auction BIGINT,bidder BIGINT,price BIGINT,dateTime TIMESTAMP(3)>"字段说明: table_name为表名;field_name为列名;field_type为数据类型,支持基础类型和复杂类型。
复杂类型说明:
ROW 类型表示嵌套结构(子表)。 例如:
datagen,auction,"ROW<id BIGINT,itemName VARCHAR>"完成resources/flink_table_schema.csv的编写后执行flink命令:
omnihelper flink [-h] --url URL [--jobid JOBID [JOBID ...]] [--input_data INPUT_DATA]
[--interval INTERVAL] [--timeout TIMEOUT] [--output_dir OUTPUT_DIR]
[--show-op-details] 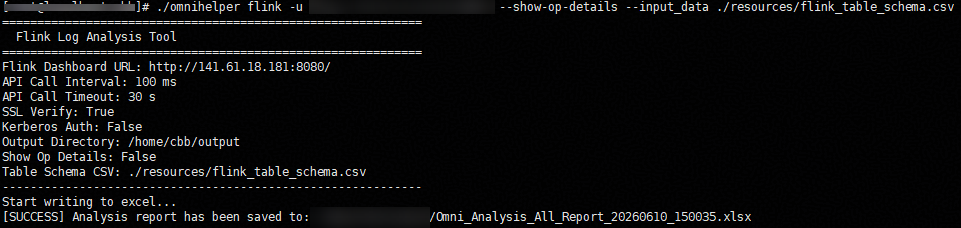
Flink分析模式参数说明
表1 Flink基础参数
| 参数 | 简写 | 是否必选 | 说明 |
|---|---|---|---|
| --help | -h | 否 | 查看帮助信息. |
| --url | -u | 是 | Flink Dashboard URL,例如:http://127.0.0.1:8081 或 https://127.0.0.1:8081。 |
| --jobid | -j | 否 | Flink作业ID。支持多个作业ID,用空格分隔。如果不提供,将尝试从API获取。 |
| --input_data | 无 | 否 | 输入字段和类型的映射文件路径,CSV格式。CSV文件应包含table_name、field_name和field_type列。 |
| --output_dir | -o | 否 | 输出目录。 默认值: ./output。 |
| --show-op-details | -s | 否 | 隐藏算子文件大小、输出行数信息。 |
| --interval | -i | 否 | API调用间隔(毫秒)。 默认值:100。 |
| --timeout | -t | 否 | API调用超时时间(秒)。 默认值:30。 |
打开生成的日志报告会有如下属性:


通过高效分析执行日志中的算子、表达式、函数使用情况,识别不支持的算子、表达式、函数并生成结构化的分析报告,为性能优化提供数据支持。
4 总结
通过分析 Flink EventLog 中的实际执行指标,OmniHelper 能够精准识别不兼容的算子、表达式、函数和数据类型;关联执行频次、耗时、数据量,量化改造优先级;输出结构化 Excel 报告,支撑迁移决策与排期