


图像识别场景调优报告
发表于 2026/06/12
0
1 调优背景
图像识别项目在鲲鹏迁移替换后,性能劣化严重,具体来说,其中某个向量化计算benchmark当前鲲鹏机型运行时长为20398(920新型号)< 38232(920),期望920新型号运行时长达到17000,急需通过调优释放鲲鹏服务器潜力
2 测试环境
机型:920新型号,256核心(开启超线程),共4个numa,总内存470G,
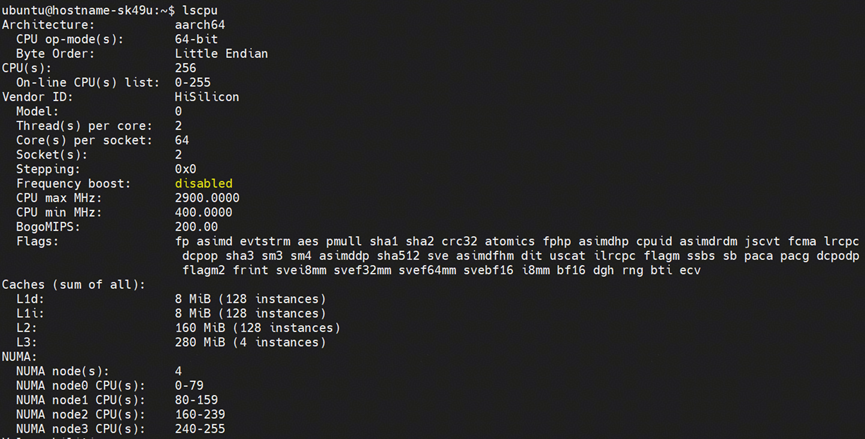
测试条件:
在docker内部测试,测试前保证环境空载,仅使用10个工作线程,引入环境变量如下:
OMP_THREAD_LIMIT=10
OMP_NUM_THREADS=1
OMP_WAIT_POLICY=PASSIVE
OPENBLAS_NUM_THREADS=1
MKL_DYNAMIC=FALSE
KMP_BLOCKTIME=0
3 负载分析
3.1 benchmark代码分析
根据对benchmark代码进行详细解读分析,发现以下特征:
1、代码逻辑为使用faiss根据向量化内积计算相似度,几乎纯吃cpu计算和内存资源,
2、性能指标为所有线程的总运行时长(总计算量固定的情况下可以近似看作为单线程的计算时间)
3、当前benchmark配置中固定了线程池大小为100
3.2 特征分析及优化方向初探
根据3.1中所提到特征,怀疑可能的调优方向如下:
1、 faiss数据库并未做arm上的特殊适配,可以通过向量化替换改造开源faiss以及其三方库openBLAS,充分发挥鲲鹏向量化能力
2、 由于近似看做单线程的计算时间,所以当前benchmark测试方向为单核性能,而鲲鹏服务器在多核计算场景下更具优势,所以本测试场景对鲲鹏服务器并不友好,可以尝试关闭超线程等手段进一步提升单核性能
3、 当前OMP工作线程仅为10,而上层设置线程池数量远大于10,会导致线程切换、系统资源使用不平衡等问题,可以将线程池大小设置为与OMP 工作线程数相同。
4 测试基线
使用faiss(1.5.3)+ openBLAS(0.3.8),使用章节二中的环境变量测试得到的性能指标为22113
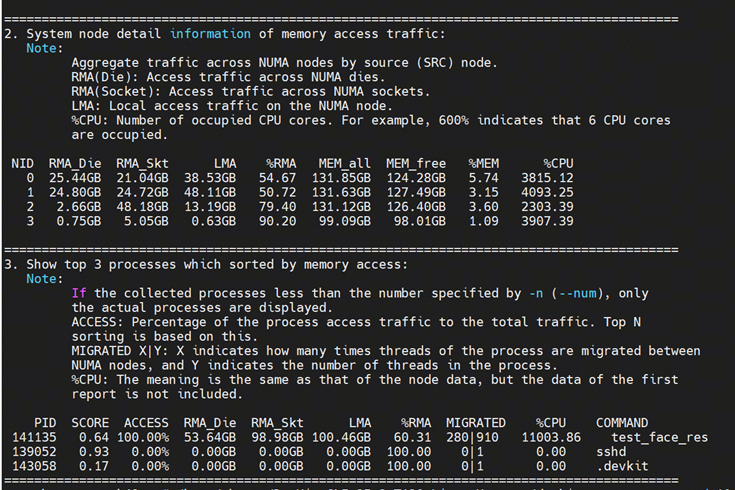
测试过程中通过DevKit tuner/ksys采集的关键性能指标为:
numa:
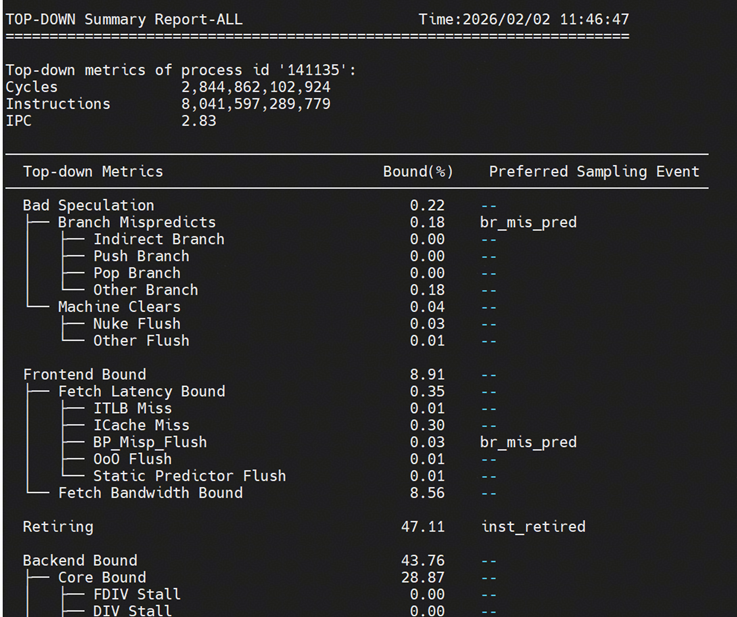
topdown:
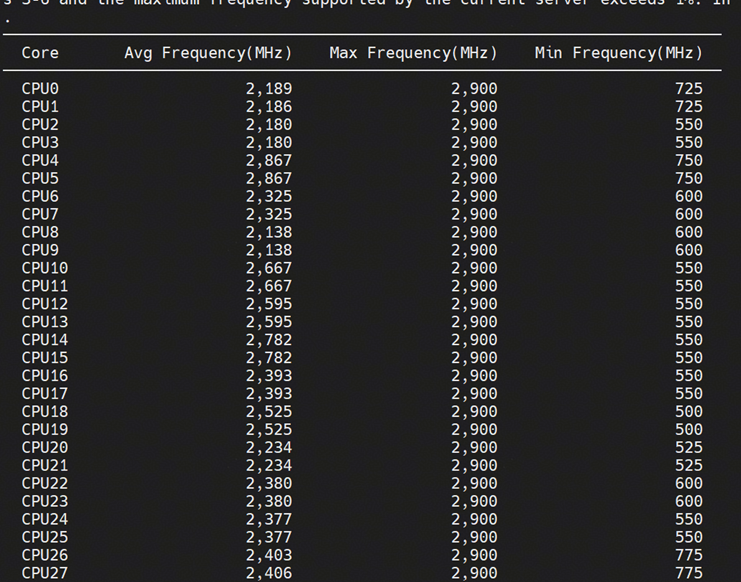
频率:
指令:
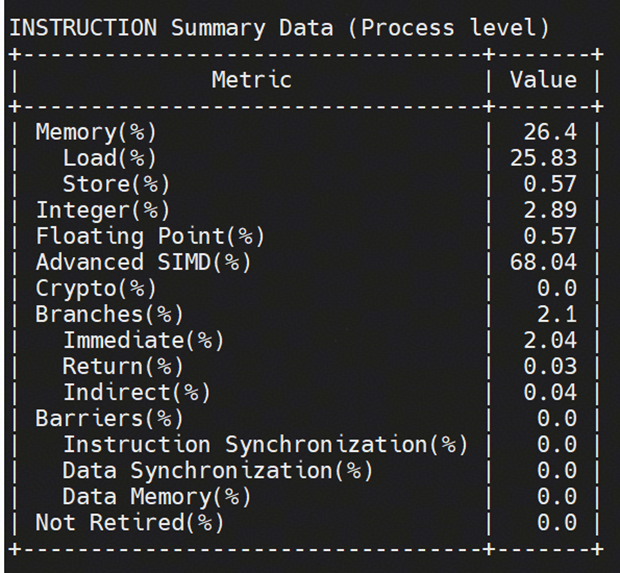
可以明显发现:
1、 存在较大的跨numa流量访问的情况,可以后续通过绑核优化
2、 由于先验在920测试所得的SIMD占比(14%),而920新型号上该项占比达到68%,提升非常明显,怀疑可能是openBLAS中使用了较多sve指令的优化,也进一步印证了现场测试过程中38232(920)远大于20398(920新型号)
3、 CPU频率存在明显减低,当前频率模式为ondemand,后续可以通过使用性能模式稳定频率
4、 由于benchmark场景比较固定,当前IPC已处于较高水平
5 调优过程
5.1 向量化替换改造
通过对faiss进行向量化改造,并升级openBLAS到0.3.31版本,其他测试条件不变,得到性能指标为20124
测试过程中通过DevKit tuner/ksys采集的关键性能指标为:
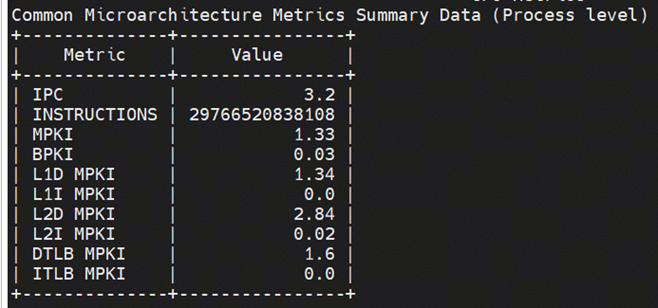
topdown:
指令:
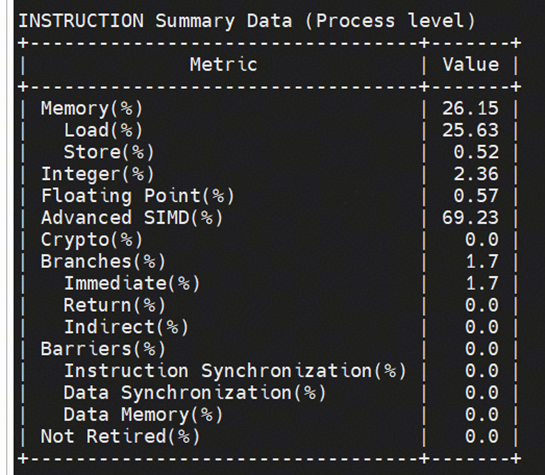
根据上述数据分析得到
1、IPC相较于基线有进一步提升,验证了向量化改造的效果
2、SIMD指令从68% -> 69%,提升比例不大,进一步采集hotspot,发现所改造的faiss向量化指令并不在热点中,热点中占比最高的部分均在openblas的汇编模块,faiss所占比例较小,且经过源码查看,该部分并不能进行向量化改造。
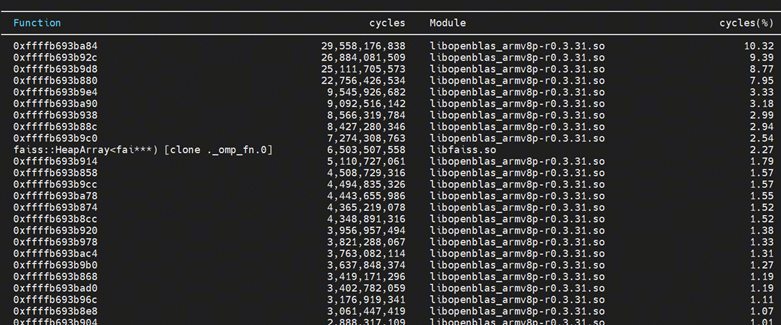
5.2 线程池调整+绑核
在5.1的基础上,设置线程池大小为10,并通过numactl -C 2,4,6,8,10,12,14,16,18,20,22绑11个核(主线程和线程池内10个线程) ,偶数绑核是考虑在SMT开启情况下,充分使用物理核;最后得到性能指标为17474
测试过程中通过DevKit tuner/ksys采集的关键性能指标为:
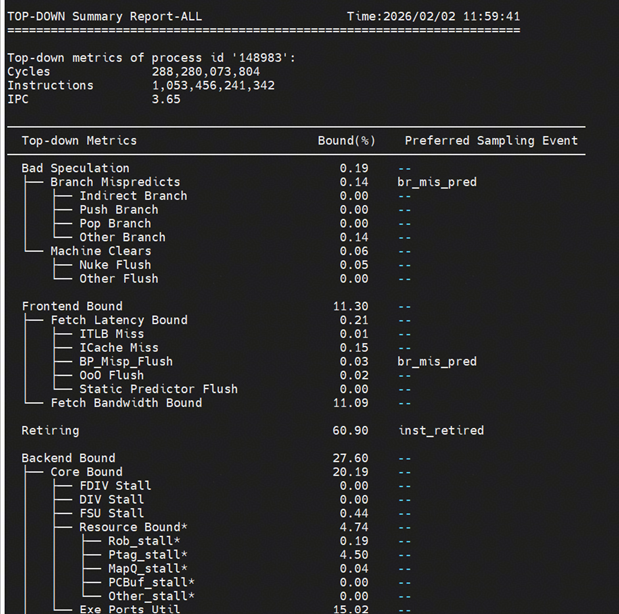
numa:
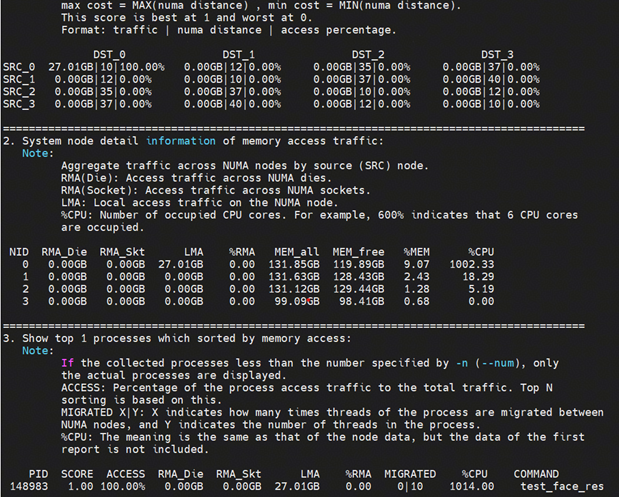
可以看到IPC已达到3.65,处于特别高的水平,说明此时程序指令执行效率高,且无跨numa流量
5.3 开启CPU频率性能模式
在5.2的基础上,把cpu频率均设置为性能模式,最终测试得到性能指标为16633,已满足调优诉求
echo performance > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor

复测一次后,结果为17054,取两者平均为16844
5.4 关闭超线程
考虑到主要测试对象为单核性能,因此在BMC中尝试关闭超线程后测试,在5.3的基础上,最终测试得到性能指标为18383,性能发生劣化,舍弃
5.5 调优手段汇总
考虑到上述手段在调优过程中存在交叉使用的情况,为了方便评估每项调优手段的影响,将每种调优手段独立应用进行调优,且为保证测试结果所得结果如下所示:
性能指标(基线22113) | 相对基线提升比例 | |
向量化替换faiss | 22055 | 0.3% |
openBLAS升级 | 20124 | 9.0% |
线程池设置为10 | 18096 | 18.2% |
设置cpu频率性能模式 | 20831 | 5.8% |
绑核(线程池100,绑numa 0,1) | 22652 | -2.4% |
绑核(线程池10,偶数绑核) | 17865 | 19.2% |
关闭超线程 | 20350 | 8.0% |
向量化替换faiss+openBLAS升级+线程池替换+绑核 | 17474 | 21.0% |
向量化替换faiss+openBLAS升级+线程池替换+绑核+ cpu频率性能模式 | 16844 | 23.8% |
6 测试结论
通过向量化替换faiss+openBLAS升级+线程池替换+绑核+ 设置cpu频率性能模式,在本地测试中,调优后的性能指标最终为16844,相比本地基线(22113)提升23.8%,相比现场测试基线(20398)提升18.5%,基本满足调优诉求