


鲲鹏计算平台矩阵乘算子SGEMM优化实践——上篇
发表于 2026/06/18
0
鲲鹏计算平台矩阵乘算子SGEMM优化实践分为上下两篇,记录了在鲲鹏计算平台上,从最朴素的三重循环矩阵乘法出发,经过 6 个阶段逐步优化,最终实现 30+倍性能提升 的完整过程。所有代码基于 C 语言 + ARM intrinsics,矩阵存储采用列主序 (Column-Major),编译器使用华为毕昇编译器 (BiSheng)。
1. 背景知识:矩阵乘法的计算本质
在深入优化之前,我们先理解 SGEMM 的计算特征。对于 C = A × B,其中 A 为 M×K、B 为 K×N、C 为 M×N:
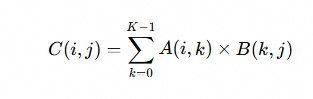
关键数据:矩阵 512×512 时,总浮点运算量 = 2 × M × N × K = 2 × 512³ ≈ 0.268 GFLOP。
核心矛盾:矩阵乘法的算术强度(FLOP/Byte)理论上很高,但实际实现中往往受限于内存带宽。优化的核心就是让计算单元"吃饱"——减少等待数据的时间。
访存模式分析
列主序存储下,矩阵 A 的元素 A[i + k*M] 在内存中的布局为:
A 的内存布局 (列主序, M=8 为例):
地址: 0 1 2 3 4 5 6 7 | 8 9 10 11 ...
元素: A00 A10 A20 A30 A40 A50 A60 A70|A01 A11 A21 A31 ...
└────────── 第0列 ──────────┘ └── 第1列 ──┘
内层循环 k++ 时,访问 A[i + k*M] 的步长为 M——每次跳过一整列。当 M=512 时,步长 512×4=2048 字节,远超缓存行大小(64 字节),每次访问几乎都是 cache miss。
这就是朴素实现的根本问题:计算密度极低,大部分时间在等内存。
2. sgemm实现之朴素实现
最直观的三重循环,没有任何优化:
void sgemm_naive(int M, int N, int K, const float *A, const float *B, float *C) {
for (int j = 0; j < N; j++) {
for (int i = 0; i < M; i++) {
float sum = 0.0f;
for (int k = 0; k < K; k++) {
sum += A[i + k * M] * B[k + j * K];
}
C[i + j * M] = sum;
}
}
}
瓶颈分析
让我们逐条分析内层循环的访存行为:
| 操作 | 地址模式 | 步长 | 缓存行为 |
|---|---|---|---|
| 读 A[i + k*M] | stride=M | 2048B | 几乎每次 cache miss |
| 读 B[k + j*K] | stride=1 | 连续 | 良好,预取有效 |
| 写 C[i + j*M] | 只写1次 | - | 无影响 |
| 浮点运算 | 1乘+1加 | - | 仅 2 FLOP |
算术强度:每次迭代 2 FLOP,需要加载 A 的 1 个 float(4B)+ B 的 1 个 float(4B)= 8 字节。算术强度 = 2/8 = 0.25 FLOP/Byte,严重受限于内存带宽。
循环开销:每次 K 迭代还有比较(k < K)、自增(k++)、分支跳转等开销,与 2 FLOP 的有效计算相比占比极高。
编译器为何不能自动优化:虽然 K 循环在数学上无依赖,但编译器的别名分析(alias analysis)无法确定 A、B、C 不会重叠,因此不敢激进地向量化。
3. sgemm实现之循环展开
3.1. 优化思路
朴素实现的核心问题有两个:
- B 的复用不足:内层循环中
B[k + j*K]对同一行的所有 i 值相同,但朴素实现每个 i 都重新加载 - 指令级并行(ILP)不足:单个累加器
sum形成串行依赖链,无法利用 CPU 的多发射能力
解决方案:将 i 维度按 4 行展开,让 4 个输出共享 B 的加载;将 K 维度展开 16 步,暴露大量独立操作。
#define UNROLL_K4_ROWS(kk) \
c0 += A[i+0+(kk)*M] * B[(kk)+j*K]; \
c1 += A[i+1+(kk)*M] * B[(kk)+j*K]; \
c2 += A[i+2+(kk)*M] * B[(kk)+j*K]; \
c3 += A[i+3+(kk)*M] * B[(kk)+j*K];
void sgemm_unroll(int M, int N, int K, const float *A, const float *B, float *C) {
for (int j = 0; j < N; j++) {
int i = 0;
for (; i + 3 < M; i += 4) {
float c0 = 0, c1 = 0, c2 = 0, c3 = 0;
int k = 0;
for (; k + 15 < K; k += 16) {
UNROLL_K4_ROWS(k+0) UNROLL_K4_ROWS(k+1) UNROLL_K4_ROWS(k+2) UNROLL_K4_ROWS(k+3)
UNROLL_K4_ROWS(k+4) UNROLL_K4_ROWS(k+5) UNROLL_K4_ROWS(k+6) UNROLL_K4_ROWS(k+7)
UNROLL_K4_ROWS(k+8) UNROLL_K4_ROWS(k+9) UNROLL_K4_ROWS(k+10) UNROLL_K4_ROWS(k+11)
UNROLL_K4_ROWS(k+12) UNROLL_K4_ROWS(k+13) UNROLL_K4_ROWS(k+14) UNROLL_K4_ROWS(k+15)
}
for (; k + 7 < K; k += 8) {
UNROLL_K4_ROWS(k+0) UNROLL_K4_ROWS(k+1) UNROLL_K4_ROWS(k+2) UNROLL_K4_ROWS(k+3)
UNROLL_K4_ROWS(k+4) UNROLL_K4_ROWS(k+5) UNROLL_K4_ROWS(k+6) UNROLL_K4_ROWS(k+7)
}
for (; k + 3 < K; k += 4) {
UNROLL_K4_ROWS(k+0) UNROLL_K4_ROWS(k+1) UNROLL_K4_ROWS(k+2) UNROLL_K4_ROWS(k+3)
}
for (; k < K; k++) {
float bval = B[k + j * K];
c0 += A[i+0 + k*M] * bval;
c1 += A[i+1 + k*M] * bval;
c2 += A[i+2 + k*M] * bval;
c3 += A[i+3 + k*M] * bval;
}
C[i+0 + j*M] = c0;
C[i+1 + j*M] = c1;
C[i+2 + j*M] = c2;
C[i+3 + j*M] = c3;
}
for (; i < M; i++) {
float sum = 0;
for (int k = 0; k < K; k++) {
sum += A[i + k*M] * B[k + j*K];
}
C[i + j*M] = sum;
}
}
}
实测性能提升2.3×倍
3.2. 加速 2.3x倍的原因分析
1) B 的复用(4× 减少 B 加载)
朴素实现 (每个 i 独立): 展开后 (4 行共享 B):
i=0: load B[k], load A[0,k] i=0..3: load B[k] 一次
i=1: load B[k], load A[1,k] load A[0,k], A[1,k], A[2,k], A[3,k]
i=2: load B[k], load A[2,k] B 只加载 1 次,被 4 次乘法复用
i=3: load B[k], load A[3,k]
4 次迭代中,B 的加载从 4 次减少到 1 次,内存请求减少 37.5%(4A+4B → 4A+1B)。
2) 独立累加器打破依赖链
朴素: sum → fma → sum → fma → sum → ... (串行依赖链,无法并行)
展开: c0 → fma → c0 → ... (4 条独立链)
c1 → fma → c1 → ...
c2 → fma → c2 → ...
c3 → fma → c3 → ...
CPU 的乱序执行引擎可以同时发射多条独立 FMA,掩盖延迟。
3) K 展开 16 减少循环开销
每次 K 循环迭代从 2 FLOP + 循环开销,变为 32 FLOP(4行×8乘加)+ 极少的循环开销。分支预测压力大幅降低。
4) 尾部处理策略
K=512 恰好被 16 整除,但通用实现需要处理任意 K。我们采用分级尾部处理:先尝试 8,再 4,最后 1。这比逐个处理减少了分支次数。
3.3. 仍然存在的瓶颈
- 仍然是标量运算:4 个独立累加器 c0~c3 各自只能用标量 FMA,未利用 512-bit SVE 硬件
- A 的跨步访问未改善:
A[i + k*M]仍然是 stride=M 的非连续访问 - 寄存器压力:K 展开 16 时,4×16=64 个中间结果需要寄存器,可能溢出到栈
4. sgemm实现之NEON向量化
4.1. 优化思路
循环展开的 4 行展开恰好与 NEON 的 128-bit 向量宽度(4 个 float)匹配。与其用 4 个标量累加器 c0, c1, c2, c3,不如用一个 128-bit 向量累加器 float32x4_t,一条指令同时完成 4 个乘加。
关键转变:从"4 行各自标量计算"变为"1 个向量同时计算 4 行"。
void sgemm_neon(int M, int N, int K, const float *A, const float *B, float *C) {
for (int j = 0; j < N; j++) {
int i = 0;
for (; i + 3 < M; i += 4) {
float32x4_t c0 = vdupq_n_f32(0.0f);
float32x4_t c1 = vdupq_n_f32(0.0f);
float32x4_t c2 = vdupq_n_f32(0.0f);
float32x4_t c3 = vdupq_n_f32(0.0f);
int k = 0;
for (; k + 3 < K; k += 4) {
float32x4_t b0 = vdupq_n_f32(B[(k+0) + j*K]);
float32x4_t a0 = vld1q_f32(&A[i + (k+0)*M]);
c0 = vfmaq_f32(c0, a0, b0);
float32x4_t b1 = vdupq_n_f32(B[(k+1) + j*K]);
float32x4_t a1 = vld1q_f32(&A[i + (k+1)*M]);
c1 = vfmaq_f32(c1, a1, b1);
float32x4_t b2 = vdupq_n_f32(B[(k+2) + j*K]);
float32x4_t a2 = vld1q_f32(&A[i + (k+2)*M]);
c2 = vfmaq_f32(c2, a2, b2);
float32x4_t b3 = vdupq_n_f32(B[(k+3) + j*K]);
float32x4_t a3 = vld1q_f32(&A[i + (k+3)*M]);
c3 = vfmaq_f32(c3, a3, b3);
}
float32x4_t c_sum = vaddq_f32(vaddq_f32(c0, c1), vaddq_f32(c2, c3));
for (; k < K; k++) {
float32x4_t a_vec = vld1q_f32(&A[i + k*M]);
float32x4_t b_vec = vdupq_n_f32(B[k + j*K]);
c_sum = vfmaq_f32(c_sum, a_vec, b_vec);
}
vst1q_f32(&C[i + j*M], c_sum);
}
for (; i < M; i++) {
float sum = 0;
for (int k = 0; k < K; k++) {
sum += A[i + k*M] * B[k + j*K];
}
C[i + j*M] = sum;
}
}
}性能:2.79 GFLOPS(性能提升2.5×倍)
实测性能提升2.5x倍
4.2. 深入分析:Neon向量化性能提升有限
相比循环展开的实现方式仅有1.06 倍提升,具体原因:
1) 毕昇编译器的自动向量化
毕昇编译器(clang 19)在 -O3 下已经对循环展开代码做了自动向量化。编译器识别到 4 个独立累加器 c0~c3 对 A 的连续访问模式,自动将其转化为 NEON 指令。因此手写 NEON 与编译器自动向量化的效果接近。
2) A 的跨步访问仍然是瓶颈
vld1q_f32(&A[i + k*M]) 加载 A[i+0], A[i+1], A[i+2], A[i+3]
↑ 它们在内存中连续(同一列的相邻行)
但 k+1 时跳到 A[i + (k+1)*M],步长 = M × 4B = 2KB
虽然 vld1q_f32 一次加载 4 个连续 float,但不同 k 之间仍然是大步长跳跃,缓存行无法复用。
3) NEON 的 4-lane 宽度太窄
128-bit = 4 个 float,每条 vfmaq_f32 仅完成 4 次乘加 = 8 FLOP。要充分利用 CPU 的 FMA 吞吐,需要更多并行。
4.3. NEON 微内核的计算密度
每个 K 迭代(4 步展开):
- 加载:4 次
vld1q_f32(A)+ 4 次vdupq_n_f32(B)= 8 次向量操作 - 计算:4 次
vfmaq_f32= 16 FLOP - 计算/加载比 = 16 FLOP / 8 ops = 2.0,仍然偏低
5. sgemm实现之SVE 向量化
5.1. 优化思路
SVE 与 NEON 的本质区别:
| 特性 | NEON | SVE |
|---|---|---|
| 向量宽度 | 固定 128-bit | 可变 128~2048-bit(本平台 512-bit) |
| 边界处理 | 需要标量尾部循环 | 谓词寄存器自动处理 |
| 编程模型 | 固定 4/2 float | 长度无关(写一次,到处跑) |
| 每条 FMA 的 FLOP | 8 (4×乘加) | 32 (16×乘加) |
SVE 的宽度意味着每条 svmla_f32_m 指令同时完成 16 个 float 的乘加,是 NEON 的 4 倍。
void sgemm_sve(int M, int N, int K, const float *A, const float *B, float *C) {
int64_t vl = svcntw(); // 运行时获取向量长度
for (int j = 0; j < N; j++) {
for (int i = 0; i < M; i += vl) {
svbool_t pg = svwhilelt_b32((int64_t)i, (int64_t)M);
svfloat32_t c0 = svdup_n_f32(0.0f);
svfloat32_t c1 = svdup_n_f32(0.0f);
svfloat32_t c2 = svdup_n_f32(0.0f);
svfloat32_t c3 = svdup_n_f32(0.0f);
int k = 0;
for (; k + 3 < K; k += 4) {
svfloat32_t a0 = svld1_f32(pg, &A[i + (k+0)*M]);
svfloat32_t b0 = svdup_n_f32(B[(k+0) + j*K]);
c0 = svmla_f32_m(pg, c0, a0, b0);
svfloat32_t a1 = svld1_f32(pg, &A[i + (k+1)*M]);
svfloat32_t b1 = svdup_n_f32(B[(k+1) + j*K]);
c1 = svmla_f32_m(pg, c1, a1, b1);
svfloat32_t a2 = svld1_f32(pg, &A[i + (k+2)*M]);
svfloat32_t b2 = svdup_n_f32(B[(k+2) + j*K]);
c2 = svmla_f32_m(pg, c2, a2, b2);
svfloat32_t a3 = svld1_f32(pg, &A[i + (k+3)*M]);
svfloat32_t b3 = svdup_n_f32(B[(k+3) + j*K]);
c3 = svmla_f32_m(pg, c3, a3, b3);
}
svfloat32_t c_sum = svadd_f32_m(pg, svadd_f32_m(pg, c0, c1),
svadd_f32_m(pg, c2, c3));
for (; k < K; k++) {
svfloat32_t a_vec = svld1_f32(pg, &A[i + k*M]);
svfloat32_t b_vec = svdup_n_f32(B[k + j*K]);
c_sum = svmla_f32_m(pg, c_sum, a_vec, b_vec);
}
svst1_f32(pg, &C[i + j*M], c_sum);
}
}
}性能:6.12 GFLOPS(性能提升5.5×倍)
实测性能提升5.5x倍
5.2. SVE 谓词寄存器的精妙之处
NEON 的最大痛点之一是尾部处理:当 M 不被 4 整除时,需要写一套标量循环处理剩余元素。SVE 通过谓词寄存器 svbool_t 彻底解决了这个问题:
M=512, vl=16: 512/16=32 恰好整除,pg = 全真
M=500, vl=16: 500/16=31 余 4
前 31 次迭代: pg = 全真 (16 个 lane 都有效)
第 32 次迭代: pg = 0b00001111 (只有前 4 个 lane 有效)
svld1_f32(pg, addr) → 只加载前 4 个 float,其余 lane 置零
svmla_f32_m(pg, ...) → 只有前 4 个 lane 参与计算
svst1_f32(pg, addr) → 只写入前 4 个 float一行代码 svwhilelt_b32(i, M) 替代了 NEON 中繁琐的标量尾部循环,代码更简洁、更不容易出错。
5.3. SVE 比 NEON 快 2.2 倍原因分析
1) 4 倍数据通路宽度
每条 SVE FMA 处理 16 个 float vs NEON 的 4 个 float。理论上 4 倍吞吐。
2) 谓词消除分支
NEON 的 M 尾部处理需要条件分支,SVE 用谓词无缝处理,减少分支预测失败。
3) 更大的寄存器文件
SVE 有 32 个 Z 寄存器,可处理的数据量为2KB。NEON 只有 32 个 V 寄存器,可处理的数据量为512B。更多寄存器意味着更多累加器可以保持在寄存器中。
5.4. SVE向量化存在的瓶颈
A 的跨步访问——这个从第一种循环展开的优化手段就存在的老问题依然没有解决:
svld1_f32(pg, &A[i + k*M])
k=0: 加载 A[i+0*M] ~ A[i+15+0*M] ← 地址 0~63 字节
k=1: 加载 A[i+1*M] ~ A[i+15+1*M] ← 地址 2048~2111 字节 (跳了 2KB!)
k=2: 加载 A[i+2*M] ~ A[i+15+2*M] ← 地址 4096~4159 字节 (又跳了 2KB!)
虽然 vld1q_f32 一次加载 16 个连续 float(64 字节,恰好一个缓存行),但不同 k 之间跳了 M×4=2048 字节。对于 L1D 缓存(通常 64KB),512×512 矩阵的一列就有 2KB,256 列就占满整个 L1D。频繁的缓存驱逐导致大量 cache miss。