


过滤压缩算子压缩过程用ARM SVE谓词压缩机制弥补x86 movemask指令的实践
发表于 2026/06/23
0
作者 | 蒋天一、俞立呈、余思
1 简介
在高性能向量处理场景中,“比较 + 压缩(Compare & Compress)”算子是距离筛选(KNN)、阈值过滤及稀疏数据生成的关键组件。其核心功能是将输入的uint16距离数组与阈值进行比较,并将结果压缩为uint32位图(Bitmap)输出。
在鲲鹏(ARM架构)开发实践中,我们发现该算子在初期使用ARM NEON指令集实现时,性能表现远逊于x86(AVX2)平台,其绝对耗时约为x86实现的20倍。
这一显著差距促使我们重新审视架构差异:x86拥有高效的movemask指令可直接提取位图,而NEON缺乏类似指令,导致代码陷入了繁琐的“移位-累加”依赖链中。本文将详细阐述如何利用ARM SVE(Scalable Vector Extension)的谓词(Predicate)机制,从算子模型层面重构该计算流程。
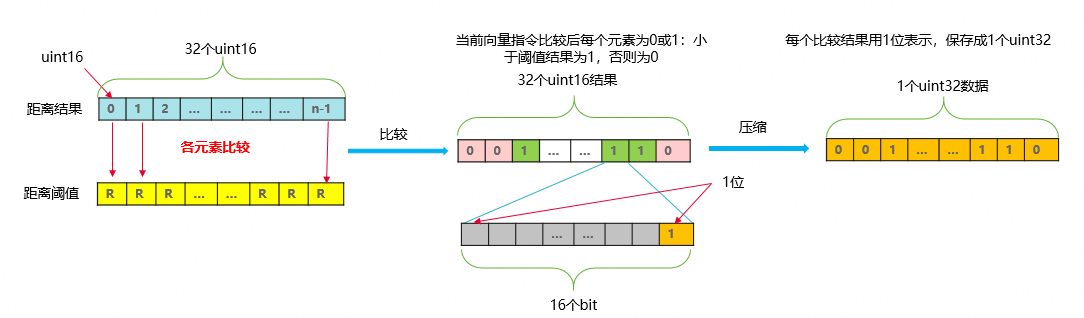
问题本质分析:
- 指令依赖链过长:NEON实现需要通过vshl(移位)和vadd(累加)指令手动拼接bitmask,构成了极长的依赖链,严重阻塞了CPU流水线。
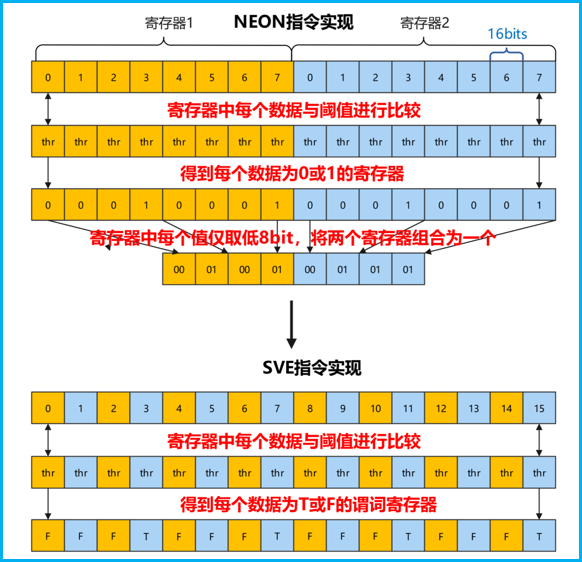
- 寄存器开销:由于NEON寄存器位宽限制(128-bit),处理32个uint16(512-bit)数据需要分多次处理,且需要大量寄存器用于中间结果拼接。
- 架构能力差异:x86的movemask指令通过硬件直接压缩比较结果,而NEON缺乏此类跨向量取值能力,导致频繁的跨通道操作。
2 优化实现
优化方案的核心是将传统的SIMD向量化思维,转变为SVE的谓词压缩模型,SVE替代NEON + Predicate压缩。实现思路如下:
- 位宽提升:从128-bit NEON升级为SVE向量化处理,利用SVE的256-bit/512-bit寄存器,减少处理分片的数量。
- 引入谓词寄存器(Predicate):使用cmplt指令直接生成谓词,谓词存储在专用的p寄存器中,不占用通用向量寄存器资源,彻底解耦比较逻辑。
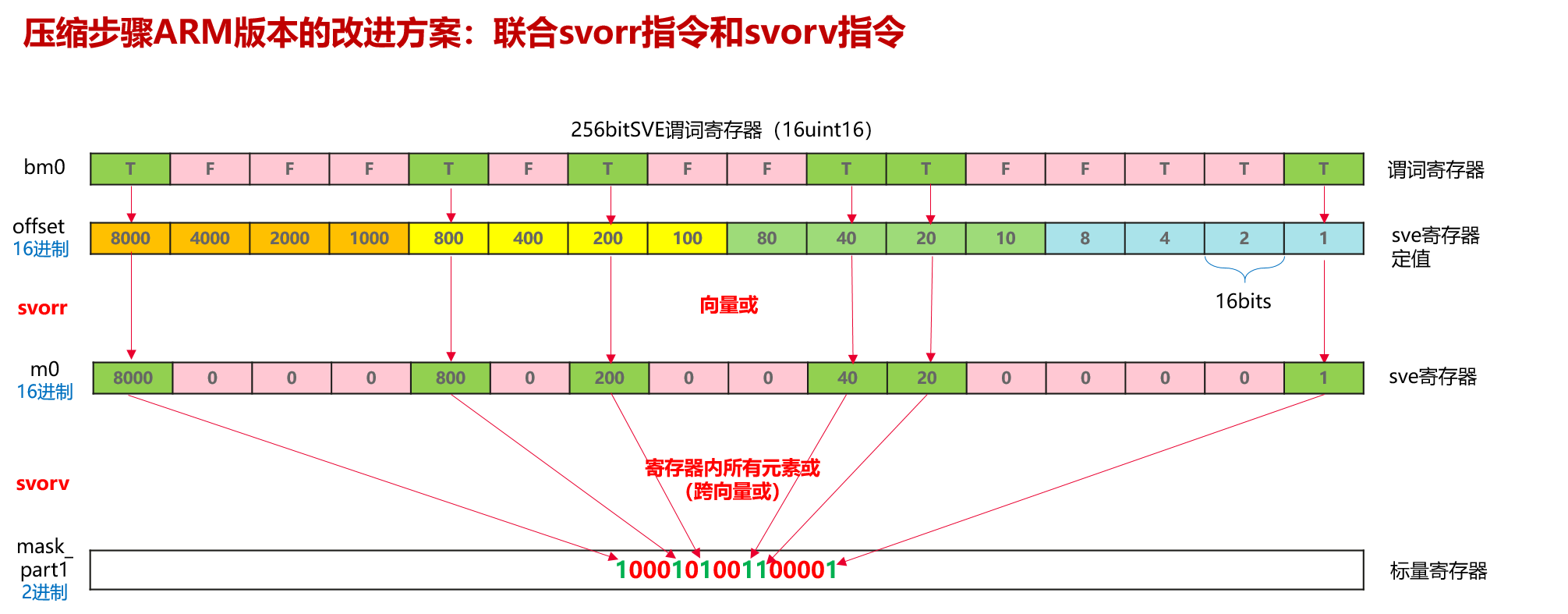
- 重构压缩逻辑:利用svorr(按位或)和svorv(跨向量或归约)直接进行横向合并,取代传统NEON的“移位-累加”流水线。
关键收益
指令数由原先的7指令(15cycle计算+2cycle访存)变为2指令(3cycle计算),指令数减少了约70%,计算时延减少了80%。
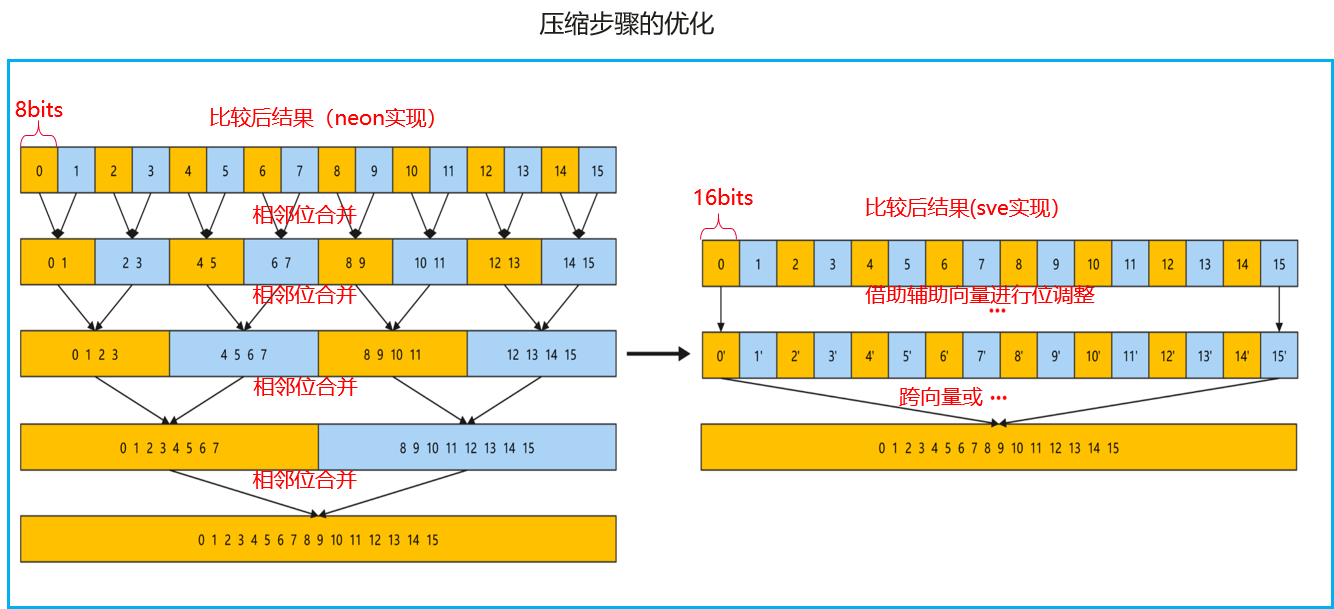
详细优化点
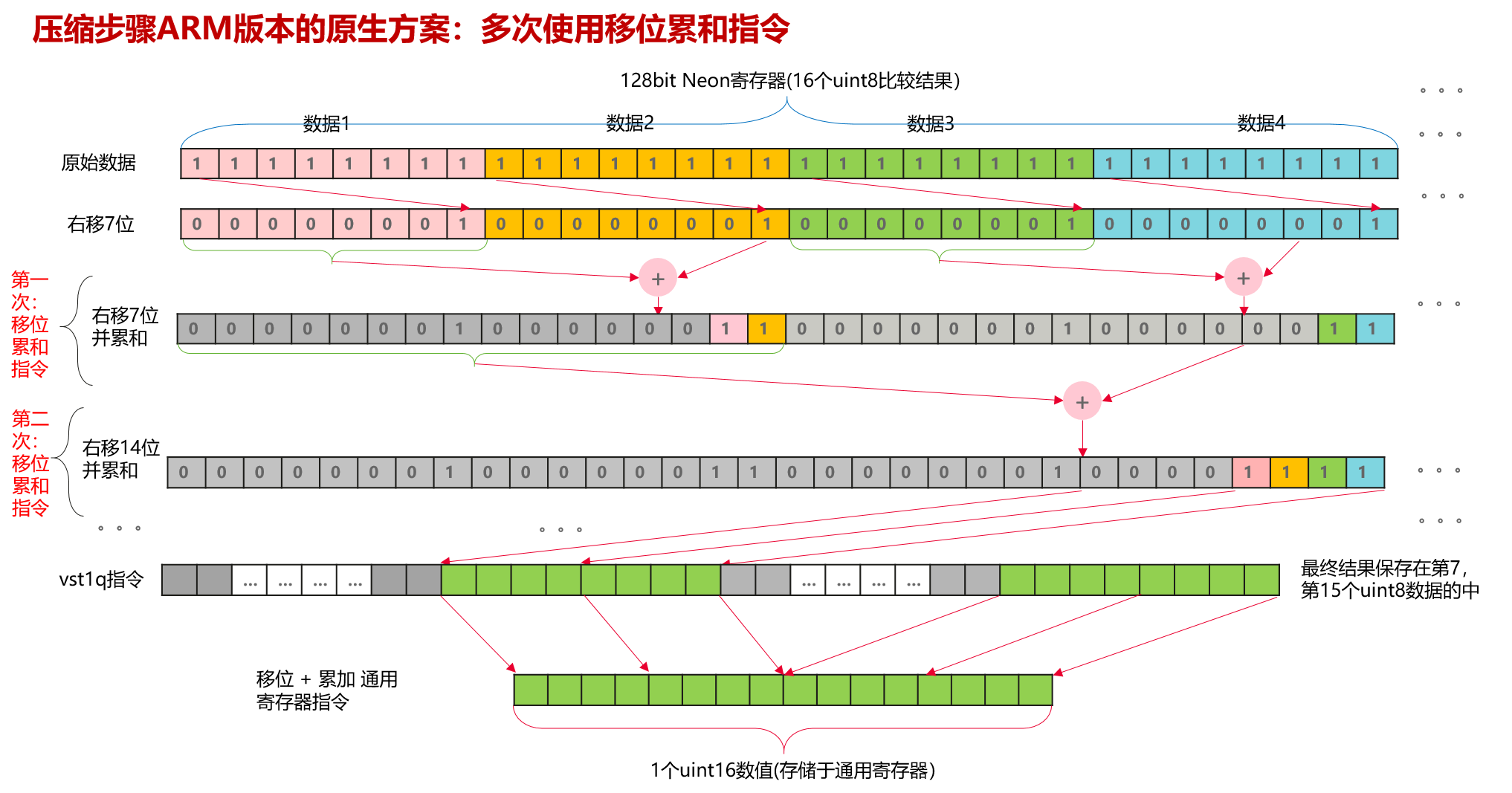
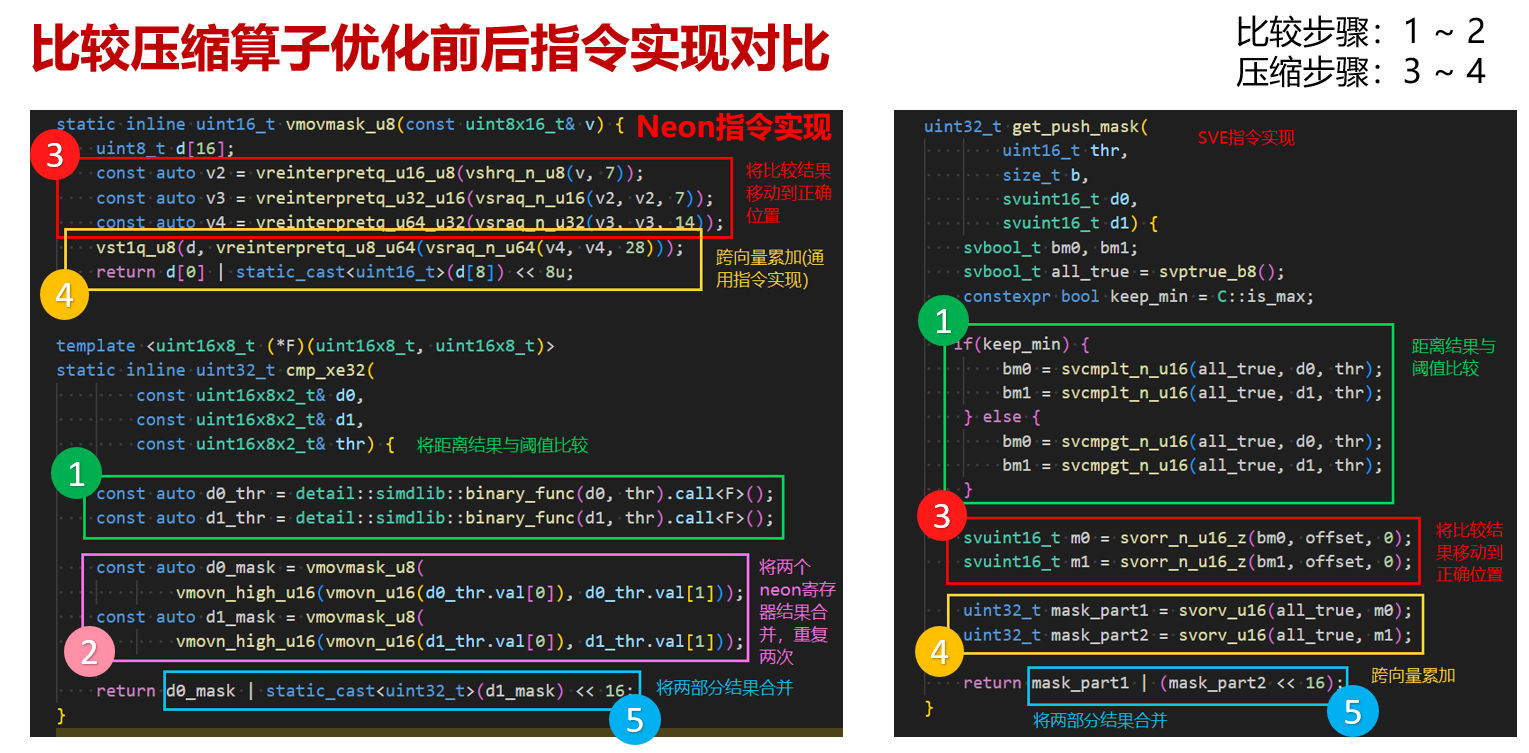
原始ARM方案(NEON):手工构造位图(Bitmask Construction)
在NEON实现中,由于缺乏跨通道(Cross-lane)的直接压缩指令,实现逻辑被迫陷入“手工拼接”的困境:
- 操作逻辑:NEON的vceqq指令执行后,得到的结果是16个bool值的向量(每个元素占用16 bits,且只有MSB有效)。为了得到一个32位的压缩结果,我们必须手动进行反复的vshl(移位)指令,将每个bool值的有效位提取出来,并配合vorr或vadd进行多次累加或合并。
- 工程代价(依赖链瓶颈):这是一个典型的串行依赖链(Dependency Chain)。后续的每一条移位指令都必须等待前序指令的结果写入寄存器。这种“寄存器搬运”会导致严重的流水线停顿(Stall),执行单元在大部分时间内处于空闲等待(Load-to-Use延迟),导致6~7条指令不仅占用了指令流水线宽度,还造成了巨大的时延开销。
改进方案(SVE):谓词归约(Predicate Reduction)
SVE架构通过谓词寄存器(Predicate Registers)和横向归约指令,彻底解决了上述问题:
操作逻辑:
- 谓词生成:利用cmplt等比较指令直接生成谓词结果(如p0)。此时,比较结果已经以“逻辑真/假”的状态直接存储在谓词寄存器中,天然地省去了“提取有效位”的步骤。
- 横向归约:使用svorv(Vector OR Reduction)指令,该指令能够直接跨通道并行地将向量或谓词中的所有有效位“折叠”到一个标量寄存器中。
工程优势:
- 消除依赖:svorv是一种硬件归约指令,它在硬件电路层面完成了多通道数据的聚合,不再依赖串行的位移位操作,消除了NEON中冗长的依赖链。
3 实践效果
指令级对比:
阶段 | 优化前 | 优化后 |
比较步骤 | 8指令 | 2指令 |
压缩步骤 | 14指令 | 4指令 |
其他步骤 | 2指令 | 2指令 |
总计 | 24指令 | 8指令 |
性能结果:
基于鲲鹏920新型号处理器进行NUMA单节点测试:
- 计算时延:15cycles → 3cycles(↓80%)
- 总性能提升:≈ 100% throughput提升(2×)
优化点:
②:使用SVE指令代替NOEN,利用SVE寄存器位宽与AVX2寄存器相同的特性,删去4个结果合并指令。
③:利用SVE指令集特有的谓词寄存器,精细处理寄存器内的每个元素,指令数由7个下降为2个。
④:使用鲲鹏920新型号处理器高性能指令(跨向量累加指令,时延0.5cycle)代替6个通用指令(2cycle),减少计算时延。
优化效果:
- 比较步骤由优化前的8个指令降为2个指令,压缩步骤由优化前的2*7=14个指令降为2*2=4个指令,其他步骤指令数保持2个不变。总指令数由原先的24个指令降为优化后的8个指令。
- 基于鲲鹏920新型号处理器NUMA测试,算子性能提升100%。
4 实践总结
- 优先使用SVE谓词:在处理过滤、筛选类算子时,SVE的predicate是天然的mask管理器,应尽量避免在向量寄存器中进行位掩码拼接。
- 利用硬件归约指令:类似svorv、svandv等归约指令,是解决x86 movemask指令缺失的最佳ARM替代方案。
- 解耦依赖链:通过分析指令依赖图(Dependency Graph),将复杂的移位累加链转化为并行的谓词比较,是挖掘高性能计算潜力的突破口。