


基于ARM NEON的字节重排加速实践
发表于 2026/06/23
0
作者 | 李晨昊
1 简介
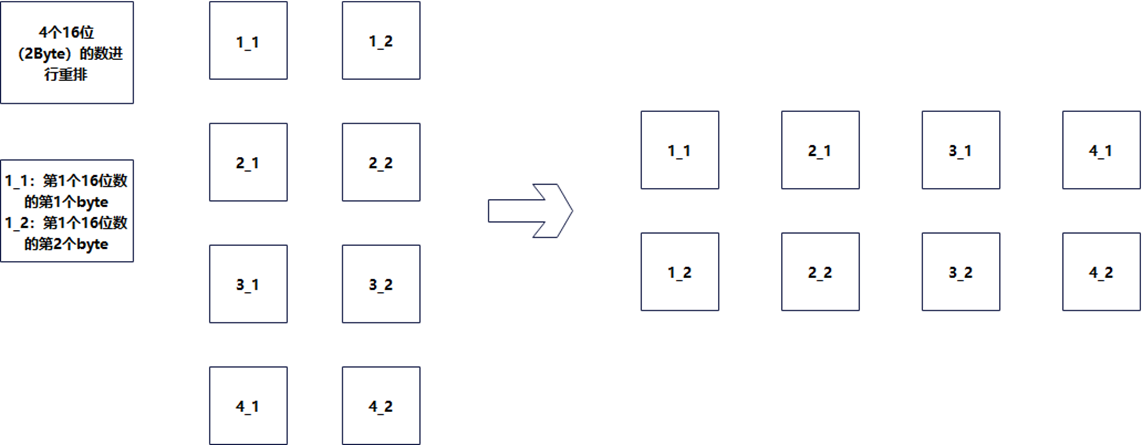
在高性能数据处理领域,字节级重排(Byte-level Shuffle)是一项基础且频繁的操作。本文探讨的bshuf_trans_byte_elem操作,其核心目标是将固定宽度(2/4/8byte)的数据按“字节列”进行重排。
这一过程在数学上等价于对“列数为N(N=2/4/8)”的矩阵进行转置。例如,将4个2-byte数据进行重排,即是将二维矩阵进行行列互换。在ARM NEON/AArch64架构下,该操作直接决定了后续计算任务的流水线吞吐率。如何利用SIMD指令高效实现该转置,是提升算子性能的关键。
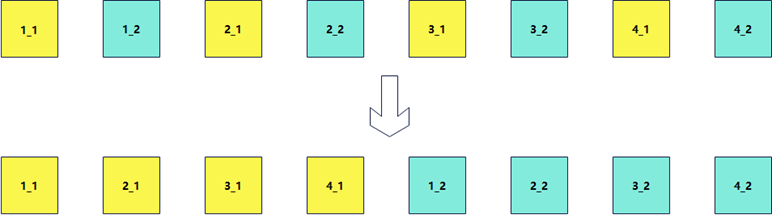
上图将4个2byte的数重排等同于下图将列数为2的矩阵进行转置。
2 分析
2.1 问题本质分析
bshuf_trans_byte_elem的瓶颈主要来自:
- 访存非连续(Gather-like Behavior):数据访问并非线性,导致Cache Line利用率低下,内存访问延迟高。
- 标量实现瓶颈:传统标量代码涉及大量的字节提取与移位,开销远超计算本身。
- SIMD局限性:传统SIMD指令往往难以直接应对任意幅度的Shuffle操作,导致依赖链过长。
2.2 基线实现(ZIP指令)
官方常见的基线实现采用ZIP1/ZIP2指令进行交错模拟(类似x86的unpacklo/unpackhi)。该方案需要多轮交错操作,导致指令依赖链过长,延迟(Latency)较高,难以掩盖执行单元的等待开销。
典型结构:
zip1 v0.16b, vA.16b, vB.16b
zip2 v1.16b, vA.16b, vB.16b
zip1 v2.16b, vC.16b, vD.16b
zip2 v3.16b, vC.16b, vD.16b
...
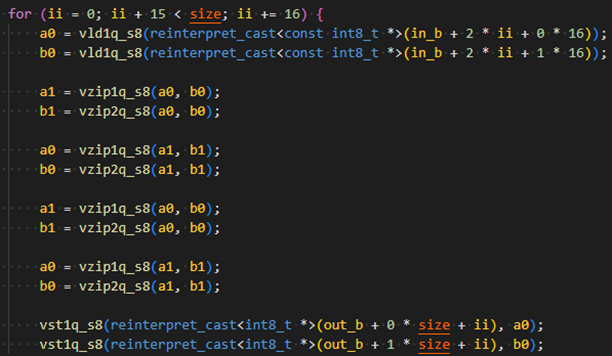
实现步骤:

3 优化路径
针对上述瓶颈,我们探讨三种基于ARM NEON的优化路径,并对设计决策进行深度剖析。
优化思路1:TBL查表实现(Lookup Shuffle)
核心思想:利用TBL(Table Lookup)指令的固定索引映射能力进行重排。
- 逻辑:通过定义预设的索引向量,将原始数据的字节直接映射到目标位置。
- 决策分析:该方案灵活性极强,适用于任意Shuffle模式。但其局限在于高度依赖Table Register,在访存压力较大的场景下,会产生较大的寄存器压力。
以2-byte为例:
src: [A0 A1 B0 B1 C0 C1 D0 D1]
dst: [A0 B0 C0 D0 | A1 B1 C1 D1]可以拆解为:
- 第0 byte group:index = 0,2,4,6
- 第1 byte group:index = 1,3,5,7
因此可以用TBL完成:
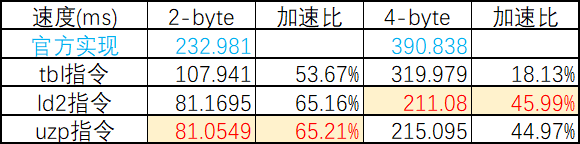
性能结果如下:
数据宽度 | 无内存瓶颈 | 有内存瓶颈 |
2-byte | +53.6% | +0.7% |
4-byte | +18.1% | +7.6% |
8-byte | -3.8% | ≈0% |
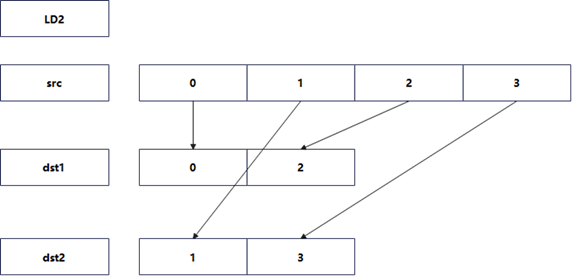
优化思路2:LD2/LD4交织加载
核心思想:利用ARM NEON的结构化加载指令,在数据从内存加载到寄存器的过程中完成交错。
逻辑:LD2和LD4指令自动处理数据的交叉加载。
- LD2:加载并交错2路数据
- LD4:加载并交错4路数据
决策分析:这是硬件级的Interleave,能显著减少Shuffle指令的使用,流水线极其友好。局限在于该指令集不支持LD8,在64-bit扩展场景下不适用。
性能结果如下:
数据宽度 | 无内存瓶颈 | 有内存瓶颈 |
2-byte | +65.1% | +2.5% |
4-byte | +45.9% | +8.7% |
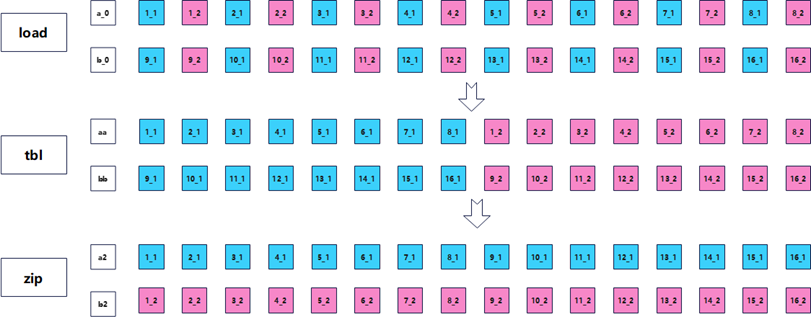
优化思路3:UZP指令优化
核心思想:使用UZP(Unzip)指令提取间隔数据。
- 逻辑:UZP1/UZP2指令可视为ZIP指令的逆操作,专门用于从两个向量中“解交错”提取数据。
- 决策分析:这是ARM特有的高效指令,具备低延迟、无Lookup overhead的特性,最贴合底层流水线设计,是矩阵转置中的最优选择。
指令语义
uzp1 v0.16b, vA.16b, vB.16b
uzp2 v1.16b, vA.16b, vB.16b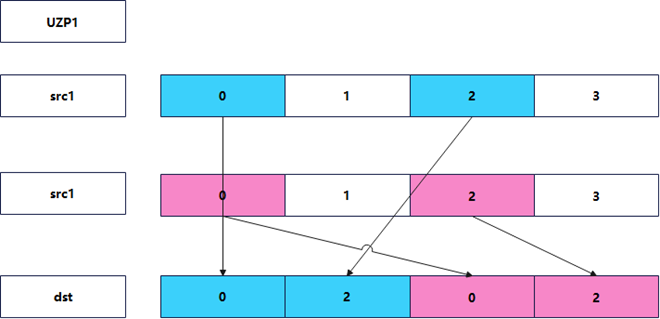
本质理解
- ZIP:交错合并,“逐步拼接”,需要从底层到顶层多轮合并。每一轮输出必须作为下一轮输入,强串行依赖。
- UZP:逆向解交错,“逐层拆分”,路径更短,指令数更少。分层依赖更松散,ARM乱序执行可部分重叠执行。
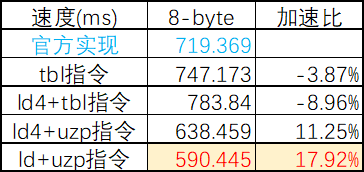
性能结果如下:
数据宽度 | 无内存瓶颈 | 有内存瓶颈 |
2-byte | +65.2% | +3.2% |
4-byte | +44.9% | +10.3% |
8-byte | +17.9% | +10.1% |
4 实践效果对比分析
- 无内存瓶颈时:UZP指令在大部分场景下表现优异,在2-byte和4-byte场景下与LD2/LD4旗鼓相当。
- 内存瓶颈场景下:UZP指令展现了极强的稳定性,更贴近硬件吞吐极限。
3. 8-byte特殊场景:LD4指令失效,此时UZP成为唯一且表现稳定的高性能方案。
5 实践总结
UZP指令是ARM架构下矩阵转置的核心算子。它不仅是ZIP指令的逆过程,更是实现高效数据重排的最佳实践。
优化原则与通用模式
- 架构优势显著:UZP(Unzip)作为ARM架构下的高性能优化利器,在处理不同数据宽度的字节重排任务时,均展现出了远超通用指令组合的性能优势,是实现高效矩阵转置的核心算子。
- 对称的架构逻辑:ZIP与UZP是一对互逆指令。ZIP侧重于数据的交错合并(Interleave),而UZP专精于数据的解交错提取(De-interleave)。利用这一对称性,开发者可以灵活地进行数据的拆解与组合。
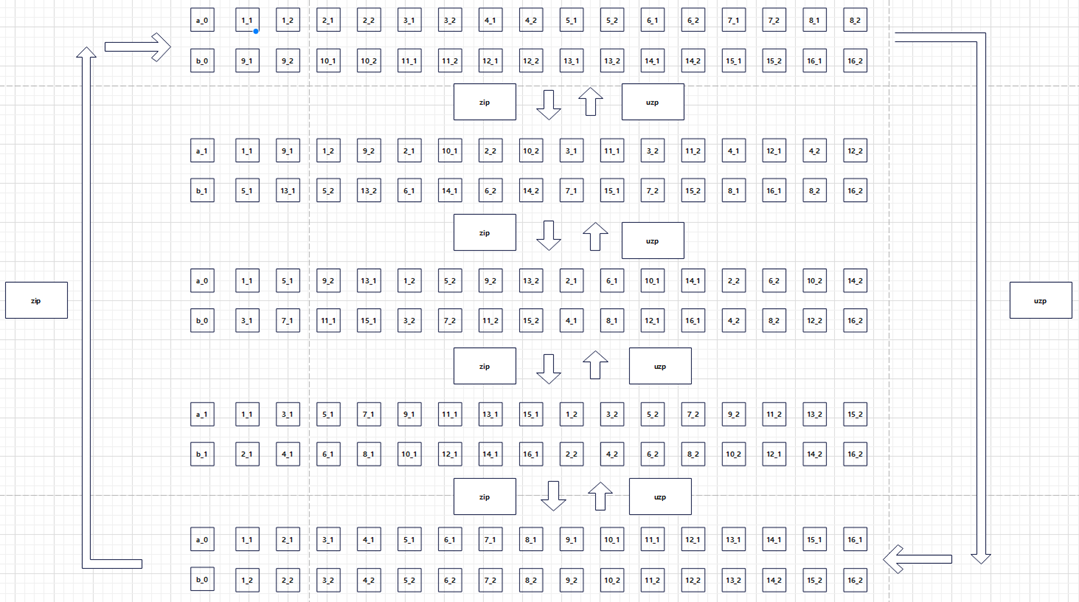
上图展示了ZIP、UZP指令是幂等的。