


Linux系统性能调优常用性能分析工具介绍
发表于 2026/06/23
0
作者 | 吴华建
1 资源使用情况采集
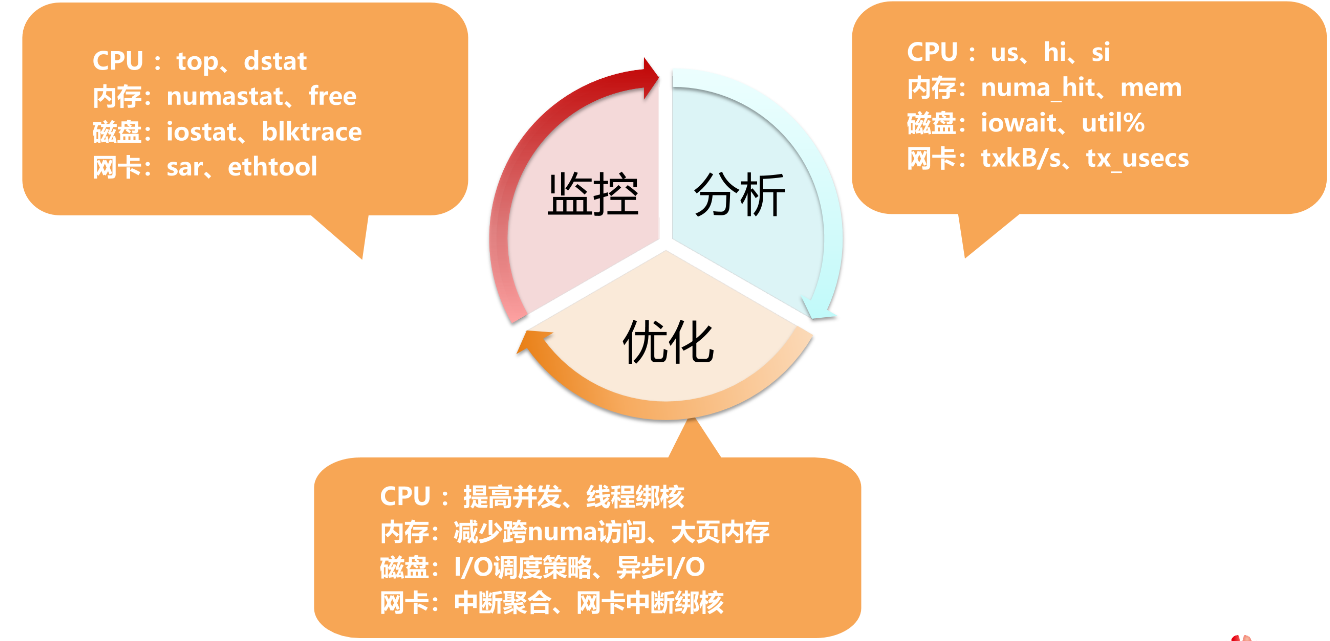
Linux系统性能调优的完整闭环流程按照“监控→分析→优化”迭代,并按CPU、内存、磁盘、网卡四大维度给出了对应的工具、指标和优化手段。
图1-1是一个循环往复的调优流程,三个步骤形成闭环:
1. 监控:用工具采集系统各组件的运行数据。
2. 分析:基于监测的指标定位性能瓶颈。
3. 优化:针对瓶颈点实施优化措施。
4. 优化后回到监控环节,验证优化效果,进入下一轮迭代。
2 NUMA性能分析
鲲鹏处理器支持NUMA(Non-uniform memory access,非统一内存访问)架构,能够很好地缓解SMP(Symmetric Multi-Processing,对称多处理)技术对CPU核数的制约。NUMA架构将多个核结成一个节点(Node),每一个节点相当于一个对称多处理机(SMP),一块CPU的节点之间通过On-chip Network通信,不同的CPU之间采用Hydra Interface实现高带宽低时延的片间通信。在NUMA架构下,整个内存空间在物理上是分布式的,所有这些内存的集合就是整个系统的全局内存。每个核访问内存的时间取决于内存相对于处理器的位置,访问本地内存(本节点内)会更快一些。使用鲲鹏处理器所实现的计算机系统,通过适当的性能调优,既能够获得很好的性能,又能够解决SMP架构下的总线瓶颈问题,提供更强的多核扩展能力,以及更好更灵活的计算能力。
numactl工具可用于查看当前服务器的NUMA节点配置、状态,还用于将进程绑定到指定CPU核,绑定后由指定CPU核运行对应进程。
步骤 1 您可以从OEPKGS软件包服务界面下载并安装numactl。
步骤 2 执行numactl -H命令,查看NUMA节点的CPU和内存资源分配。
步骤 3 执行numastat命令,查看访存情况。

表1-1 numastat访存结果说明
参数 | 说明 |
numa_hit | 命中的,也就是为这个节点成功分配本地内存访问的内存大小。 |
numa_miss | 把内存访问分配到另一个node节点的内存大小,这个值和另一个node的numa_foreign相对应。 miss值和foreign值越高,就要考虑绑定的问题。 |
numa_foreign | 另一个Node访问我的内存大小,与对方node的numa_miss相对应。 |
local_node | 这个节点的进程成功在这个节点上分配内存访问的大小。 |
other_node | 这个节点的进程在其它节点上分配的内存访问大小。 |
3 CPU性能分析
本节介绍CPU性能分析的常用工具。
top
top是最常用的Linux性能监测工具之一,由系统自带,无需安装。通过top工具可以监视进程和系统整体性能。
命令参考举例如表3-1所示。
表3-1 top命令示例
命令 | 说明 |
top | 查看系统整体的CPU、内存资源消耗。 |
top执行后输入1 | 查看每个CPU核资源使用情况。 |
top执行后输入F,并选择P选项 | 查看线程执行过程中是否调度到其它CPU核。 |
top -p $PID -H | 查看某个进程内所有线程的CPU资源占用。 |
top -H -p {pid} | 输出某个特定进程并检查该进程内运行的线程状况。 |
步骤 1 使用top命令统计整体CPU、内存资源消耗。
表3-2 top命令查看CPU、内存资源消耗信息
参数类别 | 说明 |
%Cpu | 显示当前总的CPU时间使用分布。通过下述参数我们可以分析CPU时间的分布,是否有较多的I/O等待。在执行完调优步骤后,我们也可以对CPU使用时间进行前后对比。如果在运行相同程序、业务情况下CPU使用时间降低,说明性能有提升。 l us表示用户态程序占用的CPU时间百分比。 l sy表示内核态程序所占用的CPU时间百分比。 l ni表示用户进程空间内改变过优先级的进程占用CPU时间百分比。 l id表示空闲CPU时间百分比。 l wa表示I/O等待占用的CPU时间百分比。 l hi表示硬中断所占用的CPU时间百分比。 l si表示软中断所占用的CPU时间百分比。 l st表示虚拟机/虚拟化技术占用CPU时间百分比。 |
KiB Mem | KiB Mem表示服务器的物理内存大小以及使用情况。其中buffer/cache用作内核缓存的内存量(cache使用情况)。buffer是磁盘缓冲区,cache是文件系统的缓存,用于区分裸盘IO和文件系统IO。 |
KiB Swap | KiB Swap表示当前Swap交换区空间大小及使用情况。Swap空间即当内存不足的时候,把一部分硬盘空间虚拟成内存使用。如果当前所使用的Swap空间大于0,可以考虑优化应用的内存占用或增加物理内存。 |
PID | PID表示进程ID。 |
USER | USER表示进程所有者。 |
PR | PR表示进程优先级。 |
NI | NI表示nice值。负值表示高优先级,正值表示低优先级。 |
VIRT | VIRT表示进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES。 |
RES | RES表示进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA。 |
SHR | SHR表示共享内存大小,单位kb。 |
S | S表示进程状态。 l D:不可中断的睡眠状态 l R:运行 l S:睡眠 l T:跟踪/停止 l Z:僵尸进程 |
%CPU | %CPU表示上次更新到现在的CPU时间占用百分比。 |
%MEM | %MEM表示进程使用的物理内存百分比。 |
TIME+ | TIME+表示进程使用的CPU时间总计,单位1/100秒。 |
COMMAND | COMMAND表示进程名称(命令名/命令行),使用top -c可以显示完整命令。 |
步骤 2 进入top界面后,按F进入显示设置,选中后按空格,然后Esc回到top界面。
步骤 3 进入top界面后,按1查看每个CPU核的使用情况,按3选择NUMA节点,输入数字后Enter。
步骤 4 按H可显示所有独立线程而不是汇总的进程信息。按t切换显示模式。
htop
htop是Linux/Unix系统里一款彩色、交互式的进程与系统监控工具,是top工具的强力替代品,更美观、更好用、功能更强。您可以从OEPKGS软件包服务下载htop的rpm包。
htop配置文件位于“~/.config/htop/htoprc”目录下,您可以参考。
column_meters_0=LeftCPUs2 Memory Swap #LeftCPUs2表示在左侧每行显示两个CPU的使用情况,左侧下方显示Memory和Swap使用情况
column_meter_modes_0=1 1 1 #CPU、Memory、Swap以条形图显示
column_meters_1=RightCPUs2 Tasks LoadAverage Uptime #RightCPUs2表示右侧面板每行显示两个CPU的使用情况,右侧下方显示Tasks任务数、LoadAverage、Uptime系统运行时间
column_meter_modes_1=1 2 2 2 #CPU以条形图显示,Tasks、LoadAverage、Uptime以文本显示执行htop命令即可打开界面,实时查看各个核使用情况。
pidstat
pidstat是进程级性能监控工具(sysstat工具集),可以周期性采集指定单个进程的CPU资源占用统计,按间隔持续输出CPU使用率、内核/用户态耗时、线程调度等CPU指标,定位进程CPU高负载问题。
执行pidstat -u -p {pid} {sec}命令,间隔sec秒查询一次CPU使用情况,参数说明如表3-3所示。
表3-3 pidstat命令参数说明
参数 | 含义 |
-u | 监测CPU指标。 |
-p {pid} | 只监测指定单个进程PID,不输出全量进程。 |
{sec} | 采样间隔(单位:秒),每隔sec秒输出一行统计;不带次数则无限循环输出,Ctrl+C终止。 |
cpupower
cpupower是Linux内核CPU调频工具包(cpupowerutils),用于查看和设置CPU调频策略、运行频率,依赖内核cpufreq子系统。
执行cpupower -c all frequency-info -f命令,查询系统所有CPU逻辑内核的实时当前运行主频,参数说明如表3-4所示,主要应用在如下场景:
- 排查CPU降频问题:CPU负载高但性能不足,核查是否因温控、电源策略触发自动降频。
- 确认性能调频策略生效:设置performance高性能模式后,验证CPU是否稳定跑满标称主频。
- 功耗优化验证:切换powersave/ondemand节能策略,观察CPU空载降频是否正常。
- 性能压测:CPU压力测试前后对比主频,确认CPU没有被功耗墙限制频率。
表3-4 cpupower命令参数说明
参数 | 含义 |
-c all | 指定操作所有CPU核心,也可以替换为0~31等核编号范围,即想要查询的核的实时频率,例如-c 0-3只查询0~3号核。 |
frequency-info | 查询CPU频率相关信息。 |
-f | frequency-info的附加参数:只输出当前实际运行频率(当前瞬时主频),精简输出。 |
4 内存性能分析
pidstat
pidstat是进程级性能监控工具(sysstat工具集),带参数-r -p主要是按指定间隔sec秒,持续采集单个指定PID进程的内存使用、缺页异常指标,周期性输出内存统计,用于排查进程内存泄漏、缺页过高导致CPU/IO卡顿问题。
执行pidstat -r -p {pid} {sec}命令,间隔sec秒查询一次内存使用情况,参数说明如表4-1所示。
15:32:12 UID PID minflt/s majflt/s VSZ RSS %MEM Command
15:32:14 1000 1234 120.50 2.00 256892 89240 2.35 ./app_server
15:32:16 1000 1234 115.00 1.50 257240 89612 2.36 ./app_server表4-1 pidstat命令参数说明
参数 | 含义 |
-r | 代表内存占用+缺页中断统计。 |
-p {pid} | 只监测指定单个进程PID,不输出全量进程。 |
{sec} | 采样间隔(单位:秒),每隔sec秒输出一行统计;不带次数则无限循环输出,Ctrl+C终止。 |
回显信息中参数说明如下:
- UID:进程运行用户ID。
- PID:被监测的进程ID。
- minflt/s:每秒次缺页错误次数(minor page faults),次缺页错误次数即虚拟内存地址映射成物理内存地址产生的page fault次数。
- majflt/s:每秒主缺页错误次数(major page faults),当虚拟内存地址映射成物理内存地址时,相应的page在swap中,这样的page fault为major page fault,需要从磁盘swap/文件读取物理页,一般在内存使用紧张时产生。
- VSZ:该进程使用的虚拟内存总大小(以KB为单位)。
- RSS:该进程使用的物理内存总大小(以KB为单位)。
- %MEM::该进程使用的RSS占整机物理内存的百分比。
- Command:进程启动命令。
free
free查看系统整机内存、swap交换分区使用统计,读取/proc/meminfo数据,通常在整机内存水位排查、swap使用频繁升高等场景进行使用。
执行free [-b -k -m -g -t]命令,以Byte、KB、MB、GB或TB为单位显示内存使用情况,参数说明如表4-2所示。
表4-2 free命令参数说明
参数 | 含义 |
-b | 以Byte(字节)为单位展示。 |
-k | 以KB为单位展示,不加参数默认等价-k。 |
-m | 以MB为单位展示,运维场景最常用。 |
-g | 以GB为单位展示。 |
-t | 输出末尾增加Total汇总行,包括总内存合计、总swap合计。 |
内存大页
1. 执行numastat -p {pid} -m -s命令,指定某个进程统计该进程在各个NUNA Node上的内存使用情况,用于排查进程内存跨节点分配、NUMA不均衡等问题。参数含义如下:
- -p PID:指定单个进程PID,统计该进程在各个NUMA Node上的内存分布。
- -m:以MB为单位展示内存。
- -s:按Node内存占用从大到小排序输出。
2. 执行cat /proc/meminfo | grep Huge命令,读取系统全局内存信息,过滤所有HugePage全局统计项,查看系统配置、已分配、空闲、剩余大页数量/内存,是操作系统全局大页总览,用于检查系统HugePage是否配置、预留是否充足等场景。
3. 执行cat /sys/devices/system/node/node*/meminfo | fgrep Huge命令,分NUMA节点查看每个Node各自的HugePage总数量、空闲数量、占用数量,用于检查每个Node是否存在分配不均衡的问题。
Node 0 HugePages_Total: 512
Node 0 HugePages_Free: 10
Node 0 HugePages_Rsvd: 490
Node 0 HugePages_Surp: 0
Node 1 HugePages_Total: 512
Node 1 HugePages_Free: 500
Node 1 HugePages_Rsvd: 12
Node 1 HugePages_Surp: 0命令回显信息中HugePages_Total表示大页内存的总数,HugePages_Free表示可用的大页内存数量。如果HugePages_Free的值比较小,说明大页内存已经被占用得比较多了。
DevKit
鲲鹏DevKit命令行工具能收集服务器的处理器硬件、操作系统、进程/线程、函数等各层次的性能数据,提供系统多场景性能采集和分析能力,并基于调优系统给出优化建议。
- 访存统计分析:基于CPU访问缓存和内存的PMU事件,分析存储的访问次数、命中率、带宽等相关情况,详细操作请参见《鲲鹏DevKit性能分析用户指南》中的“访存统计分析”。命令示例如下:
devkit tuner memory -d 30 -o /home/memory_result -m 1 --package- NUMA精细化分析:基于ARM SPE的能力分析得到系统精细化的DDR访问、NUMA访问流量矩阵以及进程的内存访问等相关信息。,详细操作请参见《鲲鹏DevKit性能分析用户指南》中的“NUMA精细化分析”。命令示例如下:
devkit tuner numafast -i 2 -c 2048 -n 3 --package采集NUMA精细化数据时需要服务器支持ARM SPE采集能力,配置SPE的具体操作请参见《鲲鹏DevKit性能分析用户指南》中的“配置SPE环境”。
透明大页
执行如下命令,用于查看Linux内核透明大页THP(Transparent Huge Pages)配置状态,THP是Linux内核内存优化机制,把普通4KB小页合并为大内存页,减少TLB缺页、提升内存访问性能。
- 查看透明大页全局启用模式。
cat /sys/kernel/mm/transparent_hugepage/enabled- 查看THP内存碎片整理策略。
cat /sys/kernel/mm/transparent_hugepage/defrag清理缓存
sysc用于把Linux系统缓冲区中还没写入磁盘的脏数据强制刷写到物理磁盘。Linux为提升IO性能,写入文件先写到内存缓冲区(脏页),延后落盘;sync主动同步落地磁盘,避免清空缓存时脏数据丢失。执行清理系统缓存前,先执行sysc落盘脏数据,防止丢失数据。
echo x > /proc/sys/vm/drop_caches用于释放缓存。echo x可选参数包括echo 1、echo 2、echo 3,各自含义不同,所表4-3所示。
表4-3 echo命令说明
命令 | 含义 |
echo 1 > /proc/sys/vm/drop_caches | 释放页缓存(PageCache)。 |
echo 2 > /proc/sys/vm/drop_caches | 释放dentries(目录项)+inode缓存。 |
echo 3 > /proc/sys/vm/drop_caches | 页缓存+目录项+inode缓存全部释放。 |
sync
echo 1 > /proc/sys/vm/drop_caches
echo 2 > /proc/sys/vm/drop_caches
echo 3 > /proc/sys/vm/drop_caches
源码打桩查看内存使用情况
对于C/C++源码,只需要添加以下函数,然后在采集点调用即可。源码打桩的作用是查看进程在运行期间所占用的物理内存(RAM)的最大值,用于识别内存消耗情况。
#include <sys/resource.h>
#include <stdio.h>
static inline void MemUsage() {
struct rusage r_usage;
getrusage(RUSAGE_SELF, &r_usage);
long long int mymem = r_usage.ru_maxrss;
printf("Total memory usage: %.4f MB\n", (double)((double)(mymem) / (double)(1024)));
}对于Fortran源码,可以通过构造接口来实现:
1. 构造包含上述函数的C文件,需要去除static inline,假设命名为testC.c,且这里的函数名用小写,带尾椎_,这样Fortran才能找到。
void memusage_() {
struct rusage r_usage;
getrusage(RUSAGE_SELF, &r_usage);
long long int mymem = r_usage.ru_maxrss;
printf("Total memory usage: %.4f MB\n",(double)((double)(mymem) / (double)(1024)));
}2. 构造Fortran文件,假设命名为testF.f90,这里call调用的就是C文件里面的接口,call接口的时候无需添加尾椎_。
MODULE xxx
CONTAINS
SUBROUTINE MEM_USAGE()
call memusage();
END SUBROUTINE MEM_USAGE
END MODULE xxx3. 编译目标文件和mod。
clang -c testC.c
flang -c testF.f90 -Mfree这样就得到了testC.o、testF.o和xxx.mod文件。
4. 源码打桩。
只需要在待采集的Fortran源码里USE xxx引入xxx.mod,然后在采集点调用call MEM_USAGE()即可。
5. 编译源码时,需链接testC.o和testF.o,例如:
flang mem_demo.f90 testC.o testF.o -o mem_demo5 磁盘性能分析
pidstat
pidstat是进程级性能监控工具(sysstat工具集),带参数-d -p代表周期性采集指定进程的磁盘IO性能指标,统计进程的块设备读写、磁盘IO吞吐,区分进程读磁盘、写磁盘数据量,定位进程磁盘IO过高问题。
执行pidstat -d -p {pid} {sec}命令,间隔sec秒查询一次磁盘IO情况,参数说明如表5-1所示。
14:35:21 UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
14:35:23 99 1892 0.00 256.00 0.00 mysqld
14:35:25 99 1892 0.00 324.00 0.00 mysqld表5-1 pidstat命令参数说明
参数 | 含义 |
-d | 代表磁盘IO统计,查看进程磁盘读写。 |
-p {pid} | 只监测指定单个进程PID,不输出全量进程。 |
{sec} | 采样间隔(单位:秒),每隔sec秒输出一行统计;不带次数则无限循环输出,Ctrl+C终止。 |
回显信息中参数说明如下:
- UID:进程运行用户ID。
- PID:被监测的进程ID。
- kB_rd/s:每秒进程从磁盘实际读取的数据量(以KB为单位)。
- kB_wr/s:每秒进程向磁盘实际写入的数据量(以KB为单位)。
- kB_ccwr/s:被取消的写入数据量(以KB为单位)。
- Command:进程启动命令。
iostat
iostat用于输出每个磁盘设备的IO负载情况。
执行iostat -x {sec}命令,每隔sec秒周期性输出整机所有磁盘设备IO扩展指标,包括磁盘IO负载、队列长度、IO等待、读写吞吐量等,参数说明如表5-2所示。
Linux 3.10.0-1160.el7 (localhost) 06/05/2026 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
2.15 0.00 3.25 8.62 0.00 85.98
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await
r_await w_await svctm %util
sda 0.00 12.50 2.00 45.00 128.00 2320.00 104.17 3.25 68.22 12.50 70.71 20.12 94.30表5-2 iostat命令参数说明
参数 | 含义 |
-x | 展示扩展详细IO统计。 |
{sec} | 采样间隔时间。 |
回显信息中的参数说明如下:
- r/s:每秒读请求数。w/s:每秒写请求数,即每秒处理的IO请求数,IOPS=r/s+w/s,一次磁盘的连续读或者连续写称为一次磁盘I/O。
- rkB/s:每秒读吞吐量,以KB为单位。wkB/s:每秒写吞吐量,以KB为单位。又叫Throughput,硬盘传输数据流的速度,传输数据量为读出和写入的和。
- avgrq-sz:平均I/O数据尺寸,每次请求的大小,等于吞吐量除以IO数。平均数据量小于32K说明业务以随机存取为主,大于32K以顺序存储为主。
- avgqu-sz:I/O等待队列长度,超过处理能力的请求数目,待处理的IO请求。请求持续超出磁盘处理能力则该值增加,大于2可以认为存在I/O性能问题。
- await:等待时间,请求完成耗时。当await约等于svctm时说明IO基本没有等待,当远大于svctm时说明IO队列较长,请求得到响应的等候时间较长。
- svctm:服务时间,处理请求的能力,指磁盘读或写操作执行的时间,包括寻道,旋转时延和数据传输等时间。其大小一般和磁盘性能有关,CPU和内存的负荷也会对其有影响,请求过多也会间接导致服务时间的增加。如果该值持续超过20ms,一般可考虑会对上层应用产生影响。这里主要指的是FC、SAS、SATA磁盘,转速通常为5400/7200/1W转。
- %util:磁盘活动时间百分比,磁盘利用率。磁盘利用率与资源争用程度成正比,与性能成反比。
read_ahead_kb
- 查询每个磁盘队列的预读缓冲区大小:for disk in /sys/block/*/queue/read_ahead_kb; do cat $disk; done
- 修改所有物理磁盘预读大小改为4096KB,临时生效(重启服务器或重新加载内核驱动失效):for disk in /sys/block/*/queue/read_ahead_kb; do echo 4096 > $disk; done
lsblk
执行lsblk命令,列出系统所有块设备(磁盘、分区、RAID、loop、光驱)树形结构信息,从/sys/devices读取硬件信息,用于快速梳理服务器磁盘分区结构,排查磁盘挂载异常等问题。
df -h
执行df -h命令,查看已挂载文件系统的磁盘空间使用率,用于日常巡检服务器磁盘剩余容量,排查磁盘使用率是否爆满等问题。
du -sh
执行du -sh <文件名或文件夹名>命令,查看指定文件或文件夹下所有文件占用磁盘大小,用于查看单个日志文件、业务目录等占用容量,逐层排查占用空间超大的目录。
逻辑盘读写策略
逻辑盘读写策略可通过iBMC直接调整,或进入BIOS调整,或下载安装StorCLI工具进行配置。
6 网卡性能分析
命令 | 功能 | 参数说明 |
sar -n DEV 1 10 | grep {eth} | 查看网卡实时流量、数据包转发,包含网卡收发包、收发字节、丢包、错误包统计,用于定位网卡丢包、收发异常、流量瓶颈等问题。 | l -n DEV:代表网卡设备统计。 l 第一个1表示采样间隔为1秒,第二个10表示采集10轮数据。 l grep过滤指定网卡。{eth}为网卡名称。 |
cat /proc/net/bonding/bondx | 查看内核Bonding驱动配置信息,包括Bond模式、从属物理网卡、主备状态、链路监测、故障切换等信息,用于定位Bond组网故障。 | bondx中x需要根据具体的绑定模式进行修改。关于Bond模式的介绍请参见bond模式详解与实例。 |
ethtool –i {eth} | 查看网卡硬件、驱动信息,获取bus-info,包括网卡驱动名称、驱动版本、固件版本、bus-info(PCI总线地址),为后续lspci、numa查询提供参数。 | {eth}为网卡名称。 |
lspci -vvv -s {bus-info} | 根据PCI地址查看网卡硬件详细信息,包括芯片型号、中断、MSI-X、PCIe速率、硬件NUMA归属等,用于核对网卡硬件所属NUMA节点,辅助CPU亲和优化。 | {bus-info}为PCI总线地址。 |
ethtool -k {eth} | 查看网卡Offload硬件卸载开关,包括TSO/GSO/GRO/CSUM等,网卡硬件分担内核报文分片、校验和计算,优化CPU占用。 | {eth}为网卡名称。 |
ethtool -c {eth} | 查看网卡中断聚合配置信息,例如中断聚合时间间隔、聚合报文数等,网卡攒若干报文/等待指定时间再上送一次中断,减少高频小包中断。 | {eth}为网卡名称。 |
ethtool -l {eth} | 查看网卡RSS收发队列数量,包括RX、TX队列。RSS队列绑定不同CPU核实现多核负载分担。 | {eth}为网卡名称。 |
ethtool -g {eth} | 查看网卡硬件收发环形缓冲区长度,缓冲区过小会出现网卡RX/TX丢包。 | {eth}为网卡名称。 |
cat /sys/class/net/{eth}/device/numa_node | 快捷读取网卡所属NUMA节点编号,无需lspci,内核sysfs直接输出,用于辅助网卡绑核优化、进程CPU亲和优化,以确保进程尽量运行在网卡同NUMA节点,减少跨NUMA访问损耗。 | {eth}为网卡名称。 |
cat /sys/bus/pci/devices/{bus-info}/numa_node | 通过PCI总线地址查询对应硬件NUMA节点编号,适配多网卡同PCI设备场景,快速梳理NUMA,支撑硬件精准定位。 | {bus-info}为PCI总线地址。 |
watch -n 0.1 "netstat -antp" | 高频监测TCP连接与进程占用端口,即每0.1秒刷新一次,实时查看全量TCP连接状态、端口、对应进程PID/程序名,用于排查端口被占用、业务连接暴涨、异常外联等问题。 | -n表示不解析域名加速输出。 |
7 BIOS性能分析
查看BIOS当前的配置项信息,可以及时了解和调整硬件底层参数,排查硬件故障和问题定位。您如果不希望重启服务器,可以登录iBMC,进入首页后单击“一键采集”。
解压采集数据后进入文件夹,按照下面的路径查看文件,即可获取全量BIOS配置项开关情况。
BIOS采集数据路径:dump_info\AppDump\bios\1\currentvalue.json
有的BIOS版本没有1这个文件夹,路径为dump_info\AppDump\bios\currentvalue.json。
8 perf性能分析
perf是Linux下的一款性能分析工具,能够进行函数级与指令级的热点查找。perf由一个叫“Performance counters”的内核子系统实现,基于事件采样原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能剖析,可用于性能瓶颈的查找与热点代码的定位,可以参考perf学习资料了解更多信息。
perf通过系统调用sys_perf_event_open陷入到内核中,内核根据perf提供的信息在PMU(Performance Monitoring Unit)上初始化一个硬件性能计数器PMC(Performance Monitoring Counter)。
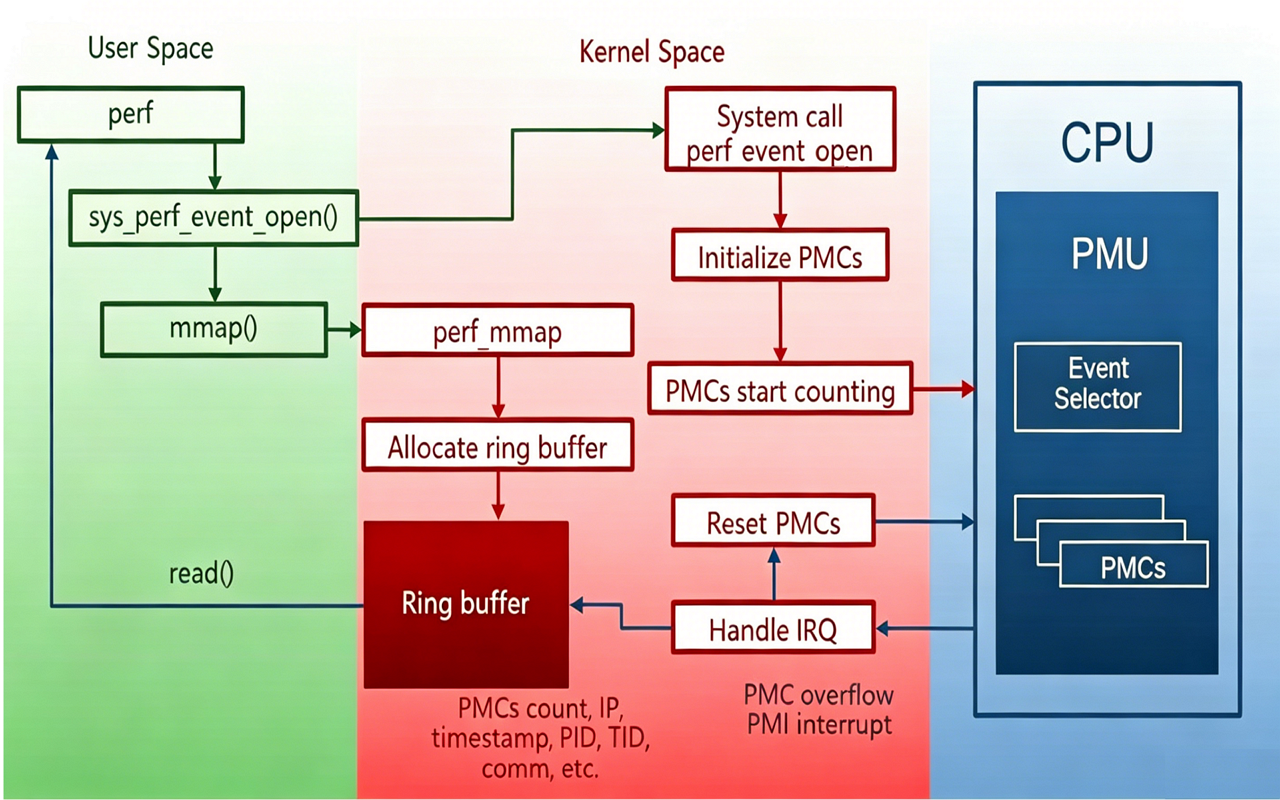
perf支持两种模式:计算模式和采样模式,perf stat使用的是计数模式,perf record使用的是采样模式。
perf共22种子命令,常用的命令如表8-1所示。
表8-1 perf常用的五种命令
命令 | 功能 | 参数说明 |
perf list | 查看当前软硬件环境支持的性能事件。 | 无 |
perf stat | 分析指定程序的性能概况。 | l -e <event>:指定性能事件(可以是多个,用,分隔列表)。 l -p <pid>:指定待分析进程的pid(可以是多个,用,分隔列表)。 l -t <tid>;:指定待分析线程的tid(可以是多个,用,分隔列表)。 l -a:从所有CPU收集系统数据。 l -d:打印更详细的信息,可重复3次。 − -d:L1 和 LLC data cache − -d -d:dTLB 和 iTLB events − -d -d -d:增加 prefetch events l -r <n>;:重复运行命令n次,打印平均值。n设为0时无限循环打印。 l -c <cpu-list>:只统计指定CPU列表的数据,如:0,1,3或1-2。 l -A:与-a选项联用,不要将CPU计数聚合。 l -I <N msecs>:每隔N毫秒打印一次计数器的变化,N最小值为100毫秒。 |
perf top | 实时显示系统或进程的性能统计信息。 | l -e <event>:指明要分析的性能事件。 l -p <pid>:仅分析目标进程及其创建的线程。 l -k <path>:带符号表的内核映像所在的路径。 l -K:不显示属于内核或模块的符号。 l -U:不显示属于用户态程序的符号。 l -d <n>:界面的刷新周期,默认为2s。 l -g:得到函数的调用关系图。 |
perf record | 记录一段时间内系统或进程的性能事件到perf.data文件。 | l -e <event>:指定性能事件(可以是多个,用,分隔列表)。 l -p <pid>:指定待分析进程的 pid(可以是多个,用,分隔列表)。 l -t <tid>:指定待分析线程的 tid(可以是多个,用,分隔列表)。 l -u <uid>:指定收集的用户数据,uid为名称或数字。 l -a:从所有 CPU 收集系统数据。 l -g:开启 call-graph(stack chain/backtrace)记录。 l -C <cpu-list>:只统计指定CPU列表的数据,如:0,1,3或1-2。 l -r <RT priority>:perf程序以SCHED_FIFO实时优先级RT priority运行这里填入的数值越大,进程优先级越高(即nice值越小)。 l -c <count>: 事件每发生count次采一次样。 l -F <n>:每秒采样n次。 l -o <output.data>:指定输出文件output.data,默认输出到perf.data。 |
perf report | 读取perf record生成的perf.data文件,并显示分析数据。 | 无 |
9 线程&进程函数调用分析
pstack是Linux下查看进程线程栈、函数调用堆栈的工具,主要用于分析进程卡死、死锁、阻塞、线程异常等问题。
执行pstack $(pidof xxx)命令,查看应用中所有线程或进程堆栈调用情况。其中xxx是应用名称,执行该命令前需启动应用。
执行pstack $(pid)命令,直接指定已知进程ID,查看单个进程的线程调用栈。
10 系统调用分析
strace是Linux系统调用跟踪工具,用于统计指定进程正在调用的系统调用、信号的执行次数、耗时、调用占比,以汇总统计报表形式输出,不打印单条系统调用详情,用于分析进程性能瓶颈,排查进程故障问题等。
执行strace -c -p $pid命令,查看进程调用了哪些内核方法,参数说明如表10-1所示。
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
70.23 10.245678 1200 8538 123 read
20.15 2.943210 800 3672 45 write
9.62 1.402100 300 4673 0 poll
------ ----------- ----------- --------- --------- ----------------
100.00 14.590988 16883 168 total表10-1 strace命令参数说明
参数 | 含义 |
-c | 开启统计汇总模式,不再逐行打印每条系统调用,而是汇总所有系统调用的调用次数、总耗时、单次平均耗时、占比,最后输出统计表。 |
-p $pid | 跟踪指定进程。 |
回显信息中参数说明如下:
- % time:该系统调用耗时占总耗时百分比(最关键,定位耗时大户)。
- seconds:该类系统调用累计总耗时。
- usecs/call:单次调用平均耗时(微秒)。
- calls:该系统总调用次数。
- errors:该调用产生的错误次数(如文件不存在、权限不足)。
- syscall:系统调用名称(如read/write/poll/recv等)。
11 TopDown分析
TopDown(自顶向下)是从整体到局部、从高层到底层的拆解分析方法,多用于系统架构、性能分析、故障排查、代码架构、业务分层,也是Linux性能调优、运维排障、软件设计的主流思路。具体微架构信息采集方法可以参考《鲲鹏DevKit用户指南》中的“微架构分析”。
TMA(Top‑down Microarchitecture Analysis,自顶向下微架构分析)层级框图第一层是四大类Retiring、Bad Speculation、Frontend Bound、Backend Bound。
实际上占比高的一般都会落到Frontend或者Backend,这两块是系统一直存在的瓶颈。下面具体对这两块展开分析。
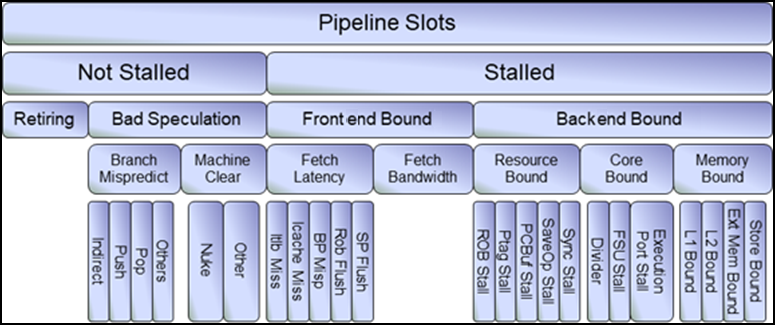
Frontend Bound占比高
前端占比高,就是前端生成微操作的速度赶不上后端处理的速度,导致了流水线的阻塞。
Frontend Bound分为Latency和Bandwidth两个子类,分别表示由于前端Latency过大的导致没有uops发送到后端的比重,和由于前端解码能力羸弱导致前端不能充分利用四发射的带宽的比重。Bandwidth和芯片能力相关,这个是硬件的瓶颈,软件优化一般不用关注。重要的是Fetch Latency这个指标。
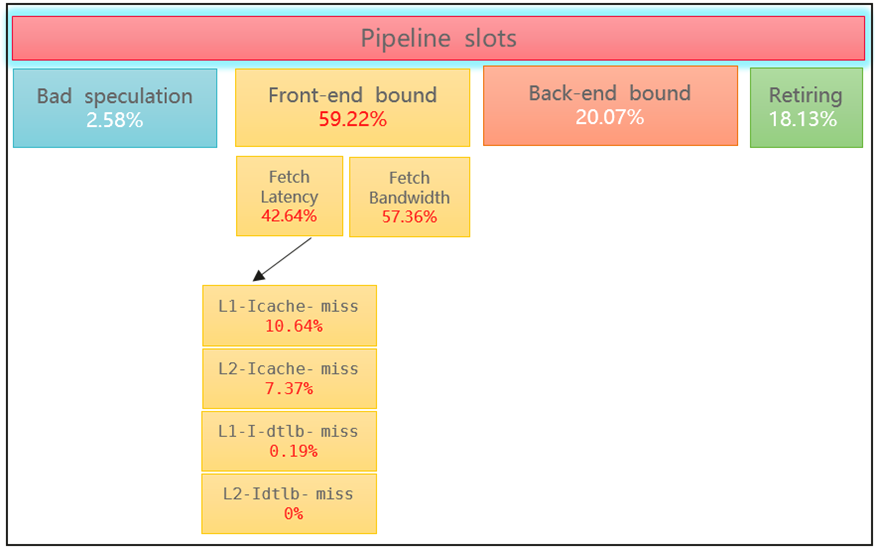
对于Fetch Latency,主要看I-Cache-miss和I-TLB-miss这两类指标。
I-Cache-miss
一旦发生instruction cache miss,Frontend没有Instruction去做解码,必然会导致没有相应的uops发往后端,导致Frontend Latency出现瓶颈。
指令的Cache-Miss高,从代码层面分析,主要原因是:
- 过多的函数跳转,导致流水线预取的指令没有作用。
- 函数间在Cache-way冲突。如果一个流程中跨模块的函数过多,很有可能因为Cache容量的问题,产生Cache-way的冲突。
这个对应的优化工具和方案有:
- 函数重排,将主流程函数链的函数从内存上布局在一起,减少函数在内存上的跨越访问。
- 单亲函数内联化,将必然调用的函数收缩到一个函数,减少函数的跳转。
- 减少不必要的函数跳转。有一些函数进入后就一个简单判断,就立即返回。
I-TLB-miss
TLB的阻塞占比一般都是很低的,但是需要注意,如果该指标占比超过1%,就要引起关注。说明TLB的阻塞已经很严重了,需要考量增加页的大小。
Backend Bound占比高
Backend Bound又细分为Resource Bound、Core Bound、Memory Bound。
- Resource Bound统计的是等候执行资源释放损耗的时间。
- Core Bound指的是执行计算单元可用,但是数据有依赖性,无法并发的损耗时间。
- Memory Bound指的是执行计算单元可用,但是内存子系统无法及时提供数据导致的损耗时间。一般性能优化就关注Memory Bound这一块,分析核心性能瓶颈是在L1/L2 bound,还是在Ext bound。
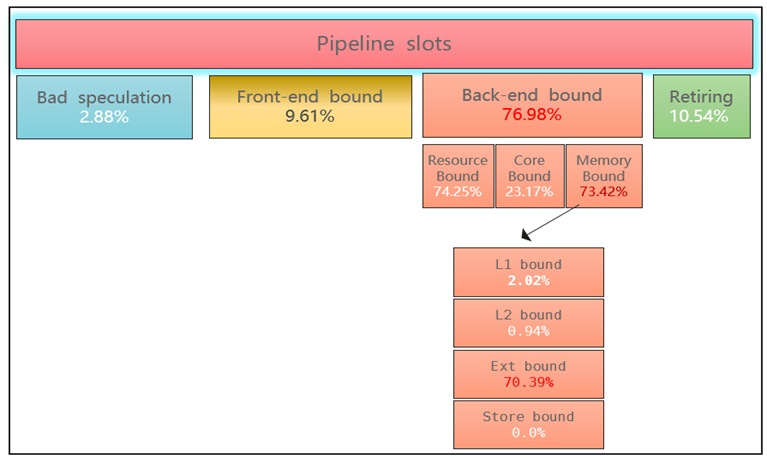
- 对于L1/L2 bound占比较高的情况,表明数据在L2就兜住了。那表明当前程序存在大量的访存操作,但这些数据基本都在Cache系统里面。
- 对于Ext bound占比较高的情况,表明数据在Cache系统没有兜住,存在的主要原因就是“又多又冷”。
- 访存的Cacheline数比较多。
- 访问的数据都是冷数据(用户级别),较长时间才会使用到,导致被Cache系统兜住的概率很小。
对应的解决方案:
- 数据预取,提前将数据准备好,减少在这一块的时间阻塞。
- 减少不必要的DDR访问。类似一些全局变量的维测,不需要的,可以删除。
- 提高DDR的访问效率。
− 空间上的访问集中。结构体字段零碎的分布在不同的Cacheline上面,一个流程下来,就会导致较多的Cacheline需要被访问到。如果将访问的结构体字段集中在少量的Cacheline上面,就会降低总体访存的开销。
− 时间上的访问集中。将时间上的离散访问修改为时间上的集中访问,这样就可以避免Cache因为过长时间的再次访问,之前的数据已经被刷出Cache,需要重新加载。