


Neon Serverless PostgreSQL:面向 Agent 数据生命周期的架构演进
发表于 2026/06/23
0
Neon Serverless PostgreSQL:面向 Agent 数据生命周期的架构演进
摘要
Neon数据库通过创新的存算分离架构重新定义了数据库边界,解决了传统PostgreSQL在数据管理、版本切换和分支创建等方面的痛点。Neon的核心架构包括Compute Node、Pageserver和Safekeeper三个组件,其中Compute Node实现了秒级启动和Scale-to-zero的能力,Pageserver负责数据的存储和版本管理,而Safekeeper则通过Paxos共识算法确保事务的快速提交。Neon的存算分离架构使得分支创建只需复制指针,版本切换仅需1秒,极大提升了开发效率和资源利用率。此外,Neon还支持弹性扩展,计算层可以灵活调整,而存储层保持不变,从而降低了成本。Neon特别适合AI Agent等需要频繁切换数据版本和快速回溯的应用场景。
开篇:Agent 开发中的"数据噩梦"
如果你是个 AI Agent 开发者,你可能已经感受到了"数据焦虑"——不仅来自 Agent 运行时的数据管理,更来自开发过程中的数据版本管理。
典型场景:需要切换到昨天的数据版本测试一个 bug
传统 PostgreSQL 的操作流程:
# 步骤 1-6,耗时 30-60 分钟
1. 找到昨天的备份文件 (可能几 GB)
2. 停止当前数据库实例
3. pg_restore 导入备份 (等待 10-30 分钟)
4. 重新配置应用连接
5. 启动数据库
6. 测试完成后反向操作恢复更糟糕的是 CI/CD pipeline:每次构建都要 pg_dump + pg_restore,5-10 分钟的等待让开发者生产力被浪费。
分支创建代价:传统方案需要完整复制数据,10GB × N 个分支 = N × 10GB 存储,时间和成本双重浪费。
Neon 的解决方案:
# 创建分支:< 1 秒
cargo neon timeline branch --branch-name test_env --ancestor-branch-name main
# Created branch 'test_env', storage: zero-copy
# 基于时间点恢复版本:< 1 秒
cargo neon timeline branch --branch-name test_env --ancestor-branch-name main --ancestor-start-lsn '<LSN>'
# Restored to historical timestamp
# 删除分支:一键清理
curl -X DELETE '<BRANCH_STRAT_TIMELINEID>'| 操作 | 传统 PostgreSQL | Neon | 提升 |
|---|---|---|---|
| 创建分支 | 5-10 分钟 | < 1 秒 | 600x |
| 版本切换 | 30-60 分钟 | < 1 秒 | 3600x |
| 存储成本 | GB × 分支数 | 共享历史 | 零复制 |
一、架构核心:存算分离
Neon 的根本创新是将 PostgreSQL 的存储层剥离,实现真正的存算分离。
传统 PostgreSQL 的瓶颈
PostgreSQL 的存储层与计算层耦合:启动必须加载本地数据文件,扩展必须迁移数据,分支必须完整复制。
Neon 的三层架构
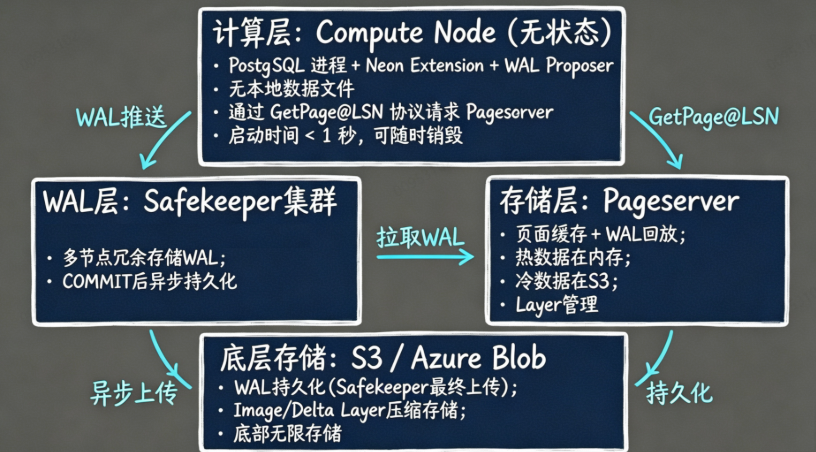
关键洞察:
- Compute Node 无状态 → 可秒级启动/停止 → Scale-to-zero 可行
- Safekeeper Paxos 共识 → Quorum 确认 → COMMIT 不等 S3
- Pageserver 有状态 → 数据永远在线 → Branching 只需复制指针
二、Compute Node:无状态的计算层
Compute Node 是 Neon 架构中最容易理解的部分——它就是一个"瘦身版"的 PostgreSQL。
2.1 传统 PostgreSQL 启动慢的根本原因
传统 PostgreSQL 启动为什么需要几分钟?因为必须加载本地数据文件。
假设你有一个 10GB 的数据库:
- PostgreSQL 启动时,需要扫描数据目录
- 加载关键元数据文件(pg_control、pg_filenode.map 等)
- 初始化缓冲池(shared_buffers)
- 这个过程需要读取大量文件,耗时 3-5 分钟
瓶颈所在:存储层与计算层耦合,启动必须加载存储。
2.2 Compute Node 如何做到秒级启动
Neon 的做法很简单:把数据文件拿走,放到远程存储(Pageserver)。
Compute Node 启动流程:
1. 启动 PostgreSQL 进程(空壳)
2. 加载 Neon Extension(替换存储管理器)
3. 连接 Safekeeper,获取 bootstrap 信息(几 KB)
4. 开始服务请求
总耗时 < 1 秒关键:Compute Node 本地没有任何数据文件,只保留一个连接配置(neon.safekeepers)。
2.3 Compute Node 的两个核心改动
Neon 对 PostgreSQL 做了两处核心修改:
改动一:Neon Extension (pgxn/neon/)
PostgreSQL 有一个"存储管理器 API"(Storage Manager Interface,简称 smgr)。这个 API 定义了如何读取和写入页面。
传统 PostgreSQL 的 smgr 实现:从本地磁盘文件读取。
Neon Extension 的 smgr 实现:通过网络请求 Pageserver。
// 传统 PostgreSQL 的页面读取
smgr_read(relation, block) {
// 从本地文件读取
return read_from_disk(relation_file, block_offset);
}
// Neon Extension 的页面读取
smgr_read(relation, block, lsn) {
// 通过网络请求 Pageserver
return request_pageserver("GetPage@LSN", relation, block, lsn);
}改动二:WAL Proposer
传统 PostgreSQL 写入 WAL 到本地磁盘,等待本地 fsync 完成后才 COMMIT。
Compute Node 没有本地磁盘,所以需要一个"推送器"把 WAL 发送到远程。
WAL Proposer 是一个后台进程,运行在 PostgreSQL 内部:
- 审视 PostgreSQL 生成的 WAL
- 连接 Safekeeper 集群
- 推送 WAL,等待 Quorum 确认
- 收到确认后,通知 PostgreSQL 可以 COMMIT
2.4 Compute Node 为什么能做到 Scale-to-zero
Scale-to-zero 的本质是:数据库在空闲时暂停,有请求时恢复。
传统 PostgreSQL 不能 Scale-to-zero:
- 暂停后,本地数据文件还在,占用存储
- 恢复时,需要重新加载本地数据文件,耗时几分钟
Compute Node 可以 Scale-to-zero:
- 暂停后,本地没有任何数据,不占用存储
- 暂停期间,Safekeeper & Pageserver 仍然在线,保持数据
- 恢复时,只需重新启动 PostgreSQL 进程,连接 Safekeeper,< 1 秒
这就是存算分离的威力:计算层可以随意启停,存储层永远在线。
三、Pageserver:存储服务核心
Pageserver 是 Neon 的"心脏",负责数据的存储、检索、版本管理。
3.1 Pageserver 解决了什么问题
传统 PostgreSQL 的存储层有两个问题:
- 扩展困难:单机存储,增加容量需要迁移数据
- 分支昂贵:创建分支需要完整复制数据
Pageserver 通过"分层存储 + 远程持久化"解决了这两个问题。
3.2 Pageserver 的三层架构
Pageserver 内部有三层设计,层层递进:
第一层:页面缓存(Page Cache)
这是最热的数据。Compute Node 最近访问的页面,放在内存中。
┌─────────────────────────────────┐
│ Layer 存储 (本地磁盘) │
│ ─────────────────────────── │
│ │
│ Image Layer (L0): │
│ - 页面 1-100 的完整快照 │
│ - 时间点:LSN = 0/100 │
│ │
│ Delta Layer (L1): │
│ - WAL 记录:LSN 101-200 │
│ - 页面 1 的变更 │
│ - 页面 3 的变更 │
│ │
│ 响应时间:~10-50ms │
└─────────────────────────────────┘重建页面的过程:
- 找到最近的 Image Layer(页面 1 的完整快照)
- 应用 Delta Layer(页面 1 的所有变更)
- 得到目标版本的页面
第三层:S3 / Azure Blob
这是冷数据。Image Layer 和 Delta Layer 最终压缩上传到云端。
┌─────────────────────────────────┐
│ S3 / Azure Blob (云端) │
│ ─────────────────────────── │
│ │
│ 压缩存储: │
│ - Image Layer 压缩为 tar.gz │
│ - Delta Layer 合并入 Image │
│ │
│ 底部无限存储,成本极低 │
│ │
│ 响应时间:~100-500ms │
└─────────────────────────────────┘3.3 GetPage@LSN:Pageserver 的核心协议
Pageserver 如何响应 Compute Node 的请求?
请求格式:
GetPage@LSN(relation=12345, block=42, lsn="0/16F9A00")
含义:给我 relation 12345 的第 42 个页面,版本是 LSN 0/16F9A00处理流程:
- 检查 Page Cache,如果命中 → 直接返回(~1ms)
- 如果未命中 → 从 Layer 重建:
- 如果 Layer 未命中 → 从 S3 下载,再重建
3.4 为什么 Pageserver 能做到秒级分支
传统 PostgreSQL 创建分支:复制所有数据文件,10GB → 10GB 复制,30 分钟。
Pageserver 创建分支:只创建一个"指针"。
main timeline:
LSN: 0 → 100 → 200 → 300 → 400 → 500 ...
创建分支 migration_check,指向 LSN = 200:
migration_check timeline:
指针:从 LSN 200 开始分叉
共享:main 的 LSN 0-200 数据(零复制)
独立:LSN 201+ 的新写入分支开销:
- 传统 PostgreSQL:完整复制,GB级存储,分钟级耗时
- Neon:创建指针 + 共享历史,KB级存储,秒级耗时
四、Safekeeper:WAL 共识服务
Safekeeper 是 Neon 最难理解的部分,但也是最关键的部分——它决定了事务何时可以 COMMIT。
4.1 为什么不能等 Pageserver 确认
传统 PostgreSQL 写入流程:
1. 执行 INSERT/UPDATE
2. 生成 WAL 记录
3. 写入本地磁盘
4. fsync 确认
5. COMMIT如果 Compute Node 等待 Pageserver 确认:
1. 执行 INSERT/UPDATE
2. 生成 WAL 记录
3. 发送到 Pageserver
4. 等待 Pageserver 接收并持久化(可能需要上传 S3)
5. COMMIT问题:Pageserver 是单点,可能延迟 100-500ms(如果需要从 S3 下载数据)。这会让事务 COMMIT 变得很慢。
4.2 Safekeeper 的解决方案:Paxos 共识
Safekeeper 是一个"临时停车场"——WAL 先停在这里,等 Pageserver 来取。
关键设计:
- Safekeeper 集群有 3+ 个节点
- 使用 Paxos 共识算法
- 多数节点确认后,事务就可以 COMMIT
- Pageserver 后续来拉取 WAL,最终上传 S3
┌───────────────────────────────────────────────────────┐
│ Safekeeper 集群(3节点) │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ SK-1 │ │ SK-2 │ │ SK-3 │ │
│ │ │ │ │ │ │ │
│ │ 收到 WAL │ │ 收到 WAL │ │ │ │
│ │ ✓ │ │ ✓ │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │
│ Quorum = 2:SK-1 和 SK-2 确认,达成共识 │
│ │
│ → 事务可以 COMMIT │
│ │
│ Pageserver 后续从 SK-1/SK-2 拉取 WAL │
│ → 最终上传 S3 │
└───────────────────────────────────────────────────────┘4.3 Paxos 共识的通俗解释
Paxos 是一个"投票机制":
- Compute Node 发送 WAL 到所有 Safekeeper
- 每个 Safekeeper 存储 WAL,回复"我收到了"
- 当收到多数回复(Quorum)后,认为 WAL 已安全存储
- 通知 PostgreSQL 可以 COMMIT
- Pageserver 后续来取 WAL
为什么 Quorum = 2 就足够:
- 如果 SK-1 和 SK-2 都存储了 WAL,即使 SK-3 崩溃,WAL 也不会丢失
- 如果 SK-1 崩溃,SK-2 和 SK-3 的 WAL 还能恢复
4.4 WAL 流向完整过程
1. Compute Node 执行 INSERT,生成 WAL 记录
│
│ WAL 推送
↓
2. Safekeeper 集群收到 WAL
│ SK-1: ✓ 存储
│ SK-2: ✓ 存储
│ SK-3: (未响应)
│
│ Quorum = 2 达成
↓
3. COMPUTE Node 收到确认,COMMIT 事务(响应客户端)
│
│ 异步(不阻塞)
↓
4. Pageserver 从 Safekeeper 拉取 WAL
│
│ 解码 WAL,应用变更到 Layer
│
↓
5. Pageserver 将 Layer 上传 S3(最终持久化)关键时间点:
- Quorum 确认
- COMMIT 响应客户端:在 Quorum 确认后立即返回
- S3 持久化:异步进行,不阻塞 COMMIT
五、三个组件的协作关系
把三个组件放在一起,看它们如何协作处理一条 SQL。
5.1 写入一条 INSERT 的完整流程
INSERT INTO users (name) VALUES ('Alice');步骤分解:
- Compute Node 执行 SQL
- PostgreSQL 解析 SQL,执行插入
- 生成 WAL 记录:
INSERT: users, name='Alice'
2. WAL Proposer 推送 WAL
- 连接 Safekeeper 集群(SK-1, SK-2, SK-3)
- 发送 WAL 到所有节点
- 等待 Quorum 确认
3. Safekeeper 共识
- SK-1 存储 WAL → 回复"收到"
- SK-2 存储 WAL → 回复"收到"
- Quorum = 2 达成 → 通知 Compute Node
4. Compute Node COMMIT
- 收到 Quorum 确认
- 返回"INSERT 成功"给客户端
- 客户端感知延迟:< 10ms
5. Pageserver 拉取 WAL(异步)
- 连接 Safekeeper
- 拉取 WAL 记录
- 解码 WAL:发现 users 表的第 X 页面有变更
6. Pageserver 更新 Layer
- 在 Delta Layer 中追加变更记录
- 如果 Delta Layer 太大,触发 Compaction
- Compaction:合并 Delta Layer 到新的 Image Layer
7. Pageserver 上传 S3(异步)
- 将新的 Image Layer 压缩上传 S3最终持久化
时间线:
客户端发起 INSERT ──→ Compute Node 执行 ──→ WAL Proposer 推送
│
│ < 10ms
↓
Safekeeper Quorum 确认 ──→ Compute Node COMMIT ──→ 响应客户端
│
│ (客户端已收到响应)
│
│ 异步,不阻塞
↓
Pageserver 拉取 WAL ──→ 更新 Layer ──→ 上传 S35.2 读取一条 SELECT 的完整流程
SELECT * FROM users WHERE id = 1;步骤分解:
- Compute Node 解析 SQL
- PostgreSQL 解析 SQL,确定需要读取 users 表的某个页面
- 计算当前 LSN(从最近的事务获取)
2. Compute Node 发送 GetPage@LSN
- 构造请求:
GetPage@LSN(relation=users, block=X, lsn=当前LSN) - 发送到 Pageserver
3. Pageserver 检查 Page Cache
- 如果命中(热数据)→ 直接返回,~1ms
- 如果未命中 → 从 Layer 重建
4. Pageserver 从 Layer 重建页面
- 找到最近的 Image Layer(LSN ≤ 目标版本)
- 应用后续 Delta Layer(所有 WAL 变更)
- 重建出目标版本的页面
- 放入 Page Cache
- 返回给 Compute Node
5. Compute Node 处理页面
- 收到页面数据PostgreSQL 从页面中提取记录返回结果给客户端
时间线:
客户端发起 SELECT ──→ Compute Node 解析 ──→ GetPage@LSN
│
│ ~1ms(缓存命中)或 ~10-50ms(Layer重建)
↓
Pageserver 返回页面 ──→ Compute Node 处理 ──→ 响应客户端六、存算分离带来的三大能力
理解了三个组件的协作,就能理解 Neon 的三大核心能力。
6.1 Scale-to-zero:计算层暂停,存储层在线
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Agent 空闲 │ ──→ │ Compute Node│ ──→ │ 暂停,不付费 │
│ │ │ 自动暂停 │ │ Pageserver │
│ 无请求 │ │ │ │ 仍在线 │
└─────────────┘ └─────────────┘ └─────────────┘
↑
│ 新请求到达
│
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Agent 响应 │ ←── │ Compute Node│ ←── │ 秒级恢复 │
│ │ │ 自动启动 │ │ < 1 秒 │
│ 处理请求 │ │ │ │ │
└─────────────┘ └─────────────┘ └─────────────┘核心原理:
- Compute Node 无本地数据 → 暂停不丢失数据
- Pageserver 有状态 → 暂停期间仍在线
- 恢复时只需重启进程,连接 Pageserver,< 1 秒
6.2 Instant Branching:只复制指针,不复制数据
main timeline:
数据: [页面1][页面2][页面3][页面4][页面5]...
LSN: 0 50 100 150 200 ...
↑
│ 分支点
│
migration_check timeline:
指针: 从 LSN 100 分叉
共享: main 的 LSN 0-100 数据(零复制)
独立: LSN 101+ 的新写入
存储开销: 10GB 共享 + KB级新数据
创建耗时: < 1 秒核心原理:
- 分支只是一个 Timeline 元数据(记录"从哪个 LSN 分叉")
- 分叉点之前的数据,通过 LSN 索引共享
- 分叉点之后的新写入,才占用新存储
6.3 弹性扩展:计算层扩容,存储层不变
Pageserver(有状态)
↑
│ GetPage@LSN
│
┌────────────────┼────────────────┐
│ │ │
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Compute │ │ Compute │ │ Compute │
│ Node 1 │ │ Node 2 │ │ Node 3 │
│ (读副本) │ │ (读副本 )│ │ (读副本) │
└─────────┘ └─────────┘ └─────────┘核心原理:
- Compute Node 无状态 → 可以创建多个
- 多个 Compute Node 连接同一个 Pageserver → 多读副本
- 存储层不变,只扩展计算层 → 成本低
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Agent 空闲 │ ──→ │ Compute Node│ ──→ │ 暂停,不付费│
│ │ │ 自动暂停 │ │ Pageserver │
│ 无请求 │ │ │ │ 仍在线 │
└─────────────┘ └─────────────┘ └─────────────┘
↑
│ 新请求到达
│
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Agent 响应 │ ←── │ Compute Node│ ←── │ 秒级恢复 │
│ │ │ 自动启动 │ │ < 1 秒 │
│ 处理请求 │ │ │ │ │
└─────────────┘ └─────────────┘ └─────────────┘七、总结:范式转换
Neon 不是"优化" PostgreSQL,而是"重构"了它的架构范式:
| 维度 | 传统 PostgreSQL | Neon Serverless |
|---|---|---|
| 设计目标 | 为人类应用设计 | 为 Agent/机器设计 |
| 启动时间 | 3-5 分钟 | < 1 秒 |
| 计费方式 | 按小时 | 按实际使用 |
| 分支创建 | 完整复制,分钟级 | 零复制,秒级 |
| 版本切换 | 恢复备份,10-60 分钟 | 指针切换,< 1 秒 |
| 存储成本 | GB × 分支数 | 共享历史,零复制 |
| 扩展方式 | 手动配置 | 自动 Autoscaling |
给 Agent 开发者的建议:
- 数据版本管理:用 Neon Branching 替代 pg_dump/pg_restore,CI 时间缩短 90%
- 弹性成本:用 Scale-to-zero 替代固定实例,Agent 空闲时不付费
- 历史回溯:用 Instant Restore 替代备份恢复,秒级回到任意版本
- 统一架构:用一个 Neon 替代 Redis + Vector DB + PostgreSQL,简化运维
Neon 的本质:把 PostgreSQL 的存储层剥离到云端,计算层变成无状态进程。当存储不再是瓶颈,计算就可以随意弹性——这才是 Agent 时代需要的数据库。
参考资料