


基于鲲鹏服务器的达梦数据库调优参考实践
发表于 2026/06/30
0
1 非商用声明
该文档提供的内容为参考实践,仅供用户参考使用,可参考实践文档构建自己的软件,按需进行安全、可靠性加固。
2 方案概述
2.1 背景
达梦数据库是使用率占比较高一款国产数据库,为了充分发挥达梦数据库在鲲鹏服务器上的性能,本参考实践基于鲲鹏服务器新型号对达梦数据库进行调优,并基于KAOT工具做了自动调优。
2.2 方案简介
本文以鲲鹏920新型号为计算底座,提供达梦数据库在鲲鹏平台上的性能调优参考指导和实践。
本参考实践部署方案是裸机部署达梦数据库,涉及到的软硬件信息如下表所示:
表1 软硬件信息
类别 | 名称 |
|---|---|
CPU型号 | Kunpeng 920 7270Z 64C@2.9GHz * 2 |
内存 | 16 * 32G DDR5 4800 MT/s |
硬盘 | 2 * NVME 硬盘 |
网络 | 25G网卡 |
操作系统 | 麒麟V10 SP3 |
数据库 | 达梦V8 |
2.3 调优方式实施
为兼顾调优效率与深度,本实践提供两种并行的实施方式供用户选择:
方式一:一键自动调优(推荐) 。为大幅简化调优流程,我们提供了自研的达梦数据库自动调优工具。该工具已将与鲲鹏硬件及达梦数据库相关的系统调优项、数据库配置文件调优项集成在工具里。用户只需运行该工具,即可实现一键式、全栈式的性能配置优化,快速提升系统及数据库性能,适用于快速部署与通用性能提升场景。
具体使用说明参考"通算一体机性能综合调优参考实践(鲲鹏自动调优工具(KAOT)简介及使用说明)":工具说明链接,也可参考数据库场景的调优指导:数据库场景使用链接。
方式二:分步手动调优。 如果您希望对每一项优化进行深度理解和控制,或需要根据业务负载进行专项调优,则可以遵循本参考实践后续章节提供的手动调优指南。该指南将详细拆解每一项优化措施的原理、操作命令、参数配置及验证方法,适合测试人员、现场实施人员和技术支持人员深度优化使用。
无论选择哪种路径,其优化的核心维度均围绕以下方面展开,具体实践细节详见第3章。
3 调优参考实践
本章按照系统优化、数据库配置文件优化、BIOS优化、数据库对象设计优化(可选)的顺序展开。其中,系统侧优化(如绑核等)通常只需调整运行环境与启动参数;数据库配置文件优化(如事务合并提交、内存缓冲区配置等)需要重启达梦数据库;BIOS优化(如SMT超线程、CPU高性能模式、CPU预取等)则需要重启服务器;数据库对象设计优化(如聚簇索引、创表时不加外键、填充因子修改)需重新构建数据库表或索引。
表1 调优手段总览
序号 | 归类 | 调优手段 | 说明 |
|---|---|---|---|
1 | 系统优化 | 绑核与NUMA亲和 | 将进程与内存约束在同一NUMA或同一socket,减少跨NUMA访问内存;鲲鹏多NUMA场景下可优先验证。 |
2 | 网卡中断绑核 | 处理网卡中断的CPU核和网卡不在一个NUMA时,会触发跨NUMA访问内存,通过绑核可减少跨NUMA的内存访问所带来的额外开销,提升网络处理性能。 | |
3 | 磁盘IO调度策略调整 | none调度策略是采用多队列块层调度器,它本质上不做任何排序,直接将I/O请求转发给设备驱动。 | |
4 | 策略性抑制swap交换内存使用 | 抑制swap交换内存使用可以保障数据库的访问性能,避免把数据库的缓冲区内存淘汰到磁盘上。 | |
5 | 数据库配置优化 | 事务合并提交优化 | 通过将多个独立事务的提交动作合并为一次磁盘写入,提升高并发下的写入吞吐。 |
6 | 内存缓冲区优化 | 调整达梦数据库内存缓存区参数,优化缓存命中率。 | |
7 | 磁盘I/O优化 | 调整达梦数据库I/O与并发线程配置,提升数据读写性能与系统并发处理能力。 | |
8 | 线程配置优化 | 调整达梦数据库工作线程与任务线程配置,提升系统并发处理能力与并行执行效率。 | |
9 | BIOS优化 | SMT超线程 | 每个物理核分为两个逻辑核,提升性能。 |
10 | CPU高性能模式 | 设置CPU运行固定运行在标称频率,无动态调频,最大化CPU性能。 | |
11 | CPU预取 | 使能硬件预取功能,提升内存访问效率。 | |
12 | 数据库对象设计优化(可选) | 聚簇索引 | 将普通表改为聚簇索引表,通常需要重建整张表。 |
13 | 创表时不加外键 | 在创表的时候,不指定外键,实现数据更新的加速。 | |
14 | 填充因子修改 | 创表时,适当减小填充因子到80%。 |
3.1 系统优化
3.1.1 绑核与NUMA亲和
1. 优化思路
NUMA架构下,处理器访问本地内存快于访问远端节点内存,跨NUMA会带来额外延迟与调度开销。鲲鹏服务器常见多socket/多NUMA,若达梦进程在不同NUMA间迁移,易出现跨访问内存、缓存失效与尾延迟抖动等现象。
亲和性(Affinity)是进程要在某个给定的CPU上尽量长时间地运行而不被迁移到其他处理器的倾向性。在多核运行的机器上,每个核本身自己会有缓存,缓存着进程使用的信息,而进程可能会被OS调度到其他核上,CPU Cache命中率就低了,当绑定核后,程序就会一直在指定的核跑,不会由操作系统调度到其他核上。这样能够大大提高CPU Cache的命中率,提高性能。
绑核的原则是优先将进程使用的CPU约束在同一NUMA;若所需核数超过单个NUMA,则尽量约束在同一颗CPU(同一socket)上。虚拟化场景下,还可结合平台的CPU独占、vNUMA/NUMA调度等能力,使vCPU与本地内存对齐。
2. 优化示例
步骤1 查看NUMA拓扑与CPU编号
需先安装工具:
yum install numactl执行以下命令查看NUMA拓扑:
numactl --hardware如下所示代表NUMA node0对应的cpu编号是0-63,CPU型号是7270Z(开启超线程),故一个NUMA有64个逻辑核:
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63步骤2 查看NUMA节点内存
实际应用场景需考虑业务应用需使用的内存,执行以下命令可查看不同NUMA节点的内存大小:
numactl --hardware如下所示代表NUMA node0对应的内存大小是128461MB,其中空闲内存109524MB:
node 0 size: 128461 MB
node 0 free: 109524 MB步骤3 绑核
(1)裸机场景绑核
裸机场景可以使用numactl工具进行绑核,如下将达梦进程绑定到NUMA 3节点的CPU和内存上:
numactl --cpunodebind=3 --membind=3 /home/dmdba/dmdbms/bin/dmserver path=/home/dmdba/dm8/data/DAMENG/dm.ini也可以绑定到具体的CPU核心,但要注意绑定的CPU核心和内存尽量在同一NUMA节点上,实际需要使用的CPU资源可视业务情况而定:
numactl --physcpubind=224-255 --membind=3 /home/dmdba/dmdbms/bin/dmserver path=/home/dmdba/dm8/data/DAMENG/dm.ini(2)虚机场景绑核
以虚拟机绑核为例,我们将虚机绑定到16-23号cpu,内存使用8G,内存绑定到NUMA node0上,需在物理机上执行以下命令修改虚拟机配置:
virsh edit <vm_name>配置示例如下:
<domain type='kvm'>
<!-- ... 其他配置,如name,memory,vcpu等 ... -->
<name>vm1</name>
<memory unit='KiB'>8388608</memory>
<currentMemory unit='KiB'>8388608</currentMemory>
<vcpu placement='static'>8</vcpu>
<!-- 1.CPU绑核 -->
<cputune>
<vcpupin vcpu='0' cpuset='16'/>
<vcpupin vcpu='1' cpuset='17'/>
<vcpupin vcpu='2' cpuset='18'/>
<vcpupin vcpu='3' cpuset='19'/>
<vcpupin vcpu='4' cpuset='20'/>
<vcpupin vcpu='5' cpuset='21'/>
<vcpupin vcpu='6' cpuset='22'/>
<vcpupin vcpu='7' cpuset='23'/>
</cputune>
<!-- 2.内存绑定 -->
<numatune>
<memnode cellid='0' mode='strict' nodeset='0'/>
</numatune>
<!-- 3.CPU模式与虚拟NUMA拓扑 -->
<cpu mode='host-passthrough' check='none'>
<numa>
<cell id='0' cpus='0-7' memory='8388608' unit='KiB'/>
</numa>
</cpu>
<!-- ... 其他配置,如devices等 ... -->
</domain>修改成功后,需执行以下命令重启虚拟机使得配置生效:
virsh shutdown <vm_name>
virsh start <vm_name>其他场景的绑核指导可参考基于容器CPU绑核与虚机QoS控制的参考实践,保障关键业务性能和稳定性-技术干货-鲲鹏社区。
3.1.2 网卡中断绑核
1. 优化思路
当网卡收到大量请求时,会产生大量的中断,通知内核有新的数据包,然后内核调用中断处理程序响应,把数据包从网卡拷贝到内存。当网卡只存在一个队列时,同一时间数据包的拷贝只能由某一个core处理,无法发挥多核优势,因此引入了网卡多队列机制,这样同一时间不同core可以分别从不同网卡队列中取数据包。
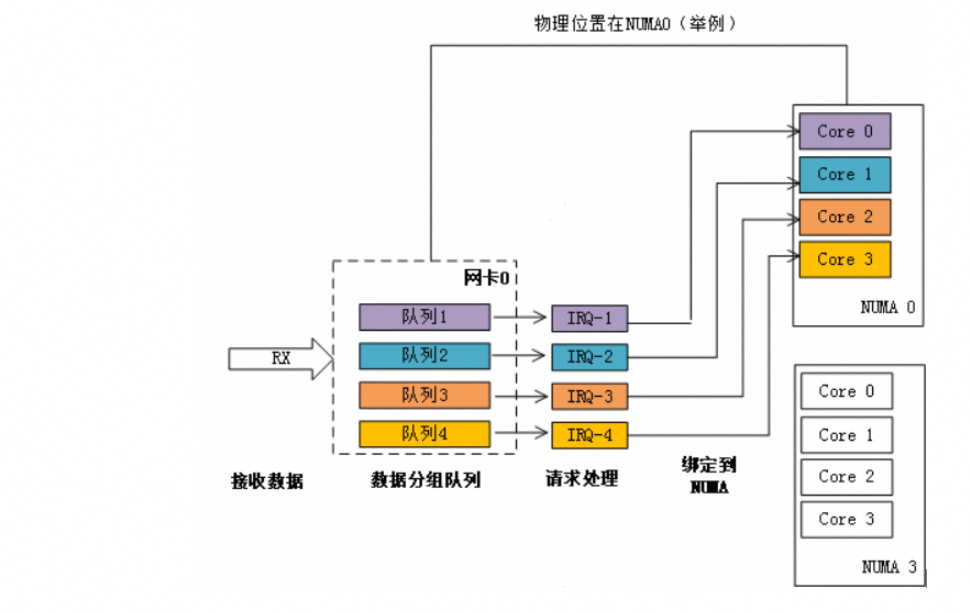
在网卡开启多队列时,操作系统通过Irqbalance服务来确定网卡队列中的网络数据包交由哪个CPU core处理,但是当处理中断的CPU core和网卡不在一个NUMA时,会触发跨NUMA访问内存。因此,我们可以将处理网卡中断的CPU core设置在网卡所在的NUMA上,从而减少跨NUMA的内存访问所带来的额外开销,提升网络处理性能。
图1 自动绑定:中断绑定随机,出现跨NUMA访问内存
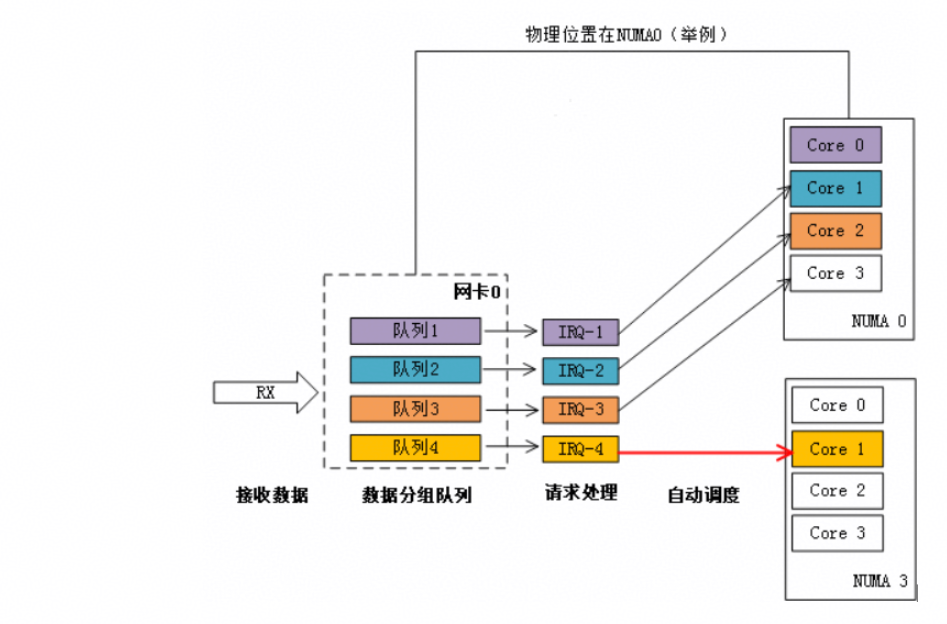
图2 NUMA绑定:中断绑定到指定核,避免跨NUMA访问内存
2. 优化示例
步骤1 停止irqbalance服务。
systemctl stop irqbalance.service步骤2 关闭irqbalance服务开机自启(可选)。
systemctl disable irqbalance.service步骤3 查看irqbalance服务状态是否已关闭,若状态为inactive即为关闭。
systemctl status irqbalance.service步骤4 网卡中断绑核。
执行以下命令查看UP状态的网卡:
ip link show | grep "UP mode"以网卡enp65s0f1为例,如下是网卡中断绑核流程:
执行以下命令查看中断数量:
ethtool -l enp65s0f1 | grep Combined执行以下命令查看网卡所在NUMA,建议网卡中断绑定的CPU与网卡在同一个NUMA:
cat /sys/class/net/enp65s0f1/device/numa_node执行以下命令查看NUMA节点对应的CPU:
numactl --hardware执行以下命令查看的网卡的总线信息:
ethtool -i enp65s0f1 | grep bus-info根据以下内容创建irq.sh脚本,并将脚本中第十行修改为上述命令查询到的网卡总线信息,然后执行以下命令进行网卡中断绑核:
sh irq.sh bind enp65s0f1 64 '160-191'注:此处的enp65s0f1为网卡名称,64为中断数量,'160-191' 为要用于绑定网卡中断的CPU编号,与网卡在同一个NUMA。
#!/bin/bashs
# chkconfig: - 50 50
# description: auto irq
# 使用举例:
# sh irq.sh 默认将192.168网卡队列深度设置为48并绑定到网卡所在cpu前48core
# sh irq.sh check eth1 读取网卡绑核信息
# sh irq.sh bind enp65s0f1 64 '160-191' 完整参数,将eth1队列深度修改为64,并循环绑定到160-191'32个核上,其中cpu支持范围参数,如'1-3,6,7-9'
bus_info=""
#获取网卡所在cpu
function get_default_cpu(){
eth_numa_node=`cat /sys/class/net/${eth}/device/numa_node`
numa_nodes=`lscpu | grep node\(s | awk '{print $NF}'`
cpus=`lscpu | grep CPU\(s | head -1 | awk '{print $NF}'`
sockets=`lscpu | grep Socket\(s | awk '{print $NF}'`
cpus_per_socket=`lscpu | grep Core\(s | awk '{print $NF}'`
numa_per_socket=$((${numa_nodes} / ${sockets}))
eth_socket=$((${eth_numa_node} / ${numa_per_socket}))
first_cpu=$[$[$[${cpus_per_socket}*${eth_socket}]]]
last_cpu=$[$[${cpus_per_socket}*$[${eth_socket}+1]]-1]
cpurange="${first_cpu}-${last_cpu}"
}
#根据参数获取cpu队列
function get_cpu_list(){
IFS_bak=$IFS
IFS=','
cpurange=($1)
IFS=${IFS_bak}
cpulist_arr=()
n=0
for i in ${cpurange[@]};do
start=`echo $i | awk -F'-' '{print $1}'`
stop=`echo $i | awk -F'-' '{print $NF}'`
for x in `seq $start $stop`;do
cpulist_arr[$n]=$x
let n++
done
done
}
#中断绑核
function bind(){
echo ${cnt}
ethtool -L ${eth} combined ${cnt}
#irq=`cat /proc/interrupts| grep ${eth} | awk -F ':' '{print $1}'`
irq=`cat /proc/interrupts| grep "$bus_info" | awk -F ':' '{print $1}'`
i=0
for irq_i in $irq
do
if [ $i -ge ${#cpulist_arr[*]} ]; then
i=0
fi
echo ${cpulist_arr[${i}]} "->" $irq_i
echo ${cpulist_arr[${i}]} > /proc/irq/$irq_i/smp_affinity_list
let i++
done
}
#读取网卡绑定cpu信息
function check(){
ethtool -l $eth
#irq=`cat /proc/interrupts | grep ${eth} | awk -F ':' '{print $1}'`
irq=`cat /proc/interrupts| grep "$bus_info" | awk -F ':' '{print $1}'`
for irq_i in $irq
do
cat /proc/irq/$irq_i/smp_affinity_list
done
}
[[ $2 ]] && eth=$2 || eth=`ifconfig | grep -B 1 "192.168" | head -1 | awk -F":" '{print $1}'`
echo "$eth"
[[ $3 ]] && cnt=$3 || cnt=48
[[ $4 ]] && cpurange=$4 || get_default_cpu
get_cpu_list $cpurange
[[ $1 ]] && $1 || bind3.1.3 磁盘IO调度策略调整
1. 优化思路
磁盘调度策略根据不同场景设置,在固态硬盘场景下,建议使用none,deadline次之。在固态硬盘场景下,空调度(none)通过消除请求重排与调度开销,充分利用SSD无寻道延迟的特性,显著降低延迟并节约CPU资源。
2. 优化示例
执行以下命令查询磁盘:
lsblk以NVMe盘nvme0n1为例,执行以下命令修改:
echo none > /sys/block/nvme0n1/queue/scheduler3.1.4 策略性抑制swap交换内存使用
1. 优化思路
调整内核参数,系统仍保留swap但几乎不使用(除非内存耗尽)。抑制swap交换内存使用可以保障数据库的访问性能,避免把数据库的缓冲区内存淘汰到磁盘上。 如果服务器内存比较小,内存不足时仍可少量使用swap缓冲,避免出现内存溢出的问题。
2. 优化示例
步骤1 编辑sysctl配置文件:
sudo vim /etc/sysctl.conf步骤2 在文件末尾添加参数:
vm.swappiness=0步骤3 通过以下命令(或重启系统)使配置生效并持久化:
sudo sysctl -p3.2 数据库配置优化
3.2.1 事务合并提交优化
1. 优化思路
事务合并提交是一种数据库I/O优化策略,它允许数据库在一次磁盘操作中提交多个事务,而不是为每一个事务单独执行一次磁盘I/O操作。
通过将多个独立事务的提交动作合并为一次磁盘写入,从而将原本高频、零碎的写入操作转化为低频、批量的大块写入,从而提升高并发下的写入吞吐。
表1 事务合并提交配置参数
参数类别 | 参数名 | 含义 | 建议值 |
|---|---|---|---|
事务合并 | COMMIT_BATCH | 事务提交时合并刷盘的重做日志批次大小(单位为日志块个数) | 批次越大,每个事务需要等待的时间可能越长,导致事务提交的延迟增加,建议根据实际业务场景设置。 |
COMMIT_BATCH_TIMEOUT | 事务提交时等待合并刷盘的最大超时时间(单位:毫秒) | 防止因并发过小导致事务提交的时间过长,建议根据实际业务场景设置。 |
2. 优化示例
修改达梦dm.ini配置文件(默认位于达梦数据库初始化路径下的DAMENG文件夹里),找到COMMIT_BATCH和COMMIT_BATCH_TIMEOUT字段并修改,如下所示:
COMMIT_BATCH = 32 #Transaction commit redo log batch flush
COMMIT_BATCH_TIMEOUT = 5 #Transaction commit redo log batch flush wait time修改完成后需重启数据库,才能使配置生效。
3.2.2 内存缓冲区优化
1. 优化思路
调整达梦数据库内存缓存区参数,优化缓存命中率。可以配置的参数有内存池参数、数据缓冲区参数和RECYCLE缓冲区参数。
表1 内存缓冲区配置参数
参数类别 | 参数名 | 含义 | 建议值 |
|---|---|---|---|
内存池 | MAX_OS_MEMORY | 数据库可占用的最大操作系统内存百分比 | 建议设置为90,预留10%给操作系统。 |
MEMORY_POOL | 共享内存池初始大小(单位:MB) | 建议设置为可用内存的25%,可适当增大初始值。 | |
MEMORY_TARGET | 共享内存池扩展后收缩回的目标大小(单位:MB) | 建议与MEMORY_POOL保持一致。 | |
缓冲区 | BUFFER | 系统缓冲区大小(MB) | 建议设置为可用内存的50%,预留足够的系统缓冲区空间。 |
BUFFER_POOLS | 缓冲区池数量 | 建议略高于可用CPU核数,且为质数。 |
2. 优化示例
以内存大小为512G、CPU核数为64个逻辑核为例,修改达梦dm.ini配置文件(默认位于达梦数据库初始化路径下的DAMENG文件夹里),找到对应的字段并修改,如下所示:
MAX_OS_MEMORY = 90 #Maximum Percent Of OS Memory
MEMORY_POOL = 128000 #Memory Pool Size In Megabyte
MEMORY_TARGET = 128000 #Memory Share Pool Target Size In Megabyte
BUFFER = 256000 #Initial System Buffer Size In Megabytes
BUFFER_POOLS = 67 #number of buffer pools修改完成后需重启数据库,才能使配置生效。
3.2.3 磁盘I/O优化
1. 优化思路
调整达梦数据库I/O与并发线程配置,提升数据读写性能与系统并发处理能力。通过合理设置DIRECT_IO和IO_THR_GROUPS参数,优化磁盘I/O通道利用率,实现与CPU资源的高效匹配。
表1 I/O与并发线程配置参数
参数类别 | 参数名 | 含义 | 建议值 |
|---|---|---|---|
IO | DIRECT_IO | 是否启用直接I/O(绕过操作系统缓存) | 建议设置为1,提升I/O性能。 |
IO_THR_GROUPS | I/O线程组数量,控制并发I/O处理能力 | 建议与实际可用CPU核数保持一致。 |
2. 优化示例
以CPU核数为64个逻辑核为例,修改达梦dm.ini配置文件(默认位于达梦数据库初始化路径下的DAMENG文件夹里),找到DIRECT_IO和IO_THR_GROUPS字段并修改,如下所示:
DIRECT_IO = 1 #Flag For Io Mode(Non-Windows Only), 0: Using File System Cache; 1: Without Using File System Cache
IO_THR_GROUPS = 64 #The Number Of Io Thread Groups(Non-Windows Only)修改完成后需重启数据库,才能使配置生效。
3.2.4 线程配置优化
1. 优化思路
调整达梦数据库工作线程与任务线程配置,提升系统并发处理能力与并行执行效率。通过合理设置WORKER_THREADS和TASK_THREADS参数,实现与CPU资源的高效匹配,避免线程不足导致的请求排队或线程过多导致的资源争抢。
表1 工作线程与任务线程配置参数
参数类别 | 参数名 | 含义 | 建议值 |
|---|---|---|---|
thread | WORKER_THREADS | 工作线程数 | 建议与实际可用CPU核数保持一致。 |
TASK_THREADS | 任务线程数 | 建议与实际可用CPU核数保持一致。 |
2. 优化示例
以CPU核数为64个逻辑核为例,修改达梦dm.ini配置文件(默认位于达梦数据库初始化路径下的DAMENG文件夹里),找到WORKER_THREADS和TASK_THREADS字段并修改,如下所示:
WORKER_THREADS = 64 #Number Of Worker Threads
TASK_THREADS = 64 #Number Of Task Threads修改完成后需重启数据库,才能使配置生效。
3.3 BIOS优化
3.3.1 SMT超线程
1. 优化思路
开启SMT超线程,每个物理核分为两个逻辑核,提升整机性能。
注意:该调优项仅适用于鲲鹏920新型号服务器,对于其他鲲鹏服务器暂不支持该配置。
2. 优化示例
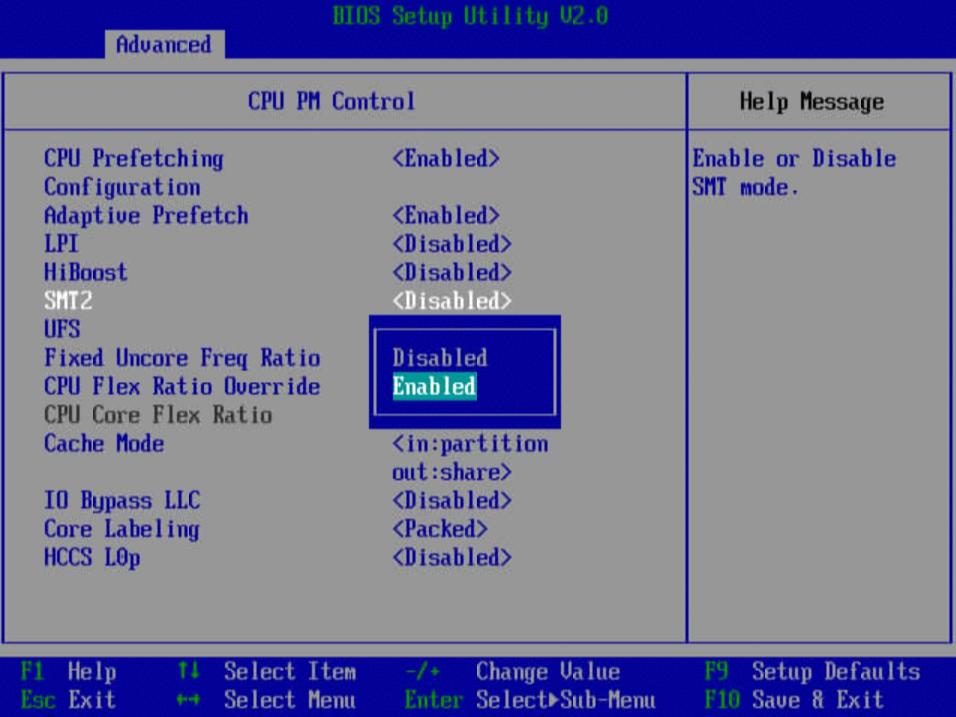
1)服务器重启,进入BIOS,依次选择“BIOS->Advanced->Power And Performance Configuration->CPU PM Control”。
2)设置“SMT2”选项为“Enabled”,按F10保存BIOS配置。
3.3.2 CPU高性能模式
1. 优化思路
CPU性能模式通常指将CPU频率固定在最高值,以最大化其性能的设置,开启CPU性能模式,无动态调频,固定在标称频率,可以提升事务处理性能。
说明:Power Policy会受Performance Profile联动配置的影响,即Performance Profile配置后,可能导致Power Policy发生变化,但支持手动修改,配置BIOS时注意保存前检查配置是否符合预期。
2. 优化示例
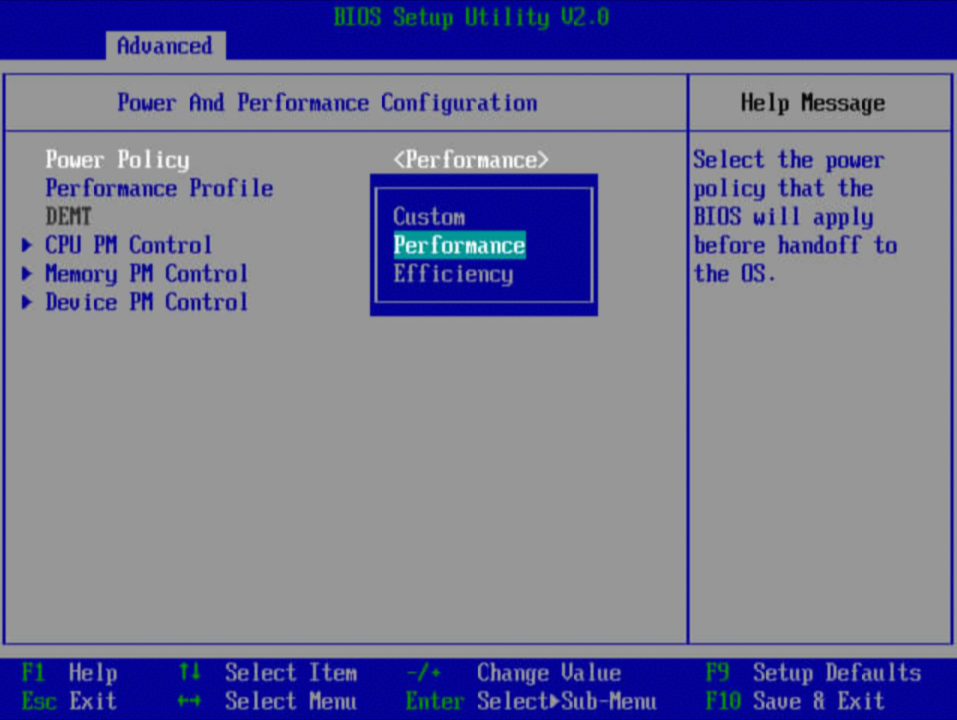
1)服务器重启,进入BIOS,依次选择“BIOS->Advanced->Power And Performance Configuration”。
2)设置“Power Policy”选项为“Performance”,按F10保存BIOS配置。
3.3.3 CPU预取
1. 优化思路
CPU将内存中的数据读到CPU的高速缓存时,会根据局部性原理,除了读取本次要访问的数据,还会预取本次数据的周边数据到Cache中,如果预取的数据是下次要访问的数据,那么性能会提升,如果预取的数据不是下次要访问的数据,那么会浪费内存带宽。
对于数据比较集中的场景,预取的命中率高,适合打开CPU预取,反之对于数据不集中的场景则需要关闭CPU预取。
2. 优化示例
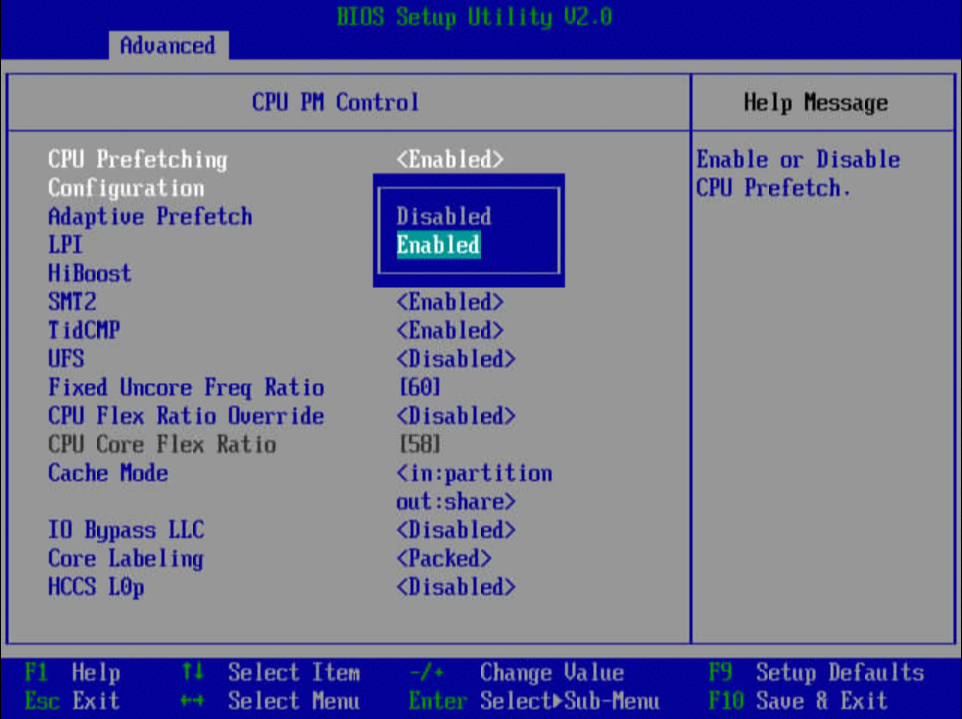
1)服务器重启,进入BIOS,依次选择“BIOS->Advanced->Power And Performance Configuration->CPU PM Control”。
2)设置CPU Prefetching为Enabled。
3.4 数据库对象设计优化(可选)
3.4.1 聚簇索引
1. 优化思路
聚簇索引是将表数据按照索引键的顺序物理存储在磁盘上的一种索引结构,它决定了表中行的物理排列次序。
聚簇索引会使得键值相邻的数据行在物理页上也相邻,从而将随机 I/O 转化为顺序 I/O,大幅提升检索性能。
基于此,优化思路是:在实际业务中,可以在创表的时候创建聚簇索引来提升性能。
2. 优化示例
说明:优化以BenchmarkSQL为例,可扩展到实际业务。
(1)进入BenchmarkSQL安装目录后,修改runDatabaseBuild.sh:
vim run/sql.common/indexCreates.sql(2)修改后内容如下:
alter table bmsql_warehouse add constraint bmsql_warehouse_pkey
cluster primary key (w_id);
alter table bmsql_district add constraint bmsql_district_pkey
cluster primary key (d_w_id, d_id);
alter table bmsql_customer add constraint bmsql_customer_pkey
cluster primary key (c_w_id, c_d_id, c_id);
create index bmsql_customer_idx1
on bmsql_customer (c_w_id, c_d_id, c_last, c_first);
alter table bmsql_oorder add constraint bmsql_oorder_pkey
cluster primary key (o_w_id, o_d_id, o_id);
create unique index bmsql_oorder_idx1
on bmsql_oorder (o_w_id, o_d_id, o_carrier_id, o_id);
alter table bmsql_new_order add constraint bmsql_new_order_pkey
cluster primary key (no_w_id, no_d_id, no_o_id);
alter table bmsql_order_line add constraint bmsql_order_line_pkey
cluster primary key (ol_w_id, ol_d_id, ol_o_id, ol_number);
alter table bmsql_stock add constraint bmsql_stock_pkey
cluster primary key (s_w_id, s_i_id);
alter table bmsql_item add constraint bmsql_item_pkey
cluster primary key (i_id);3.4.2 创表时不加外键
1. 优化思路
数据外键是一种在关系数据库中用来建立表之间关联的约束,它允许一个表(从表)中的一个或多个字段引用另一个表(主表)的主键字段。
数据外键会增加数据修改时的性能开销,需要额外校验,开发者会选择在应用层自己维护数据完整性,去除数据库外键的优势在于提升性能、简化开发、方便分布式和分库分表,可以有效降低CPU、I/O资源消耗。
基于此,优化思路是:在实际业务中,可以在创表的时候,不指定外键,实现数据更新的加速。
2. 优化示例
说明:优化以BenchmarkSQL为例,可扩展到实际业务。
(1)进入BenchmarkSQL安装目录后,修改runDatabaseBuild.sh:
vim run/runDatabaseBuild.sh(2)修改后内容如下:
#!/bin/sh
if [ $# -lt 1 ] ; then
echo "usage: $(basename $0) PROPS [OPT VAL [...]]" >&2
exit 2
fi
PROPS="$1"
shift
if [ ! -f "${PROPS}" ] ; then
echo "${PROPS}: no such file or directory" >&2
exit 1
fi
DB="$(grep '^db=' $PROPS | sed -e 's/^db=//')"
BEFORE_LOAD="tableCreates"
AFTER_LOAD="indexCreates extraHistID buildFinish"
for step in ${BEFORE_LOAD} ; do
./runSQL.sh "${PROPS}" $step
done
./runLoader.sh "${PROPS}" $*
for step in ${AFTER_LOAD} ; do
./runSQL.sh "${PROPS}" $step
done3.4.3 填充因子修改
1. 优化思路
数据库填充因子是一个介于0到100%的百分比值,它决定了创建或重建索引时,数据页被填充的程度,以便为将来的数据插入和更新预留空间。
在插入和更新操作频繁的场景下,减小填充因子,可以减少由于索引页分裂而导致的I/O开销。填充因子越小,每个数据页可以容纳的数据越少,从而有更多的空间来容纳新的数据,从而提升插入、更新以及写入性能。
基于此,优化思路是:创表时,适当减小FILLFACTOR到80。
2. 优化示例
说明:优化以BenchmarkSQL为例,可扩展到实际业务。
(1)进入BenchmarkSQL安装目录后,修改taleCreates.sql:
vim run/sql.common/taleCreates.sql(2)修改后内容如下:
create table bmsql_config (
cfg_name varchar(30) primary key,
cfg_value varchar(50)
);
create table bmsql_warehouse (
w_id integer not null,
w_ytd decimal(12,2),
w_tax decimal(4,4),
w_name varchar(10),
w_street_1 varchar(20),
w_street_2 varchar(20),
w_city varchar(20),
w_state char(2),
w_zip char(9)
)STORAGE(FILLFACTOR 80);
create table bmsql_district (
d_w_id integer not null,
d_id integer not null,
d_ytd decimal(12,2),
d_tax decimal(4,4),
d_next_o_id integer,
d_name varchar(10),
d_street_1 varchar(20),
d_street_2 varchar(20),
d_city varchar(20),
d_state char(2),
d_zip char(9)
)STORAGE(FILLFACTOR 80);
create table bmsql_customer (
c_w_id integer not null,
c_d_id integer not null,
c_id integer not null,
c_discount decimal(4,4),
c_credit char(2),
c_last varchar(16),
c_first varchar(16),
c_credit_lim decimal(12,2),
c_balance decimal(12,2),
c_ytd_payment decimal(12,2),
c_payment_cnt integer,
c_delivery_cnt integer,
c_street_1 varchar(20),
c_street_2 varchar(20),
c_city varchar(20),
c_state char(2),
c_zip char(9),
c_phone char(16),
c_since timestamp,
c_middle char(2),
c_data varchar(500)
)STORAGE(FILLFACTOR 80);
create sequence bmsql_hist_id_seq;
create table bmsql_history (
hist_id integer,
h_c_id integer,
h_c_d_id integer,
h_c_w_id integer,
h_d_id integer,
h_w_id integer,
h_date timestamp,
h_amount decimal(6,2),
h_data varchar(24)
)STORAGE(FILLFACTOR 80);
create table bmsql_new_order (
no_w_id integer not null,
no_d_id integer not null,
no_o_id integer not null
)STORAGE(FILLFACTOR 80);
create table bmsql_oorder (
o_w_id integer not null,
o_d_id integer not null,
o_id integer not null,
o_c_id integer,
o_carrier_id integer,
o_ol_cnt integer,
o_all_local integer,
o_entry_d timestamp
)STORAGE(FILLFACTOR 80);
create table bmsql_order_line (
ol_w_id integer not null,
ol_d_id integer not null,
ol_o_id integer not null,
ol_number integer not null,
ol_i_id integer not null,
ol_delivery_d timestamp,
ol_amount decimal(6,2),
ol_supply_w_id integer,
ol_quantity integer,
ol_dist_info char(24)
)STORAGE(FILLFACTOR 80);
create table bmsql_item (
i_id integer not null,
i_name varchar(24),
i_price decimal(5,2),
i_data varchar(50),
i_im_id integer
);
create table bmsql_stock (
s_w_id integer not null,
s_i_id integer not null,
s_quantity integer,
s_ytd integer,
s_order_cnt integer,
s_remote_cnt integer,
s_data varchar(50),
s_dist_01 char(24),
s_dist_02 char(24),
s_dist_03 char(24),
s_dist_04 char(24),
s_dist_05 char(24),
s_dist_06 char(24),
s_dist_07 char(24),
s_dist_08 char(24),
s_dist_09 char(24),
s_dist_10 char(24)
)STORAGE(FILLFACTOR 80);