本文的图算法测试用例使用官网数据集,请从官网下载graph500-23、graph500-24、graph500-25、cit-Patents、uk-2002、enwiki-2018、it-2004、com_orkut、usaRoad,cage14,Twitter-2010、Graph500-29。下文所有的数据集解压上传均在server1节点进行。
无向图graph500-23、graph500-24、graph500-25数据集
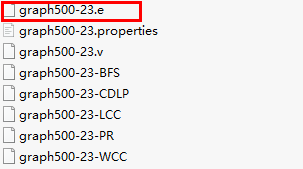
- 下载官网数据集,下载后的压缩包中包含以下样例文件,选择.e后缀的文件作为无向图的数据集。
- 默认下载后文件中的分隔符是空格(建议仍保留空格分隔符),如果需要修改分隔符为逗号,可在服务器终端使用如下命令。
cat graph500-23.e | tr “ ” “,” > graph500-23.txt
cit-Patents数据集
- 下载官网数据集。
- 下载完成后解压,然后将cit-Patents.txt文件中“#”开头的前四行删除即可使用。

有向图it-2004数据集
有向图it-2004数据集的下载使用步骤如下,下载后解压即可使用。
- 新建“/test/graph/dataset/”目录。
1 2
mkdir -p /test/graph/dataset/ cd /test/graph/dataset/
- 下载官网数据集。
wget https://suitesparse-collection-website.herokuapp.com/MM/LAW/it-2004.tar.gz
- 执行tar解压数据集。
1tar -zxvf it-2004.tar.gz
- 创建HDFS对应存放目录。
1hadoop fs –mdkir –p /tmp/graph/dataset/
- 将文件上传至HDFS。
1hadoop fs –put /test/graph/dataset/it-2004.mtx /tmp/graph/dataset/
- 检查HDFS有无数据,检查结果如下。
1hadoop fs -ls /tmp/graph/dataset/it-2004.mtx

uk-2002、enwiki-2018数据集
下载官网数据集,需要注意的是,我们只需要下载对应链接下的3个相关的文件,对应后缀分别是:.graph、 .properties、 .md5sums。
uk-2002: http://law.di.unimi.it/webdata/uk-2002/
enwiki-2018: http://law.di.unimi.it/webdata/enwiki-2018/


针对有向图uk-2002、enwiki-2018我们需要采取特定的解压缩方式,以下流程将解压uk-2002数据集为例。
- 下载WebGraph和相应的依赖包。
表1 WebGraph和相应的依赖包 项目
下载链接
logback-classic-1.1.7.jar
logback-core-1.1.7.jar
fastutil-7.0.12.jar
sux4j-4.0.0.jar
dsiutils-2.3.2.jar
jung-api-2.1.jar
jung-io-2.1.jar
jsap-2.1.jar
junit-4.12.jar
commons-configuration-1.8.jar
commons-lang3-3.4.jar
slf4j-api-1.7.21.jar
webgraph-3.5.2.jar
guava-19.0.jar
uk-2002.properties
uk-2002.graph
- 新建lib文件夹,将解压后的WebGraph和WebGraph-deps的JAR包放在lib目录下。
mkdir lib cd lib
- 回到uk-2002.properties和uk-2002.graph所在目录,运行如下命令,生成相应的解压后的文件uk-2002-edgelist.txt。
java -cp "./lib/*" it.unimi.dsi.webgraph.ArcListASCIIGraph -l 5000 uk-2002 uk-2002-edgelist.txt

最后两个参数对应输入数据和输出数据,请注意如果文件包含sample.graph、 sample.md5sums、 sample.properties,则倒数第二个参数应为前面3个文件的前缀sample。
- 默认解压后文件中的分隔符是“\t”,如果需要修改分隔符为空格,可在服务器终端使用如下命令。
cat uk-2002-edgelist.txt | tr "\t" " " > uk-2002-edgelist.e
com-orkut数据集
下载官网数据集,下载后解压即可使用。
获取链接:http://snap.stanford.edu/data/bigdata/communities/com-orkut.ungraph.txt.gz
Twitter-2010、Graph500-29数据集
- 生成增量数据集。
- 创建脚本和JAR包存放目录。
mkdir –p /test/algo/incpr
- 将下面1.c和1.d步得到的脚本和JAR包放到“/test/algo/incpr”目录下。
- 新建twitter-2010数据集增量生成脚本incDataGenBatch_twitter-2010.sh,并复制下面脚本内容到incDataGenBatch_twitter-2010.sh脚本中。
vim incDataGenBatch_twitter-2010.sh
incDataGenBatch_twitter-2010.sh
num_executors=39
executor_cores=7
executor_memory=23
partition=273
java_xms="-Xms${executor_memory}g"
class="com.huawei.graph.IncDataGeneratorBatch"
input_allData="hdfs:/tmp/graph/dataset/twitter-2010-edgelist.txt"
split=","
seed=1
iterNum=100
resetProb=0.15
jar_path="/test/algo/incpr/inc-graph-tools-1.0.0.jar"
batch=5
for rate in {0.001,0.01,0.05}
do
echo ">>> start [twitter-2010-${rate}]"
output_incData="/tmp/graph/dataset/twitter-2010_${rate}"
hadoop fs -rm -r -f hdfs:${output_incData}
spark-submit \
--class ${class} \
--master yarn \
--num-executors ${num_executors} \
--executor-memory ${executor_memory}g \
--executor-cores ${executor_cores} \
--driver-memory 80g \
--conf spark.driver.maxResultSize=80g \
--conf spark.locality.wait.node=0 \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.kryoserializer.buffer.max=2040m \
--conf spark.executor.extraJavaOptions=${java_xms} \
${jar_path} yarn ${input_allData} ${split} ${output_incData} ${rate} ${partition} ${seed} ${iterNum} ${resetProb} ${batch}
echo ">>> end [twitter-2010-${rate}]"
done
- 新建graph500-29数据集增量生成脚本incDataGenBatch_graph500-29.sh,并复制下面脚本内容到incDataGenBatch_graph500-29.sh脚本中。
vim incDataGenBatch_graph500-29.sh
incDataGenBatch_twitter-2010.sh
num_executors=39
executor_cores=7
executor_memory=23
partition=800
java_xms="-Xms${executor_memory}g"
class="com.huawei.graph.IncDataGeneratorBatch"
input_allData="hdfs:/tmp/graph/dataset/graph500-29.e"
split=","
seed=1
iterNum=100
resetProb=0.15
jar_path="/test/algo/incpr/inc-graph-tools-1.0.0.jar"
batch=5
for rate in {0.001,0.01,0.05}
do
echo ">>> start [graph500-29-${rate}]"
output_incData="/tmp/graph/dataset/graph500-29_${rate}"
hadoop fs -rm -r -f hdfs:${output_incData}
spark-submit \
--class ${class} \
--master yarn \
--num-executors ${num_executors} \
--executor-memory ${executor_memory}g \
--executor-cores ${executor_cores} \
--driver-memory 80g \
--conf spark.driver.maxResultSize=80g \
--conf spark.locality.wait.node=0 \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.kryoserializer.buffer.max=2040m \
--conf spark.executor.extraJavaOptions=${java_xms} \
${jar_path} yarn ${input_allData} ${split} ${output_incData} ${rate} ${partition} ${seed} ${iterNum} ${resetProb} ${batch}
echo ">>> end [graph500-29-${rate}]"
done
脚本关键参数说明:- input_allData代表下载的开源全量数据HDFS路径。
- jar_path代表inc-graph-tools-1.0.0.jar的绝对路径。
- batch代表生成batch个数。
- rate代表换血率。默认会生成(0.001,0.01,0.05)三个不同换血率数据,可以根据需要修改换血率,目前算法支持换血率0.05以下的性能提升。
- 创建脚本和JAR包存放目录。
- 得到twitter-2010增量模拟数据。
- 新建“/test/dataset/graph/twitter”目录,并进入该目录。
mkdir –p /test/dataset/graph/twitter cd /test/dataset/graph/twitter
- 下载官网数据集。
wget https://snap.stanford.edu/data/twitter-2010.txt.gz
- 解压数据集。
tar zxvf twitter-2010.txt.gz
- 创建“/hdfs”目录,解压得到的数据twitter-2010-edgelist.txt,上传到“/hdfs”目录上。
hdfs dfs -mkdir –p /tmp/graph/dataset hdfs dfs –put twitter-2010-edgelist.txt /tmp/graph/dataset
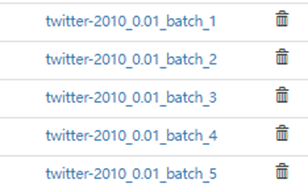
- 运行脚本得到增量模拟数据,以5个batch换血率0.001为例,HDFS得到如下数据。
- 新建“/test/dataset/graph/twitter”目录,并进入该目录。
- 生成graph500-29增量模拟数据。
- 新建“/test/dataset/graph/graph500-29”目录,并进入该目录。
mkdir –p /test/dataset/graph/graph500-29 cd /test/dataset/graph/graph500-29
- 下载官网数据集。
wget https://surfdrive.surf.nl/files/index.php/s/VSXkomtgPGwZMW4/download
- 解压数据集。
tar -I zstd -vxf graph500-29.tar.zst
- 创建“/hdfs”目录,解压得到的数据graph500-29.e,上传到“/hdfs”目录上。
hdfs dfs -mkdir –p /tmp/graph/dataset hdfs dfs –put graph500-29.e /tmp/graph/dataset
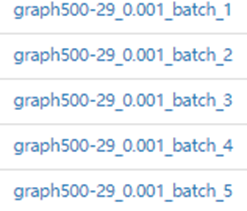
- 运行脚本得到增量模拟数据,以5个batch换血率0.001为例,HDFS得到如下数据。
- 新建“/test/dataset/graph/graph500-29”目录,并进入该目录。