本章节采用IDEA本地开发,新建一个sbt工程,调用LPA接口对开源数据进行转换,生成社区数据。
- 打开IntelliJ IDEA。在“Quick Start”页面选择“Create New Project”。或者针对已使用过的IDEA工具,您可以从IDEA主界面直接添加,选择“File > New project...”新建工程。

- 依次选择“Scala”=> "sbt",单击“Next”。
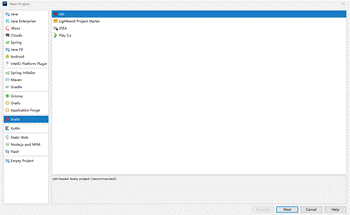
- 填写新建工程路径和名称,"JDK"下拉框选择"1.8","sbt"下拉框选择"0.13.16","Scala"下拉框选择"2.11.8",单击“Finish”,完成配置。
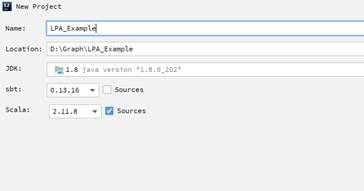
- 新建完成后,IDEA主页显示的新建工程目录如下。
- 在根目录下build.sbt文件中添加依赖,将以下内容复制替换到build.sbt中。
name := "LPA_Example" version := "0.1" scalaVersion := "2.11.8" libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "2.3.2" withSources(); libraryDependencies += "org.apache.spark" % "spark-graphx_2.11" % "2.3.2";
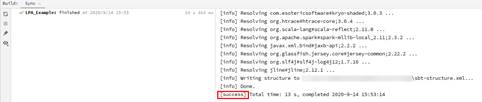
- 单击右侧边框“sbt”=>“刷新”,进行sbt工程构建。
- 在“Build”窗口出现“success”时,可以进行以下步骤。
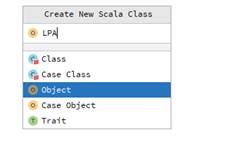
- 在新建的工程中,新建“src/main/scala/com/”目录,在其目录下新建LPA.scala文件右击“scala”目录,选择。
将以下代码复制到LPA.scala文件中。
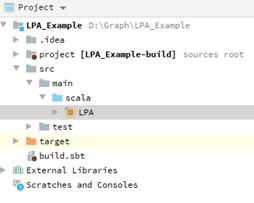
import org.apache.spark.graphx.lib.LabelPropagation import org.apache.spark.graphx.{Graph, PartitionStrategy} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD object LPA { def readFile(sc: SparkContext, inputPath: String, split: String, partitionNum: Int): RDD[(Long, Long)] = { sc.textFile(inputPath, partitionNum) .flatMap(line => { if (line.startsWith("#")) Iterator.empty else { val x = line.split(split) if (x(0).toLong > x(1).toLong) { Iterator((x(1).toLong, x(0).toLong)) } else { Iterator((x(0).toLong, x(1).toLong)) } } }).distinct() } def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setAppName("LPA").setMaster("yarn") val sc = new SparkContext(sparkConf) var inputPath = " " var split = " " var outputPath = " " var partitionNum = 1 if (args.length == 4) { inputPath = args(0) split = args(1) outputPath = args(2) partitionNum = args(3).toInt println("InputPath: " + inputPath + "\noutputPath: " + outputPath + "\npartitionNum: " + partitionNum) } else { println("Usage: <inputPath:String> " + "<split:String> <outPath:string> <partitionNum:Int>") sc.stop() sys.exit(-1) } val inputRdd = readFile(sc, inputPath, split, partitionNum) val graph = Graph.fromEdgeTuples(inputRdd, 0).partitionBy(PartitionStrategy.EdgePartition2D) val result = LabelPropagation.run(graph, 10).vertices.repartition(partitionNum) println("start to write file to hdfs") result.saveAsTextFile(outputPath) } }文件目录结构如下。
- 在sbt shell中输入“compile”,回车,进行项目编译。

- 在sbt shell中输入“package”,回车,进行项目打包,在“target\scala-2.11\”目录中生成lpa_examples_2.11-0.1.jar。
