大数据引擎多采用Java/Scala算子,无法充分发挥CPU的能力。同时,对于异构算力,也不适用或无法发挥硬件的计算性能优势。OmniOperator算子加速特性使用Native Code充分发挥硬件计算性能优势,尤其是异构算力的计算能力。
OmniOperator算子加速特性提供固定接口供用户分布式任务调用。支持用户将SQL任务提交给Spark集群,集群管理节点进行任务分配,分发多个子任务到对应的多个计算节点执行。
OmniOperator算子加速仅在单个任务中被用户代码调用,不涉及与其他子任务交互。OmniOperator算子加速架构如图1所示。
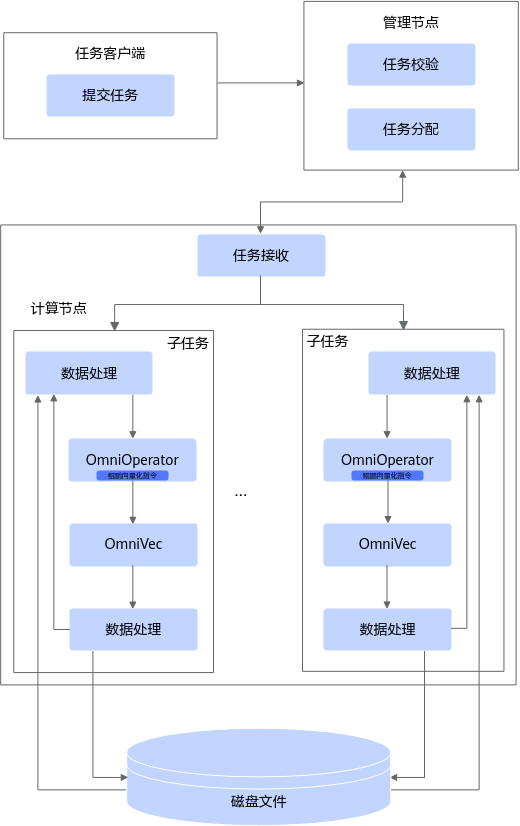
OmniOperator算子加速特性:
- 实现了高性能算子。充分利用硬件尤其是异构算力的计算能力,使用Native Code实现了Omni算子,相对于原始的Java算子和Scala算子,Omni算子极大地提升了计算引擎的性能。
- 实现了高效数据组织方式。定义了一种与语言无关的列式内存格式,使用堆外内存实现了OmniVec,它可以支持零副本读取数据,且没有序列化开销,使用者能够更高效地处理内存中的数据。