组件场景
Milvus构建在Faiss、HNSW、DiskANN、SCANN等流行的向量搜索库之上,专为在包含数百万、数十亿甚至数万亿向量的密集向量数据集上进行相似性搜索而设计。
组件原理
Milvus有两种运行模式:独立运行(单机版)和集群运行(集群版)。这两种模式具有相同的功能。
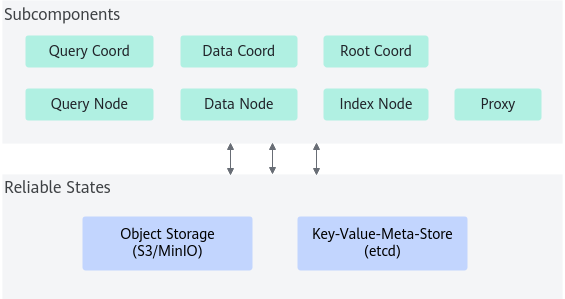
Milvus单机版
Milvus 单机版包括三个组件:
- Milvus:核心功能组件。
- 元数据存储:元数据引擎,用于访问和存储Milvus内部组件(包括代理、索引节点等)的元数据。
- 对象存储:存储引擎,负责Milvus的数据持久化。
图1 Milvus单机版架构
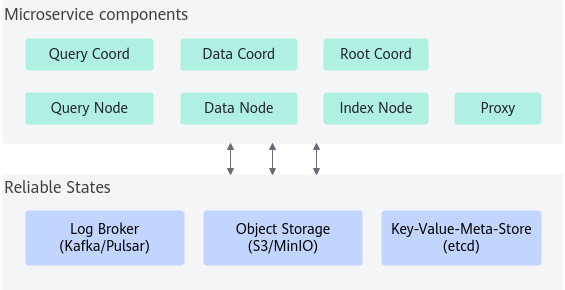
Milvus集群版
Milvus集群包括七个微服务组件和三个第三方依赖项。所有微服务都可以独立部署在Kubernetes上。
七个微服务组件为:根节点、代理、查询坐标、查询节点、数据节点、索引节点、数据节点。
三个第三方依赖项为:
- 元存储:存储集群中各种组件的元数据,如etcd。
- 对象存储: 负责集群中索引和二进制日志文件等大型文件的数据持久化,如S3/MinIO。
- 日志代理:管理最近突变操作的日志,输出流式日志,并提供日志发布-订阅服务,如Kafka/Pulsar。
图2 Milvus集群版架构
架构原理
图3 Milvus架构图
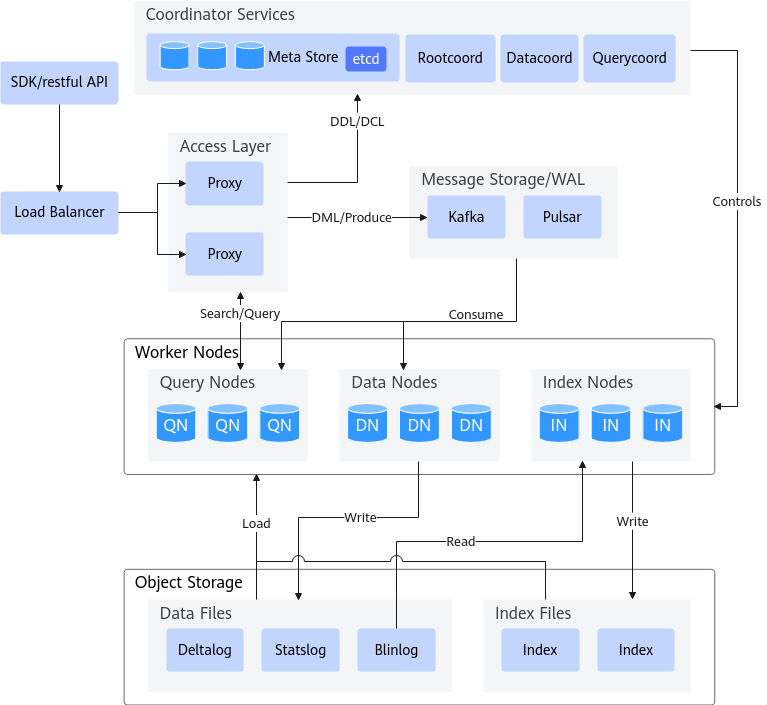
Milvus官方将Milvus整体架构分成了四个层,在可扩展性和灾难恢复方面相互独立。
- 访问层(Access Layer)
它由一组无状态代理组成,是系统的前端层,也是用户的终端。它验证客户端请求并减少返回结果。它使用一系列负载均衡组件提供统一的服务地址,而且Milvus采用的是大规模并行处理(MPP)架构,它还会对查询的中间结果进行聚合和处理,将最终结果返回给客户端。
- 协调服务(Coordinator Services)
它将任务分配给工作节点,起到系统大脑的作用。可以承担集群拓扑管理、负载平衡、时间戳生成、数据声明和数据管理。它包括根协调器、数据协调器和查询协调器。
- 工作节点(Worker Nodes)
工作节点是哑执行器,它遵从协调器服务的指令,执行来自代理的数据操作语言(DML)命令。由于存储和计算分离,工作节点是无状态的。它包括查询节点、数据节点和索引节点。
- 存储(Object Storage)