- 按照LLM模型下载下载相应的模型文件。
- 模型转换。由于昇腾硬件不支持FP8,因此需先权重转换为BF16;根据需求继续将BF16转换为INT8。
- FP8 -> BF16(预期20~30min)
# 参考地址: https://www.hiascend.com/software/modelzoo/models/detail/678bdeb4e1a64c9dae51d353d84ddd15 # 模型权重权限修改 chown root:root -R /home/openlab/deepseek-v3/ chmod 640 -R /home/openlab/deepseek-v3/ # NPU侧权重转换(留足空间,建议磁盘空间3T+,DeepSeek-V3在转换前权重约为640G左右,在转换后权重约为1.3T左右,w8a8量化后也需要600G) git clone https://gitee.com/ascend/ModelZoo-PyTorch.git cd ModelZoo-PyTorch/MindIE/LLM/DeepSeek/DeepSeek-V2/NPU_inference/ # 权重转换,时长约1.5H python fp8_cast_bf16.py --input-fp8-hf-path /home/openlab/deepseek/deepseek-v3/ --output-bf16-hf-path /home/openlab/deepseek/deepseek-v3-bf16/ # 权重权限改为750 chmod 750 -R /home/openlab/deepseek-v3-bf16/
- BF16 -> INT8(单卡7~8h,8卡~1h)
# 下载msit git clone -b br_noncom_MindStudio_8.0.0_POC_20251231 https://gitee.com/ascend/msit.git cd msit/msmodelslim bash install.sh # 升级transformers pip install transformers==4.48.2 # 修改模型权重的modeling_deepseek.py,注释掉is_flash_attn_2_available相关内容 vim /home/openlab/deepseek-v3-bf16/modeling_deepseek.py # 修改模型config.json,删除"quantization_config" vim /home/openlab/deepseek-v3-bf16/config.json cd example/DeepSeek/ # 修改脚本,改为8卡, vim quant_deepseek_w8a8.py export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 export PYTORCH_NPU_ALLOC_CONF=expandable_segments:False python3 quant_deepseek_w8a8.py --model_path /home/openlab/deepseek-v3-bf16/ --save_path /home/openlab/deepseek-v3-w8a8
- FP8 -> BF16(预期20~30min)
- 修改模型权重目录下的config.json文件。将model_type更改为 deepseekv2 (全小写且无空格)。
"model_type":"deepseekv2"
- 检查机器网络状况及机器间互联情况。
- 检查机器网络状况。
- 检查物理链接。
for i in {0..7}; do hccn_tool -i $i -lldp -g | grep Ifname; done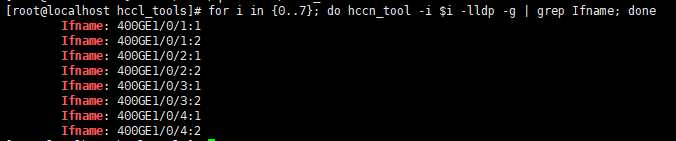
- 检查链接。
for i in {0..7}; do hccn_tool -i $i -link -g ; done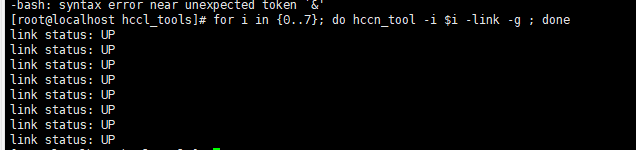
- 检查网络健康情况。
for i in {0..7}; do hccn_tool -i $i -net_health -g ; done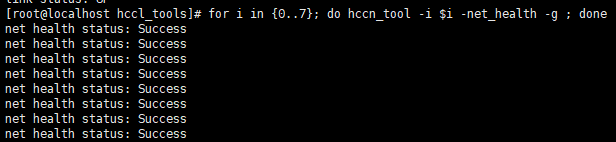
- 查看监测的IP地址配置是否正确,即监测IP地址为npu device ip。
for i in {0..7}; do hccn_tool -i $i -netdetect -g ; done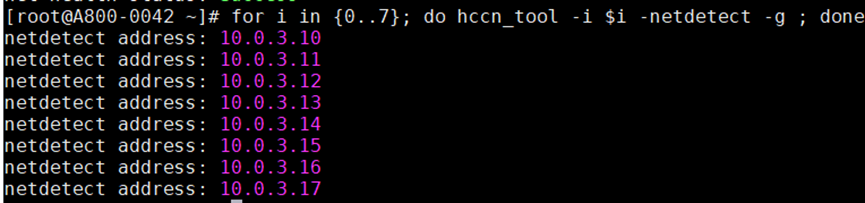
- 查看网关是否配置正确。
for i in {0..7}; do hccn_tool -i $i -gateway -g ; done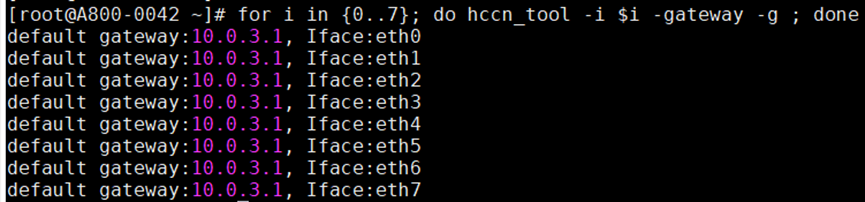
- 获取每张卡的IP地址。
for i in {0..7};do hccn_tool -i $i -ip -g; done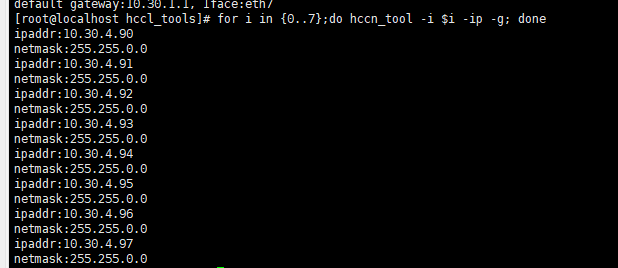
- 检测NPU底层TLS行为一致性,每台机器需要是一样的值,建议全0。
for i in {0..7}; do hccn_tool -i $i -tls -g ; done | grep switch
- NPU底层TLS校验行为置0操作。
for i in {0..7};do hccn_tool -i $i -tls -s enable 0;done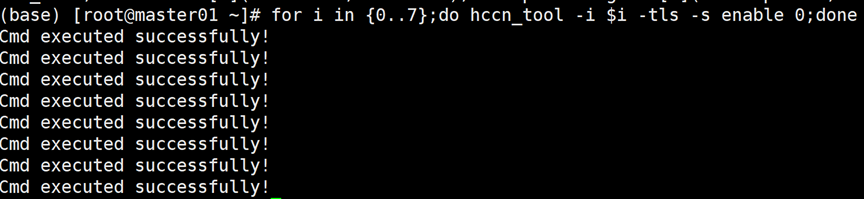
- 检查物理链接。
- 检查机器间互联情况。
- 先获取各机器每张卡的IP地址。
- 机器A各卡与机器B的每张卡通过ping命令进行连接检查。
for j in {0..7}; do for i in {90..97}; do hccn_tool -i ${j} -ping -g address 10.30.4.${i}; 【机器B各个卡的IP地址】 done; done
斜体内容可根据实际情况进行配置。
- 机器B各卡与机器A的每张卡通过ping命令进行连接检查,与上述操作一致。
- 检查机器网络状况。
- 自行创建rank_table_file.json。
- 使用多机推理时,需要将包含设备ip,服务器IP地址等信息的json文件地址传递给底层通信算子。参考如下格式,配置rank_table_file.json ,参考:
{ "server_count": "...", # 总节点数 # server_list中第一个server为主节点 "server_list": [ { "device": [ { "device_id": "...", # 当前卡的本机编号,取值范围[0,本机卡数) "device_ip": "...", # 当前卡的IP地址,可通过hccn_tool命令获取 "rank_id": "..." # 当前卡的全局编号,取值范围[0,总卡数) }, ... ], "server_id": "...", # 当前节点的IP地址 "container_ip": "..." # 容器IP地址 }, ... ], "status": "completed", "version": "1.0" }
- rank_table_file.json配置完成后,需要执行命令修改权限为640。
chmod -R 640 {rank_table_file.json路径}
- 使用多机推理时,需要将包含设备ip,服务器IP地址等信息的json文件地址传递给底层通信算子。参考如下格式,配置rank_table_file.json ,参考:
- 驱动、固件下载安装。
参考3.3.1 章节步骤2和步骤3,查看Atlas 800I A2推理产品如何安装NPU的驱动和固件。
- 镜像下载。
访问链接并下载下列软件:https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f

- 启动容器。启动容器前,需修改权重路径的执行权限,例如:chmod -R 750 /home/data/deepseekv3。
docker run -itd --privileged --name= {容器名称} --net=host --shm-size 500g \ --device=/dev/davinci0 \ --device=/dev/davinci1 \ --device=/dev/davinci2 \ --device=/dev/davinci3 \ --device=/dev/davinci4 \ --device=/dev/davinci5 \ --device=/dev/davinci6 \ --device=/dev/davinci7 \ --device=/dev/davinci_manager \ --device=/dev/hisi_hdc \ --device /dev/devmm_svm \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver \ -v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \ -v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \ -v /usr/local/sbin:/usr/local/sbin \ -v /etc/hccn.conf:/etc/hccn.conf \ -v {/权重路径:/权重路径} \ -v {/rank_table_file.json路径:/rank_table_file.json路径} \ {根据加载的镜像名称修改} \ bash
- 环境配置。
- 进入容器。
docker exec -it {容器名称} bash
- 设置基础环境变量。
source /usr/local/Ascend/ascend-toolkit/set_env.sh source /usr/local/Ascend/nnal/atb/set_env.sh source /usr/local/Ascend/atb-models/set_env.sh source /usr/local/Ascend/mindie/set_env.sh
- 开启通信环境变量。
export ATB_LLM_HCCL_ENABLE=1 export ATB_LLM_COMM_BACKEND="hccl" export HCCL_CONNECT_TIMEOUT=7200 双机: export WORLD_SIZE=16
- 配置服务化环境变量。
服务化需要rank_table_file.json中配置container_ip字段。 所有机器的配置应该保持一致,除了环境变量的MIES_CONTAINER_IP为本机IP地址。
export MIES_CONTAINER_IP= {容器IP地址} export RANKTABLEFILE= {rank_table_file.json路径}
- 修改服务化参数。
vim /usr/local/Ascend/mindie/latest/mindie-service/conf/config.json
按照以下内容修改。# 如果网络环境不安全,不开启HTTPS通信,即“httpsEnabled”=“false”时,会存在较高的网络安全风险 "httpsEnabled" : false, ... # 开启多机推理 ... # 若不需要安全认证,则将以下两个参数设为false "multiNodesInferEnabled" : true, "interCommTLSEnabled" : false, "interNodeTLSEnabled" : false, ... "npudeviceIds" : [[0,1,2,3,4,5,6,7]], ... "modelName" : "DeepSeek-R1" # 不影响服务化拉起 "modelWeightPath" : "权重路径", "worldSize":8,
- 进入容器。
- 启动service服务。拉起服务化。
# 以下命令需在所有机器上同时执行 # 解决权重加载过慢问题 export OMP_NUM_THREADS=1 # 设置显存比 export NPU_MEMORY_FRACTION=0.95 # 拉起服务化 cd /usr/local/Ascend/mindie/latest/mindie-service/ ./bin/mindieservice_daemon
执行命令后,首先会打印本次启动所用的所有参数,然后直到出现以下输出,则认为服务启动成功:
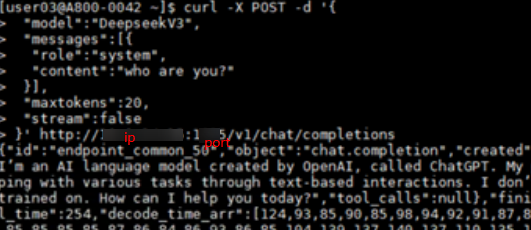
Daemon start success!新建窗口进行接口测试。
curl -X POST -d '{ "model":"DeepseekV1", "messages": [{ "role": "system", "content": "你是谁?" }], "max_tokens": 20, "stream": false }' http://ip:port/v1/chat/completions