开发程序
提供1个开发应用程序案例,基于图分析算法加速库中的TriangleCount算法。
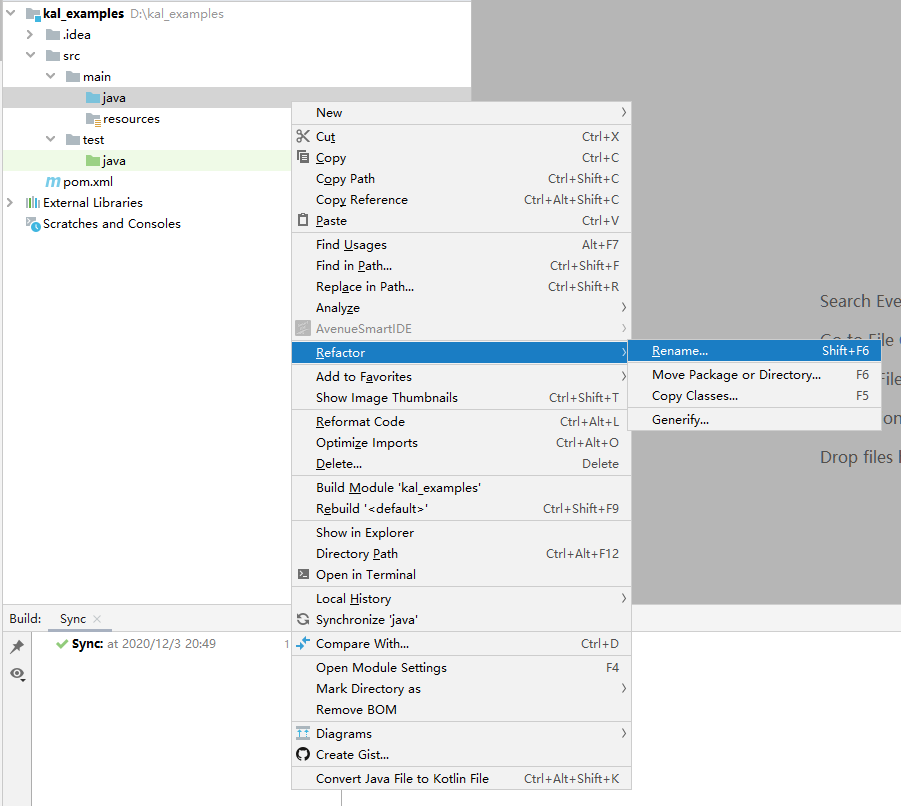
- 将工程中“src/main和src/test”目录下的“java”文件夹重命名为“scala”,“java”目录上右击,依次选择“Refactor”、“Rename”,然后输入“scala”。
- 在根目录下pom文件中添加依赖,将以下内容与pom.xml中的全部内容进行替换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.bigdata</groupId> <artifactId>kal_examples_2.12</artifactId> <version>0.1</version> <name>${project.artifactId}</name> <inceptionYear>2020</inceptionYear> <packaging>jar</packaging> <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.12.8</scala.version> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-graphx_2.12</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>it.unimi.dsi</groupId> <artifactId>fastutil</artifactId> <version>8.3.1</version> </dependency> <dependency> <groupId>org.apache.spark.graphx.lib</groupId> <artifactId>boostkit-graph-kernel-client_2.12</artifactId> <version>3.0.0</version> <classifier>spark3.3.1</classifier> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.0</version> <executions> <execution> <goals> <goal>compile</goal> </goals> <configuration> <args> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
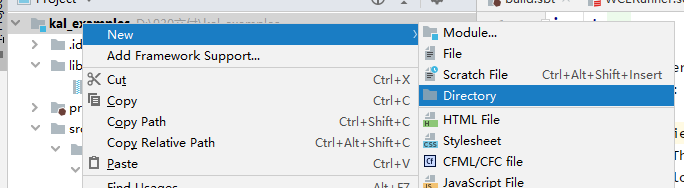
- 在根目录下新建lib文件夹。
- 右键单击。
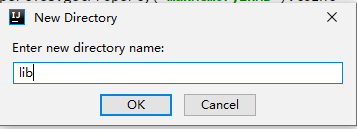
- 输入“lib”,单击“OK”。
- 右键单击。
- 将boostkit-graph-kernel-client_2.12-3.0.0-spark3.3.1.jar包放入新建的lib文件中。
- 将boostkit-graph-kernel-client_2.12-3.0.0-spark3.3.1.jar安装到本地仓,单击右侧边框,输入“install:install-file -DgroupId=org.apache.spark.graphx.lib -DartifactId=boostkit-graph-kernel-client_2.12 -Dversion=3.0.0 -Dfile=lib/boostkit-graph-kernel-client_2.12-3.0.0-spark3.3.1.jar -Dpackaging=jar”,按“Enter”。

编译结果如下。

- 在新建工程中,“src/main/scala/”目录下,新建Package“com.bigdata.examples”。
- 右键单击。
- 输入“com.bigdata.examples”,单击“OK”。
- 右键单击。
- 在6中创建的“com.bigdata.examples”package下新建TCRunner.scala文件。
- 右击“com.bigdata.examples”选择。
- 输入“TCRunner.scala”,单击“OK”。
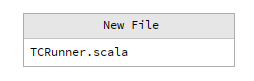
- 将以下代码复制到TCRunner.scala文件中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
package com.bigdata.examples import org.apache.spark.graphx import org.apache.spark.graphx.Graph import org.apache.spark.graphx.lib.TriangleCount import org.apache.spark.rdd.RDD import org.apache.spark.SparkConf import org.apache.spark.SparkContext object TCRunner { def main(args: Array[String]): Unit = { val numPartitions = 200 // 分区数为200 val split = " " // 分隔符为空格 // 创建Spark运行环境 val sparkConf = new SparkConf().setAppName(s"TC").setMaster("yarn") val sc = new SparkContext(sparkConf) // 记录程序运行开始时间 val startTime = System.currentTimeMillis() val inputData = sc.textFile("hdfs:///tmp/graph_data/graph500-23.e", numPartitions) // 给定输入路径和分区数 .flatMap(line => { if (line.startsWith("#")) { // 数据行以#开始,跳过读取这一行 Iterator.empty } else { val x = line.split(split) // 按照分隔符读取每一行数据 if (x.length < 2) { // 如果有数据缺失,则跳过读取这一行 Iterator.empty } else { val node1 = x(0) // 第一个结点数据 val node2 = x(1) // 第二个结点数据 Iterator((node1, node2)) // Scala迭代器,将每一组结点连接起来 } } }) // 进行数据变换 val inputRdd = inputData.flatMap(x => { if (x._1.toLong == x._2.toLong) { // 排除起始结点都是自身的自环结点 Iterator.empty } else if (x._1.toLong > x._2.toLong) { Iterator((x._2.toLong, x._1.toLong)) // 始终保持第一个结点数值小于第二个结点的数值 } else { Iterator((x._1.toLong, x._2.toLong)) } }) // 用Spark框架构建图 val graph = Graph.fromEdgeTuples(inputRdd, 0) var result: RDD[(graphx.VertexId, Int)] = null // 调用TriangleCount算法run接口,计算结果 result = TriangleCount.run(graph).vertices.repartition(numPartitions.toInt) // 保存数据到指定输出路径 result.map(f => f._1 + "," + f._2).saveAsTextFile("hdfs:///tmp/graph_result/graph500-23-result") // 将结果输出到指定路径 // 记录程序花费时间 val costTime = (System.currentTimeMillis() - startTime) / 1000.0 println("TriangleCounting is finished , and costTime = " + costTime + " 's") } }
图1 文件目录结构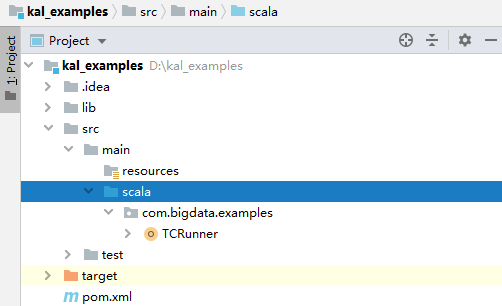
- 右击“com.bigdata.examples”选择。
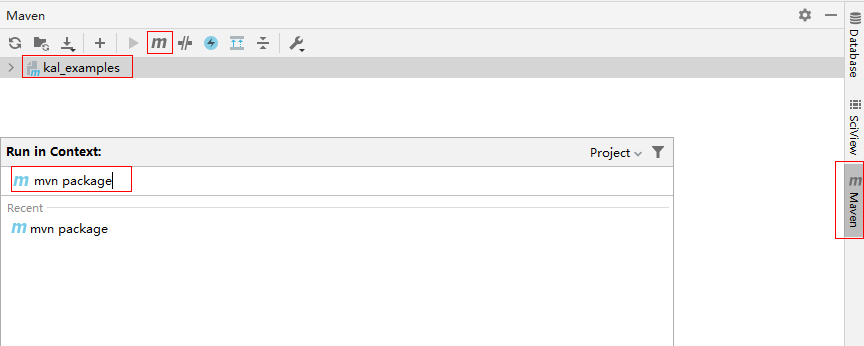
- 单击右侧边框,输入“package”,按“Enter”,进行项目打包,在“target\”目录中生成kal_examples_2.12-0.1.jar。
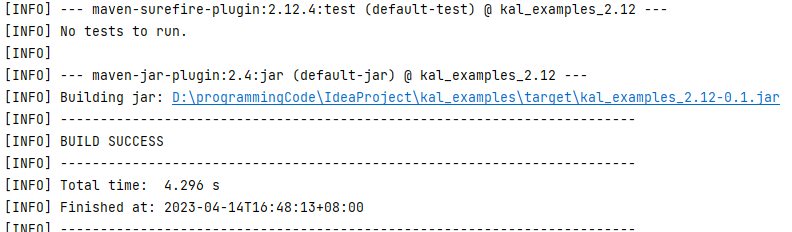
运行结果如下。
父主题: 样例工程