生成数据集
生成CP10M1K数据集
- 修改HiBench配置文件。
- 进入“HiBench-HiBench-7.0/conf”目录。
1cd /HiBench-HiBench-7.0/conf
- 修改“/HiBench-HiBench-7.0/conf/workloads/ml/svd.conf”配置文件。
1vi /HiBench-HiBench-7.0/conf/workloads/ml/svd.conf - 按“i”进入编辑模式,修改数据配置如下。
1 2 3
hibench.svd.bigdata.examples 10000000 hibench.svd.bigdata.features 1000 hibench.workload.input ${hibench.hdfs.data.dir}/CP10M1K
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 进入“HiBench-HiBench-7.0/conf”目录,修改“/HiBench-7.0/conf/hibench.conf”配置文件。
1 2
cd /HiBench-HiBench-7.0/conf vi hibench.conf
- 按“i”进入编辑模式,修改数据配置如图所示。
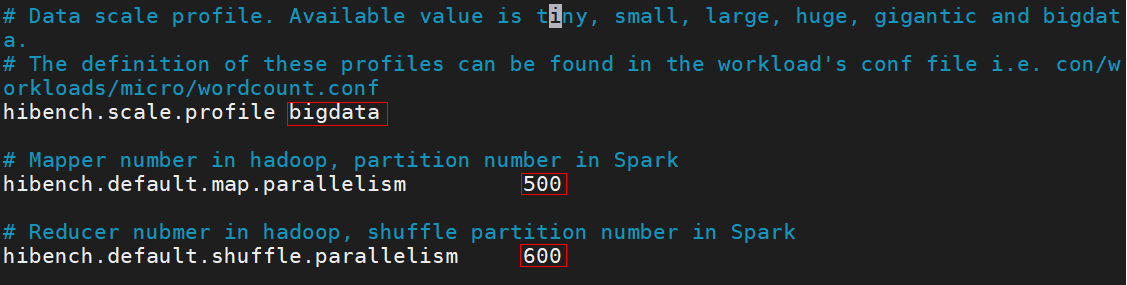
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 进入“HiBench-HiBench-7.0/conf”目录。
- 生成数据集。
- 首先进入HDFS,确定生成目录。
1hdfs dfs -mkdir -p /tmp/ml/dataset/
- 进入执行路径。
1cd /HiBench-HiBench-7.0/bin/workloads/ml/svd/prepare/
- 运行生成脚本,生成数据集CP10M1K。
1sh prepare.sh - 查看生成结果。
1hadoop fs -ls /HiBench/CP10M1K
- 当生成过程中,出现权限报错时,对相应目录用root账户和HDFS分别进行权限更改。
- 首先进入HDFS,确定生成目录。
- 使用HDFS新建文件夹。
1hadoop fs -mkdir -p /tmp/ml/dataset
- 打开spark-shell。
1spark-shell
- 输入以下命令。
1:paste
- 执行下面代码,对数据集进行处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import org.apache.spark.internal.Logging import org.apache.spark.ml.linalg.SQLDataTypes.VectorType import org.apache.spark.ml.linalg.{Matrix, Vectors} import org.apache.spark.mllib.linalg.DenseVector import org.apache.spark.sql.{Row, SparkSession} import org.apache.spark.sql.types.{StructField, StructType} import org.apache.spark.storage.StorageLevel val dataPath = "/HiBench/CP10M1K" val outputPath = "/tmp/ml/dataset/CP10M1K" spark .sparkContext .objectFile[DenseVector](dataPath) .map(row => Vectors.dense(row.values).toArray.map{u=>f"$u%.2f"}.mkString(",")) .saveAsTextFile(outputPath)
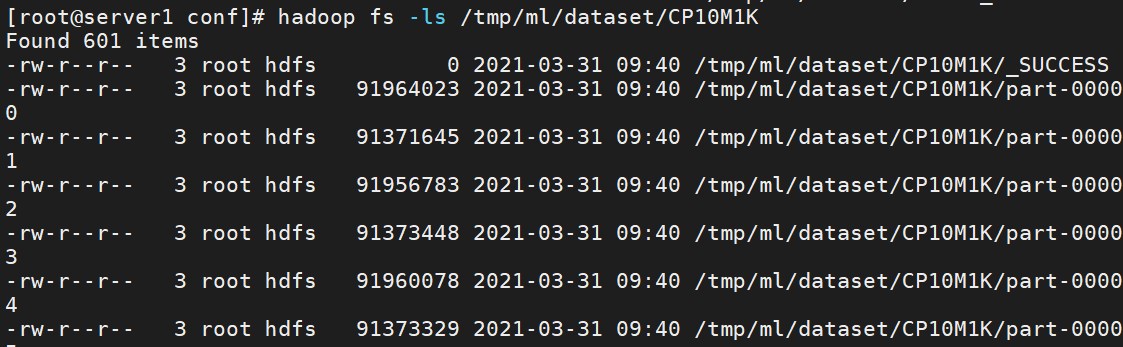
- 检查HDFS对应目录,得到结果如下图。
1hadoop fs -ls /tmp/ml/dataset/CP10M1K
生成CP2M5K数据集
- 修改HiBench配置文件。
- 进入“HiBench-HiBench-7.0/conf”目录。
1cd /HiBench-HiBench-7.0/conf
- 打开“/HiBench-HiBench-7.0/conf/workloads/ml/svd.conf”配置文档。
1vi /HiBench-HiBench-7.0/conf/workloads/ml/svd.conf - 按“i”进入编辑模式,修改数据配置如下。
1 2 3
hibench.svd.bigdata.examples 2000000 hibench.svd.bigdata.features 5000 hibench.workload.input ${hibench.hdfs.data.dir}/CP2M5K
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 进入“HiBench-HiBench-7.0/conf”目录。
1cd /HiBench-HiBench-7.0/conf
- 打开“/HiBench-7.0/conf/hibench.conf”配置文档。
1vi hibench.conf - 按“i”进入编辑模式,修改数据配置如下。
1 2 3
hibench.scale.profile bigdata hibench.default.map.parallelism 500 hibench.default.shuffle.parallelism 600
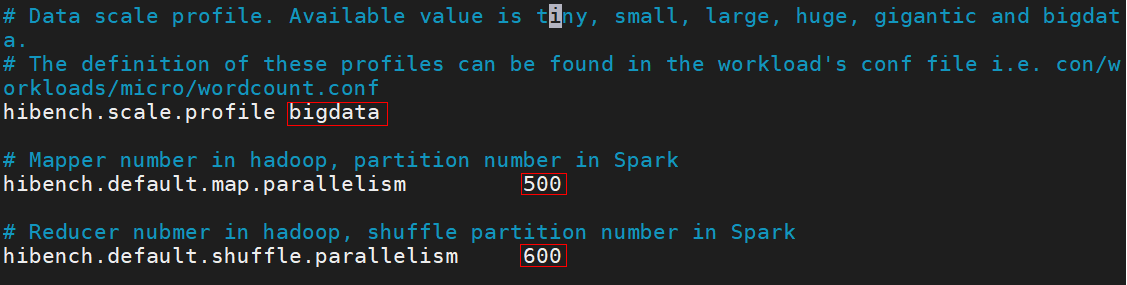
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 进入“HiBench-HiBench-7.0/conf”目录。
- 生成数据。
- 首先进入HDFS,确定生成目录。
1hdfs dfs -mkdir -p /tmp/ml/dataset/
- 进入执行路径。
1cd /HiBench-HiBench-7.0/bin/workloads/ml/svd/prepare/
- 运行生成脚本,生成数据集CP2M5K。
1sh prepare.sh - 当生成过程中,出现权限报错时,对相应目录用root账户和HDFS分别进行权限更改。
- 首先进入HDFS,确定生成目录。
- HDFS新建文件夹。
1hadoop fs -mkdir -p /tmp/ml/dataset
- 打开spark-shell。
1spark-shell
- 输入以下命令。
1:paste
- 执行下面代码,对数据集进行处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import org.apache.spark.internal.Logging import org.apache.spark.ml.linalg.SQLDataTypes.VectorType import org.apache.spark.ml.linalg.{Matrix, Vectors} import org.apache.spark.mllib.linalg.DenseVector import org.apache.spark.sql.{Row, SparkSession} import org.apache.spark.sql.types.{StructField, StructType} import org.apache.spark.storage.StorageLevel val dataPath = "/HiBench/CP2M5K" val outputPath = "/tmp/ml/dataset/CP2M5K" spark .sparkContext .objectFile[DenseVector](dataPath) .map(row => Vectors.dense(row.values).toArray.map{u=>f"$u%.2f"}.mkString(",")) .saveAsTextFile(outputPath)
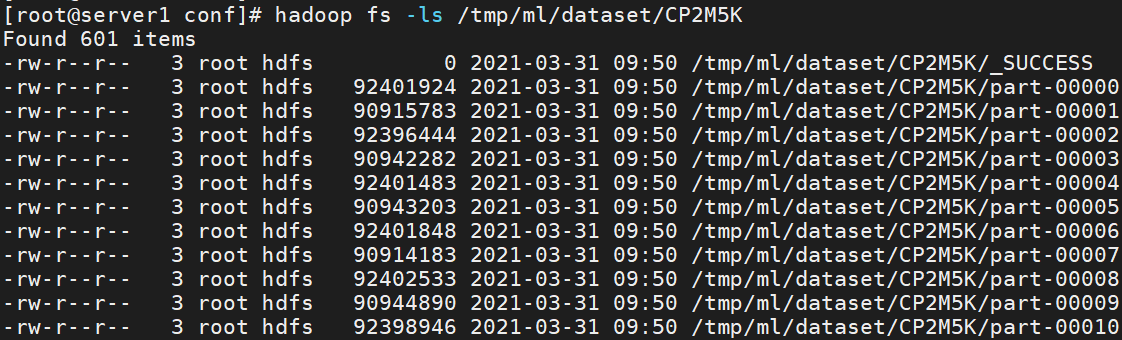
- 检查HDFS对应目录,得到结果如下图。
1hadoop fs -ls /tmp/ml/dataset/CP2M5K
生成ALS数据集
- 设置HiBench配置文档。
- 进入“HiBench-HiBench-7.0/conf”目录。
1cd /HiBench-HiBench-7.0/conf
- 打开“/HiBench-HiBench-7.0/conf/workloads/ml/als.conf”配置文档。
1vi /HiBench-HiBench-7.0/conf/workloads/ml/als.conf - 按“i”进入编辑模式,修改数据配置如下。
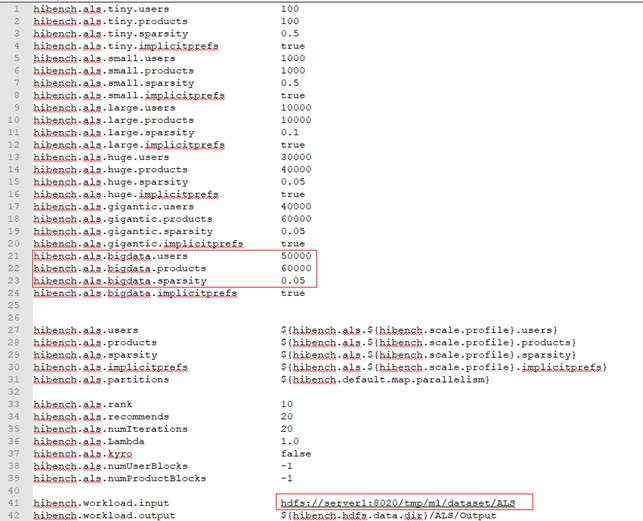
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 进入“HiBench-HiBench-7.0/conf”目录。
1cd /HiBench-HiBench-7.0/conf
- 打开“/HiBench-7.0/conf/hibench.conf”配置文档。
1vi hibench.conf - 按“i”进入编辑模式,修改数据配置如下。

- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 进入“HiBench-HiBench-7.0/conf”目录。
- 生成数据。
- 首先进入HDFS,确定生成目录。
1hdfs dfs -mkdir -p /tmp/ml/dataset/ALS
- 进入执行路径。
1cd /HiBench-HiBench-7.0/bin/workloads/ml/als/prepare/
- 运行生成脚本,生成数据集ALS。
1sh prepare.sh - 查看生成结果。
1hadoop fs -ls /tmp/ml/dataset/ALS
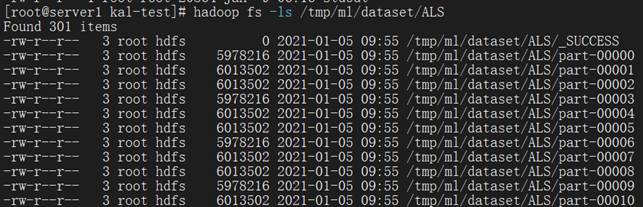

当生成过程中,出现权限报错时,对相应目录用root账户和hdfs分别进行权限更改。
- 首先进入HDFS,确定生成目录。
生成D200M100数据集
- 设置HiBench配置文档。
- 进入“HiBench-HiBench-7.0/conf”目录。
1cd /HiBench-HiBench-7.0/conf
- 打开“/HiBench-HiBench-7.0/conf/workloads/ml/kmeans.conf”配置文档。
1vi /HiBench-HiBench-7.0/conf/workloads/ml/kmeans.conf - 按“i”进入编辑模式,修改数据配置如下。
1 2 3 4 5 6 7 8 9
hibench.kmeans.gigantic.num_of_clusters 5 hibench.kmeans.gigantic.dimensions 100 hibench.kmeans.gigantic.num_of_samples 200000000 hibench.kmeans.gigantic.samples_per_inputfile 40000000 hibench.kmeans.gigantic.max_iteration 5 hibench.kmeans.gigantic.k 10 hibench.kmeans.gigantic.convergedist 0.5 hibench.workload.input hdfs://server1:8020/tmp/ml/dataset/kmeans_200m20_tmp
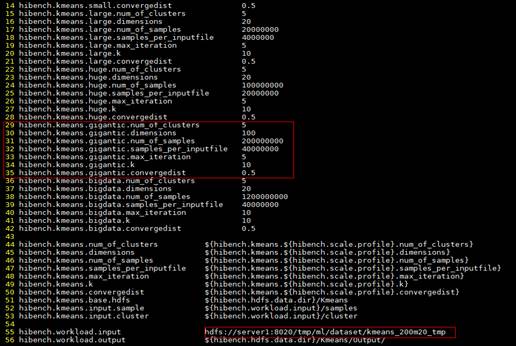
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 进入“HiBench-HiBench-7.0/conf”目录。
1cd /HiBench-HiBench-7.0/conf
- 打开“/HiBench-HiBench-7.0/conf/hibench.conf”配置文档。
1vi hibench.conf - 按“i”进入编辑模式,修改数据配置如下。

- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 进入“HiBench-HiBench-7.0/conf”目录。
- 生成数据。
- 首先进入HDFS,确定生成目录。
1hdfs dfs -mkdir -p /tmp/ml/dataset/kmeans_200m100_tmp
- 进入执行路径。
1cd /HiBench-HiBench-7.0/bin/workloads/ml/kmeans/prepare/
- 运行生成脚本,生成数据集D200M100。
1sh prepare.sh
- 首先进入HDFS,确定生成目录。
- 查看生成结果。
1hdfs dfs -ls /tmp/ml/dataset/kmeans_200m100_tmp
当生成过程中,出现权限报错时,对相应目录用root账户和HDFS分别进行权限更改。
- HDFS上创建数据集存放路径。
1hdfs dfs -ls /tmp/ml/dataset/kmeans_200m100
- 移动数据集到指定路径。
1hdfs dfs -mv /tmp/ml/dataset/kmeans_200m100_tmp/samples/* /tmp/ml/dataset/kmeans_200m100/
- 查看结果。
1hdfs dfs -ls /tmp/ml/dataset/kmeans_200m100/

- 清理冗余目录。
1hdfs dfs -rm -r /tmp/ml/dataset/kmeans_200m100_tmp
生成D10M4096数据集
- 设置HiBench配置文档。
- 进入“HiBench-HiBench-7.0/conf”目录。
1cd /HiBench-HiBench-7.0/conf
- 打开“/HiBench-HiBench-7.0/conf/workloads/ml/lr.conf”配置文档。
1vi /HiBench-HiBench-7.0/conf/workloads/ml/lr.conf - 按“i”进入编辑模式,修改数据配置如下。将数据样本改为1000万个,将数据特性改为4096。生成4000万个样本的大规模数据集。
1 2
hibench.lr.bigdata.examples 10000000 hibench.lr.bigdata.features 4096

- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 进入“HiBench-HiBench-7.0/conf”目录。
1cd /HiBench-HiBench-7.0/conf
- 打开“/HiBench-HiBench-7.0/conf/hibench.conf”配置文档。
1vi hibench.conf - 按“i”进入编辑模式,修改数据配置如下。
1 2 3
hibench.scale.profile bigdata hibench.default.map.parallelism 300 hibench.default.shuffle.parallelism 300
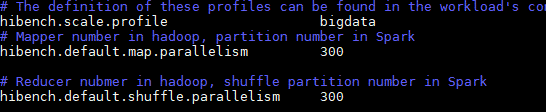
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 进入“HiBench-HiBench-7.0/conf”目录。
- 生成数据。
- 首先进入HDFS,确定生成目录。
1hdfs dfs -mkdir -p /tmp/ml/dataset/
- 进入执行路径。
1cd /HiBench-HiBench-7.0/bin/workloads/ml/lr/prepare/
- 运行生成脚本,生成数据集D10M4096。
1sh prepare.sh
- 首先进入HDFS,确定生成目录。
- 查看生成结果。
1hdfs dfs -ls /HiBench/HiBench/LR/Input
当生成过程中,出现权限报错时,对相应目录用root账户和HDFS分别进行权限更改。
- 打开spark-shell。
1spark-shell
- 输入以下命令。
1:paste
- 执行下面代码,对数据集进行处理。
1 2 3 4 5 6 7
import org.apache.spark.rdd.RDD import org.apache.spark.mllib.regression.LabeledPoint val data: RDD[LabeledPoint] = sc.objectFile("/HiBench/HiBench/LR/Input/10m4096") val i = data.map{t=>t.label.toString+","+t.features.toArray.mkString(" ")} val splits = i.randomSplit(Array(0.6, 0.4), seed = 11L) splits(0).saveAsTextFile("/HiBench/HiBench/LR/Output/10m4096_train") splits(1).saveAsTextFile("/HiBench/HiBench/LR/Output/10m4096_test")
生成HiBench_10M_200M数据集
- 设置HiBench配置文档。
- 进入“HiBench-HiBench-7.0/conf”目录。
1cd /HiBench-HiBench-7.0/conf
- 打开“/HiBench-HiBench-7.0/conf/workloads/ml/lda.conf”配置文件。
1vi /HiBench-HiBench-7.0/conf/workloads/ml/lda.conf - 按“i”进入编辑模式,修改数据配置如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
hibench.lda.bigdata.num_of_documents 10000000 hibench.lda.bigdata.num_of_vocabulary 200007152 hibench.lda.bigdata.num_of_topics 100 hibench.lda.bigdata.doc_len_min 500 hibench.lda.bigdata.doc_len_max 10000 hibench.lda.bigdata.maxresultsize "6g" hibench.lda.num_of_documents ${hibench.lda.${hibench.scale.profile}.num_of_documents} hibench.lda.num_of_vocabulary ${hibench.lda.${hibench.scale.profile}.num_of_vocabulary} hibench.lda.num_of_topics ${hibench.lda.${hibench.scale.profile}.num_of_topics} hibench.lda.doc_len_min ${hibench.lda.${hibench.scale.profile}.doc_len_min} hibench.lda.doc_len_max ${hibench.lda.${hibench.scale.profile}.doc_len_max} hibench.lda.maxresultsize ${hibench.lda.${hibench.scale.profile}.maxresultsize} hibench.lda.partitions ${hibench.default.map.parallelism} hibench.lda.optimizer "online" hibench.lda.num_iterations 10
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 进入“HiBench-HiBench-7.0/conf”目录。
- 生成数据。
- 首先进入HDFS,确定生成目录。
1hdfs dfs -mkdir -p /tmp/ml/dataset/
- 进入执行路径。
1cd /HiBench-HiBench-7.0/bin/workloads/ml/lda/prepare/
- 运行bin/workloads/ml/lda/prepare/prepare.sh生成数据集。
1sh prepare.sh
- 首先进入HDFS,确定生成目录。
- 打开spark-shell。
1spark-shell
- 输入以下命令。
1:paste
- 执行下面代码,将生成的数据,转换为ORC格式。
1 2 3 4 5 6
import org.apache.spark.mllib.linalg.{Vector => OldVector, Vectors => OldVectors} import org.apache.spark.ml.linalg.{Vector, Vectors} case class DocSchema(id: Long, tf: Vector) val data: RDD[(Long, OldVector)] = sc.objectFile(dataPath) val df = spark.createDataFrame(data.map {doc => DocSchema(doc._1, doc._2.asML)}) df.repartition(200).write.mode("overwrite").format("orc").save(outputPath)
生成HibenchRating3wx3w数据集
- 修改scala文件参数。
- 打开“Hibench/sparkbench/ml/src/main/scala/com/intel/sparkbench/ml/RatingDataGenerator.scala”文件。
1vi Hibench/sparkbench/ml/src/main/scala/com/intel/sparkbench/ml/RatingDataGenerator.scala - 按“i”进入编辑模式,修改中numPartitions参数(如下图,注释第36、37行并添加第38行)。
1val numPartitions = parallel

- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 打开“Hibench/sparkbench/ml/src/main/scala/com/intel/sparkbench/ml/RatingDataGenerator.scala”文件。
- 生成数据。
- 编译sparkbench模块。
1mvn package - 将编译好的sparkbench-common-8.0-SNAPSHOT.jar和sparkbench-ml-8.0-SNAPSHOT.jar两个JAR包放到相同文件夹中,调用RatingDataGenerator即可生成数据,例如。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
spark-submit \ --class com.intel.hibench.sparkbench.ml.RatingDataGenerator \ --jars sparkbench-common-8.0-SNAPSHOT.jar \ --conf "spark.executor.instances=71" \ --conf "spark.executor.cores=4" \ --conf "spark.executor.memory=12g" \ --conf "spark.executor.memoryOverhead=2g" \ --conf "spark.default.parallelism=284" \ --master yarn \ --deploy-mode client \ --driver-cores 36 \ --driver-memory 50g \ ./sparkbench-ml-8.0-SNAPSHOT.jar \ /tmp/hibench/HibenchRating3wx3w 24000 6000 900000 false
配置参数含义:
- /tmp/hibench/HibenchRating3wx3w代表生成数据的存储位置。
- 24000代表user数。
- 6000代表product数。
- 900000代表rating数。
- false代表不生成隐式反馈的数据。
- 编译sparkbench模块。

父主题: 使用HiBench工具生成数据集