特征工程
场景介绍
特征工程指的是把原始数据转变为模型的训练数据的过程,它的目的就是获取更好的训练数据特征,使得机器学习模型逼近这个上限。大数据场景下,数据特征维度可以达到千万级别,在高维情况下,会面临维度灾难——当样本量不足时导致过拟合问题;同时,数据量过大会影响性能。以特征降维算法PCA(Principal Component Analysis,主成分分析)为例,经分析99%的计算耗时在于底层调用和运行SVD(Singular Value Decomposition,奇异值分解)算法,如果不进行SVD算法优化,会导致个性化推荐、关键对象识别、冗余信息缩减等场景的数据分析困难。因此,鲲鹏BoostKit通过优化重启技术、减少迭代轮次等优化手段,加快SVD算法的收敛速度,提升SVD算法对奇异值不分离和奇异值范围大,以及对高维数据场景的适应性。
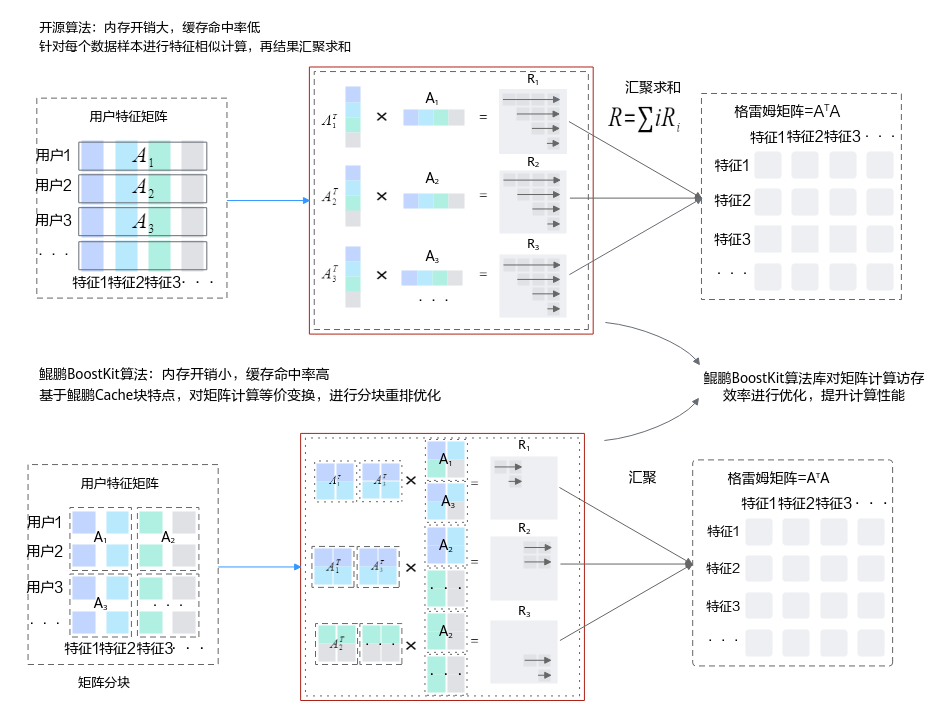
算法原理
- DTB算法
DTB(Decision Tree Bucket,决策树分箱)是一种基于决策树模型的数据离散化方法,是业界常见的有监督分箱方法。数据离散化是指将连续的数据进行分段,使其变为一段段离散化的区间,离散化过程也被表述成分箱的过程。离散化数值型特征,是将无限空间中有限的个体,映射到有限的空间中,有效减小后续算法的时间和空间开销。
- Word2Vec算法
Word2Vec(词向量)算法目的是将词转换为稠密向量表示(Distributed Representation),这样词之间的关系就可以用向量之间的距离来表示。除文本外,也可以用于编码类别变量,即“万物皆可Embedding”。相较于One Hot等特征编码方式,Word2Vec可以提取固定长度的稠密特征,富含更多的上下文信息,能提升下游算法的精度和性能。Spark开源Word2Vec算法不能处理词表过大的数据,迭代到收敛非常耗时,因此基于Spark的高效分布式Word2Vec算法很有意义。