在Spark SQL中执行包含大量列(例如500列)的cast string to double表达式时查询性能差的解决方法
问题现象描述
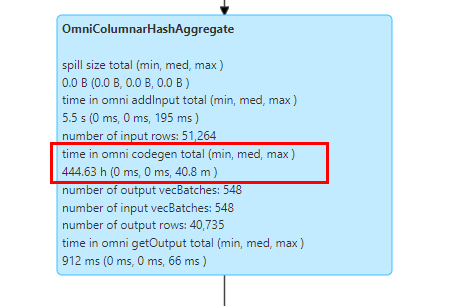
当使用Spark OmniOperator对包含大量变长类型列(如500列)的数据进行聚合查询时,SQL查询性能可能会下降。

关键过程、根本原因分析
在对变长类型列进行聚合操作时,需通过Codegen实现字符串到双精度浮点数的类型转换。由于Codegen本身存在编译开销,SQL查询的性能将受到编译时间和算子执行时间的双重影响。当超多列需要同时进行Codegen编译时,编译开销远大于OmniOperator算子执行时间,导致整体SQL查询性能慢。

结论、解决方案及效果
当存在超多列需要进行表达式Codegen的SQL查询场景,建议回退至Spark开源版本进行查询,该操作不影响任务结果的一致性。
父主题: 故障排除