BulkLoad测试用例
用例分析
BulkLoad用例前半部分鲲鹏计算平台48核CPU占用90%+,x86计算平台CPU占用100%。分析BulkLoad用例具体流程如下:
- Map阶段:该阶段是并发生成HFile,根据数据量的大小,Map阶段会有上万个并发去加载HDFS中待导入的数据,然后进行格式转换,格式转换过后会对数据进行校验,检测KV是否有效。最后会对生成的HFile进行压缩。这一过程会消耗大量的CPU。现有MapReduce配置为1个Map申请一个vcore。
- Reduce阶段:根据Region个数将生成的HFile放置到不同的Region。Reduce阶段的并发数量是根据Region个数来决定的。
Map优化
BulkLoad的ImportTsv默认是以HDFS的blocksize(默认128MB)来切分数据文件,如200G的数据文件大概有1600多个Map任务,但是并没有相应的参数设定来修改Map数,故通过更改ImportTsv源码,ImportTsv该类具体位于HBase源码的hbase-mapreduce-2.0.2.3.1.0.0-78.jar中,具体的路径如下。
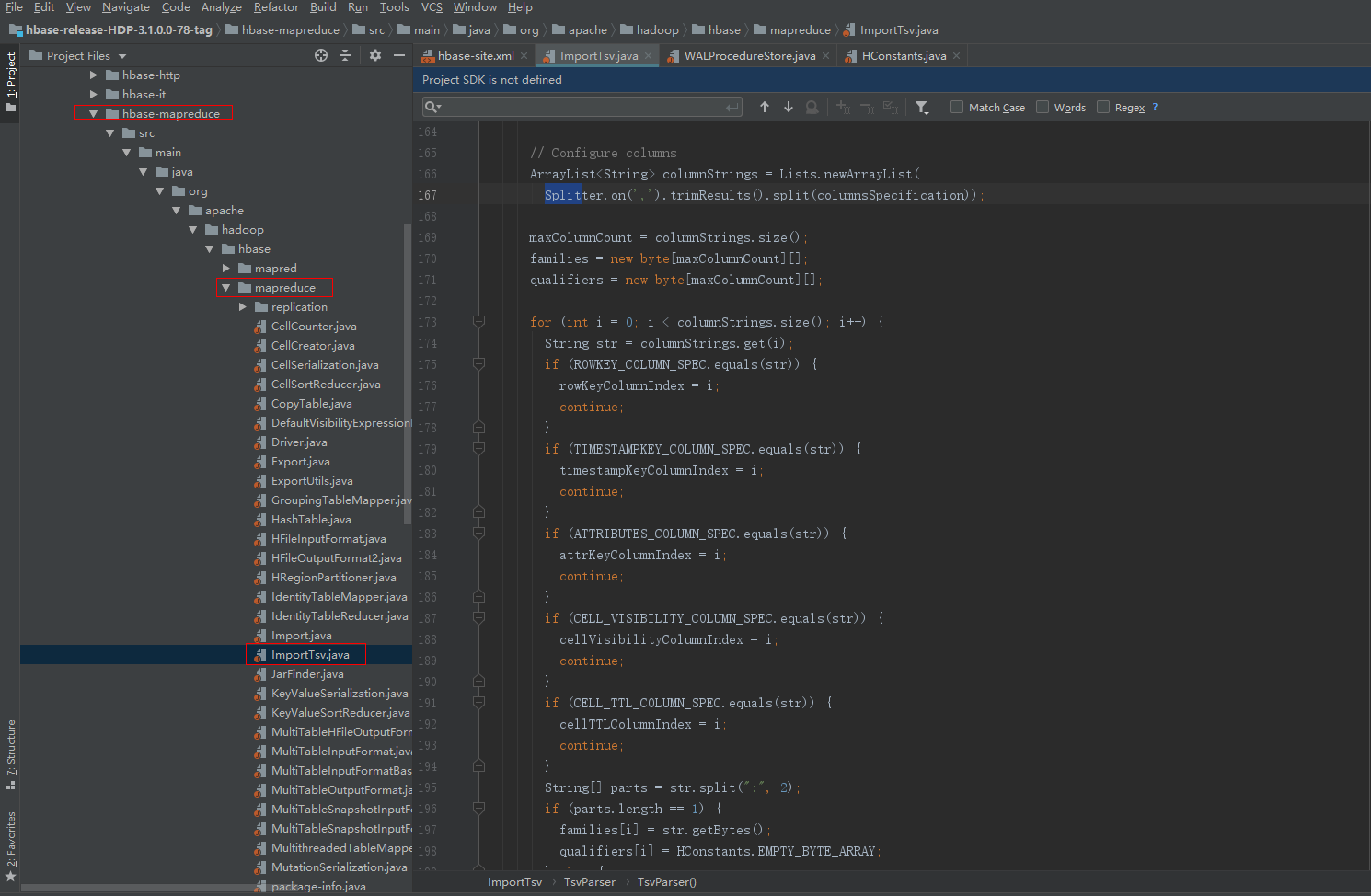
在ImportTsv.java增加一个配置参数,即增加一个成员变量:

在createSubmittableJob方法中增加如下代码:

将该JAR包重新编译后,通过find查找到JAR包所在位置,替换到对应的HBase源码中。

替换之后就可以在ImportTsv上配置一个mapreduce.split.minsize参数,参照如下。
1
|
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns=HBASE_ROW_KEY,f1:H_NAME,f1:ADDRESS -Dimporttsv.separator="," -Dimporttsv.skip.bad.lines=true -Dmapreduce.split.minsize=5368709120 -Dimporttsv.bulk.output=/tmp/hbase/hfile ImportTable /tmp/hbase/datadirImport |

-Dmapreduce.split.minsize=5368709120:该值就是设定了数据文件的分割数值,进而可以修改map数值,设置Map数时可以将Map数与CPU核数设置差不多。
Reduce优化
查看任务运行的时间,发现reduce运行时间很不均衡,有的3分钟,有的40秒,相差很大,故尝试增加reduce数,使每个reduce处理数据更均衡。

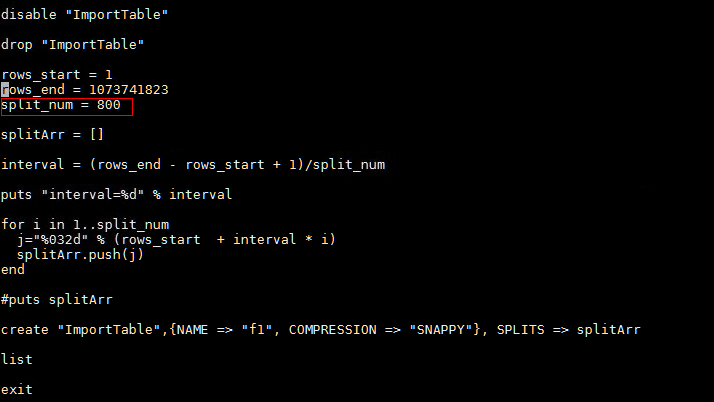
通过修改预分区数(Region),可以修改reduce数量。(本次测试设定的是800Region)
修改对应文件run_create.txt中的split_num即可修改Region数量。
顺序数据测试
本次BulkLoad测试的数据为每条1K,单条格式如下:

HBase的RowKey是按照ASCII字典排序设计的,排序时会先比对两个RowKey的第一个字节,如果相同,然后会比对第二个字节,依次类推,直到比较到最后一位。为了保证数据能够均衡写入到每个Region,利用位补齐的方法将RowKey的位数长度设置成一样。