Storm介绍
Storm基本组件
- Nimbus
- ZooKeeper
Storm重点依赖的外部资源,Nimbus、Supervisor和Worker等都是把心跳数据保存在ZooKeeper上,Nimbus也是根据ZooKeeper上的心跳和任务运行状况进行调度和任务分配的。
- Supervisor
在运行节点上,监测分配的任务,根据需要启动或关闭工作进程Worker。每一个要运行Storm的机器上都运行一个Supervisor。
- Worker
在Supervisor上创建的一个JVM实例,Worker中运行Executor,而Executor作为Task运行的容器。
- Executor
运行时Task所在的直接容器,在Executor中执行Task的处理逻辑。一个或多个Executor实例可以运行在同一个Worker进程中,一个或多个Task可以运行于同一个Executor中。
- Task
Spout/Bolt在运行时所表现出来的实体,都称为Task,一个Spout/Bolt在运行时可能对应一个或多个Spout Task或Bolt Task。
Storm流处理流程
在Storm中可以通过组件简单串行或者组合多种流操作处理数据。
Storm基本概念
Storm提交运行的程序称为Topology,它处理的最小的消息单位是一个Tuple,也就是一个任意对象的数组。Topology由Spout和Bolt构成,Spout是发出Tuple的节点,Bolt可以随意订阅某个Spout或者Bolt发出的Tuple。图1是一个Topology设计的逻辑图的例子。
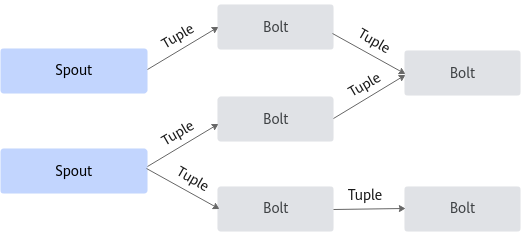
- Topology:是一个用来编排、容纳一组计算逻辑组件(Spout、Bolt)的对象,这一组计算组件可以按照DAG图的方式编排起来从而组合成一个计算逻辑更加复杂的对象。一个Topology运行以后就不能停止,它会无限地运行下去,除非手动干预(显式执行bin/storm kill)或意外故障(如停机、整个Storm集群挂掉)让它终止。
- Spout:是一个Topology的消息生产的源头,Spout是一个持续不断生产消息的组件, Spout生成的消息在Storm中被抽象为Tuple,在整个Topology的多个计算组件之间都是根据需要抽象构建的Tuple消息来进行连接,从而形成流。
- Bolt:Storm中消息的处理逻辑被封装到Bolt组件中,任何处理逻辑都可以在Bolt里面执行,Bolt可以接收来自一个或多个Spout的Tuple消息,也可以来自多个其他Bolt的Tuple消息,也可能是Spout和其他Bolt组合发送的Tuple消息。
- Stream Grouping:Storm中用来定义各个计算组件(Spout和Bolt)之间流的连接、分组和分发关系。Storm定义了如下7种分发策略:Shuffle Grouping(随机分组)、Fields Grouping(按字段分组)、All Grouping(广播分组)、Global Grouping(全局分组)、Non Grouping(不分组)、Direct Grouping(直接分组)、Local or Shuffle Grouping(本地/随机分组)。
Storm拓扑提交流程
- 客户端通过Nimbus的接口上传程序JAR包到Nimbus的Inbox目录中,上传结束后,便向Nimbus提交了一个Topology。
- Nimbus接收到提交Topology的命令后,对接收到的程序JAR包进行序列化。静态的信息设置完成后,通过心跳信息分配任务到机器节点。之后,系统根据Worker的数目,尽量平均的分配这些Task的执行。其中Worker在哪个Supervisor节点上运行是由Storm本身决定的。
- 任务分配好之后,Nimbus节点会将任务的信息提交到ZooKeeper集群,同时在ZooKeeper集群中会有Worker分派节点,这里存储了当前Topology的所有Worker进程的心跳信息。
- Supervisor节点会不断轮询ZooKeeper集群,在ZooKeeper的分派节点中保存了所有Topology的任务分配信息、代码存储目录和任务之间的关联关系等,Supervisor通过轮询此节点的内容,来领取自己的任务,启动Worker进程运行。
一个Topology运行之后,就会不断通过Spout来发送Stream流,通过Bolt来不断处理接收到的数据流。
父主题: 调优概述