组件原理
Hive
Hive引擎把客户提交的SQL类作业,转译成MR作业,在Yarn的资源调度下,访问HDFS数据,对外呈现就像是一个SQL数据库,组件架构如图1所示。
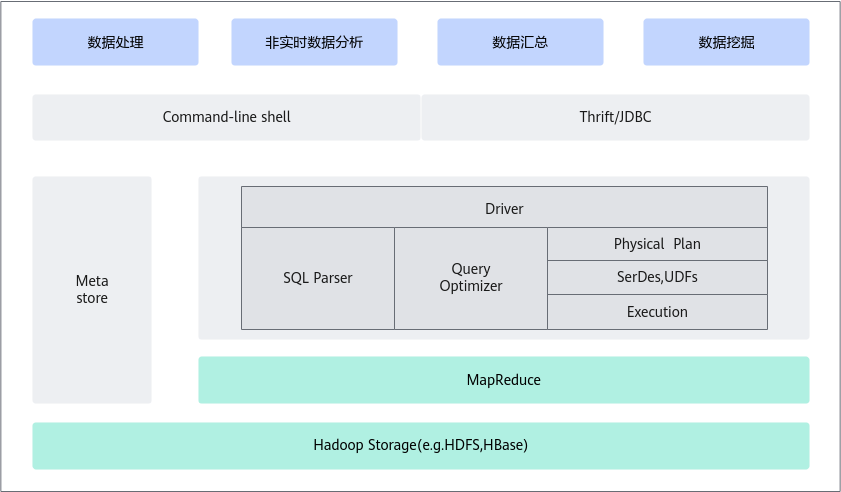
- Hive使用Yarn作为资源调度系统,支持按照比例、绝对值等多种资源配置方式,支持按照物理节点隔离资源。
- 支持节点线性扩展,对硬件要求低。
- 支持TXT、Sequence、ORC和Parquet多种文件或数据格式,支持数据压缩和数据加密。
Spark
Spark SQL引擎把客户提交的SQL类作业,转译成Spark作业,在Yarn的资源调度下,访问HDFS数据,对外呈现就像是一个SQL数据库,组件架构如图2所示。
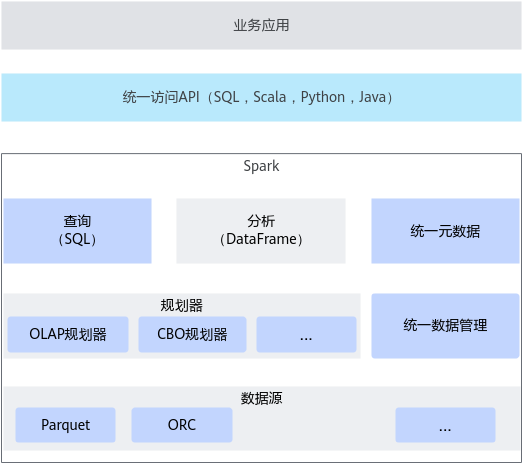
Spark和MapReduce都是Hadoop中最基础的分布式计算框架,主要用来执行非SQL类的批处理作业,如复杂挖掘和机器学习。区别在于Spark主要依赖内存迭代,MapReduce则依赖HDFS存储中间结果数据。
Spark相比MapReduce的特点:
- 内存迭代速度快,比MapReduce快5~10倍。
- 内置函数和算法多,支持MLlib、Mahout等多种数据挖掘和统计分析算法库。
- 硬件要求高,对内存容量要求大。
父主题: 离线分析