OmniRuntime OmniData算子下推
在大数据存算分离或存算融合大规模集群场景(>200)下,计算任务无法保证数据本地性。原有计算引擎的算子实现均是在计算节点执行,从存储节点将涉及的表行列数据全量读取到计算节点,执行过滤、聚合等算子操作。在数据本地性无法保证的存算分离和大规模存算融合场景下,大量数据需要跨网络从存储节点读取到计算节点,效率低,影响大数据计算性能。
OmniRuntime OmniData算子下推特性通过将数据选择率(算子执行的输出数据集大小/算子执行的输入数据集大小)低的算子下推到存储节点执行,实现在存储节点本地读取数据进行计算,有效的结果数据集通过网络返回到计算节点,提升网络传输效率,优化大数据计算性能。
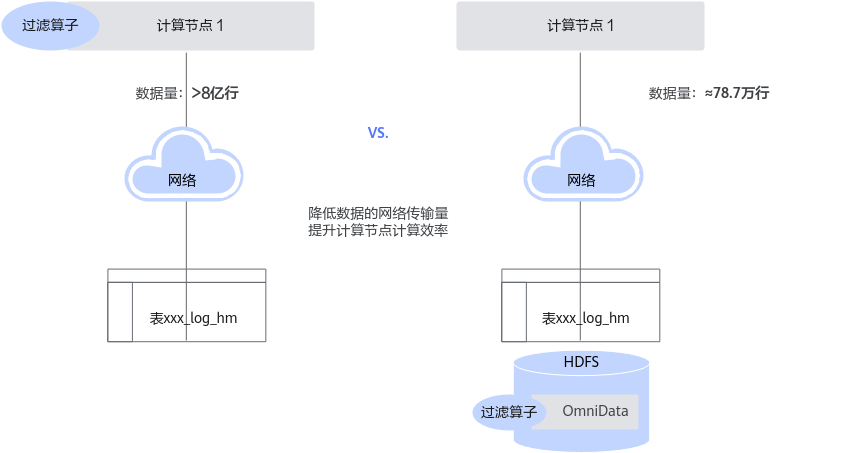
以某业务SQL为例,在where的条件子句中有多个针对表字段的过滤算子操作。
… ( SELECT logid AS xxx …… FROM xxx_log_hm WHERE pt_d = '20200709' AND optype='11' AND substr(downloadTime, 1, 10) = '20200709' ) …
计算引擎例如Spark提供CBO的统计信息,可以通过统计信息获取这些过滤算子的选择率。在该例子中,算子的输入数据集大小为8亿行,输出数据集大小为78.7万行,数据的选择率为千分之一左右。将这些过滤算子下推到存储节点OmniData服务上执行,极大降低了数据的网络传输量,SQL计算耗时从3855.67秒降低到2084.33秒。OmniData算子下推特性支持设定算子下推的选择率值,同时支持单个JOB级别的下推开关。
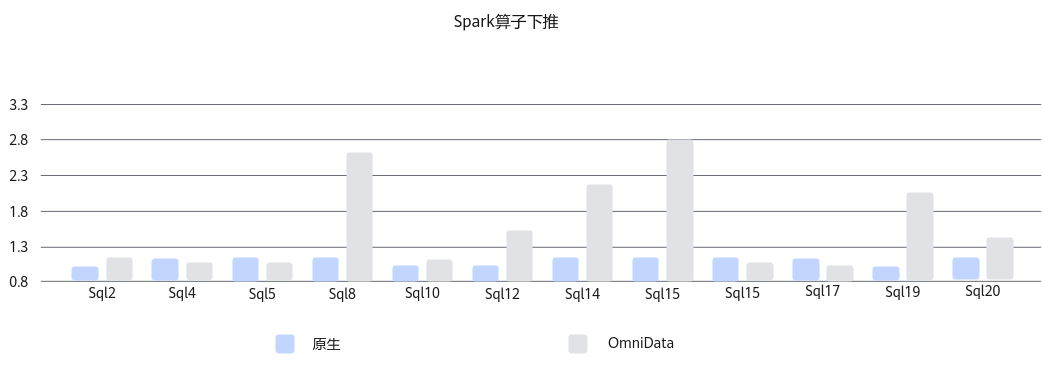
Spark在大数据典型硬件配置的存算分离场景下,运行标准测试用例TPC-H,采用OmniData算子下推特性,开启下推的12条SQL平均性能提升54%。
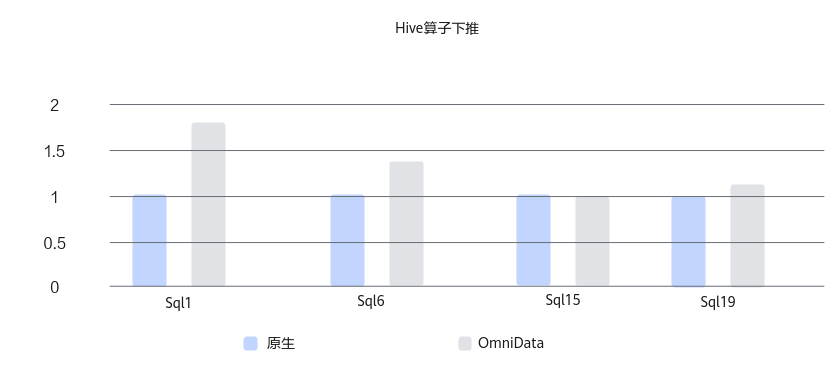
Hive在大数据典型硬件配置的存算分离场景下,运行标准测试用例TPC-H,采用OmniData算子下推特性,开启下推的4条SQL平均性能提升32%。
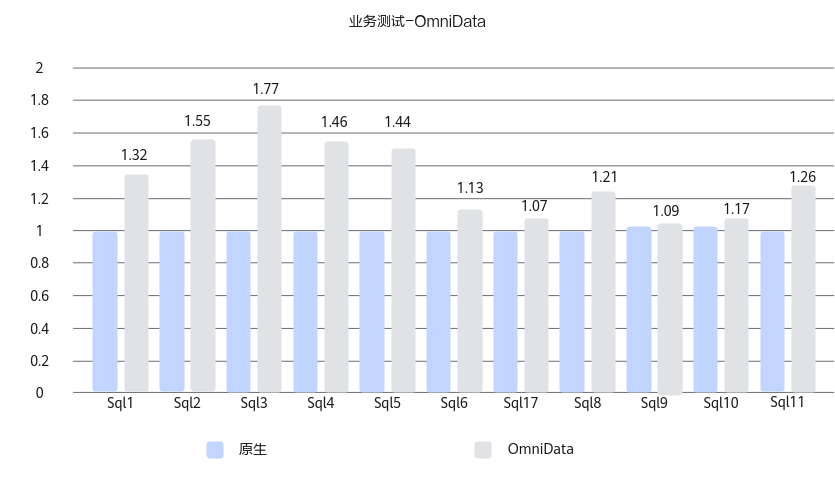
在某客户200台大数据存算融合场景下,Spark组件通过使用OmniData算子下推,实现算子的近数据计算,限制存储节点上OmniData算子下推服务使用10 core计算资源,实际业务性能平均提升26%,最高提升77%。