OmniRuntime OmniShuffle Shuffle加速
大数据分析业务场景中,数据呈现多源、异构特征,数据量井喷式增长,数据分析成本越来越高。在大部分数据分析场景中,数据的迭代过程存在着大量Disk Shuffle,从而会导致数据分析及索引构建的时间过长等问题。
OmniRuntime OmniShuffle Shuffle加速作为大数据引擎Spark的性能加速组件,运行在客户数据中心的大数据集群内,通过内存池统一编址、数据内存语义交换及融合Shuffle等关键特性,减少数据磁盘I/O开销,提高数据分析的时效性和集群资源利用率。
图1 OmniShuffle Shuffle加速原理图
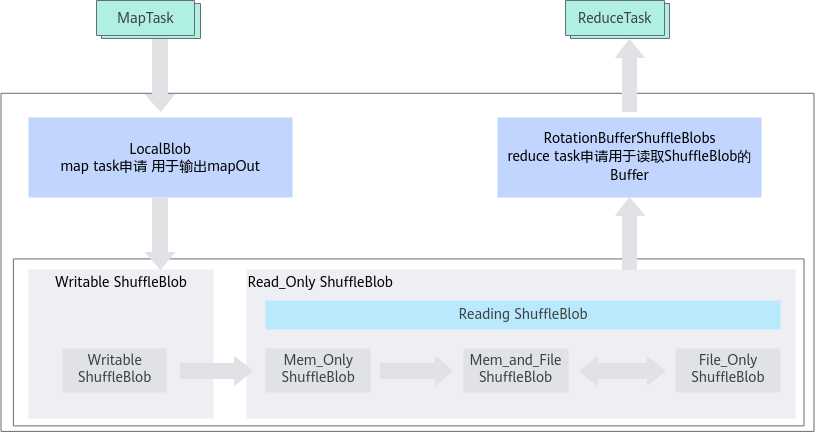
OmniShuffle Shuffle加速关键技术
- In-memory Shuffle是OmniShuffle Shuffle加速提升性能的核心技术,其基本原理是优化Shuffle过程,将的过程优化为内存语义操作,减少落盘开销,从而提升Shuffle数据读写的效率。
- 数据聚合:Spark Shuffle过程的一个特点是会有大量的数据块需要完成跨节点交换,典型的应用场景是Spark作业流程中,根据Spark executor的数量设置不同,可能会有数十万甚至数百万次的跨节点数据交换。大量的数据块跨节点交换带来了巨大的协议和网络开销,每次交换都需要经过建立链接、打开文件、数据传输、关闭文件、关闭链接等复杂的流程,如果每个待交换数据块的尺寸较小,如只有几十或者几百KB,数据交换过程的协议开销将成为重要瓶颈,测试数据表明,对于一个百KB级的数据块交换,端到端流程需要数十毫秒,但是真正的数据传输仅需要1毫秒左右,协议的开销占比超过了90%。OmniShuffle Shuffle加速在不同Map任务产生Shuffle数据后,将单个节点内属于同一个Shuffle阶段的同一个Partition的数据被聚合到一块或者多块连续的内存资源中,聚合完成后,释放原有内存资源,通过聚合小块Shuffle数据方式,增大网络传输的IO大小,避免小IO时无法充分发挥网络带宽的问题,减少传输次数,从而提升Shuffle数据传输的效率。
- 融合Shuffle:OmniShuffle Shuffle加速以全内存数据处理作为目标,但是并非所有场景下均可实现,当数据处理的内存需求大于内存池容量时,需要保证数据处理作业可以正常完成并尽可能减少对性能的影响。融合Shuffle的核心思想是在内存容量不足以存放所有Shuffle数据的情况下,将部分内存中的Shuffle数据暂存到本地文件系统,分批完成Shuffle数据的跨节点交换。
- 列式Shuffle:OmniShuffle Shuffle加速提升了节点之间数据Shuffle的效率,OmniOperator算子加速提升了节点内算子计算性能,两者在流程上通过叠加可以实现性能上的叠加。但因为OmniOperator算子加速是基于堆外的列式存储结构,而Spark是按照行数据进行处理,所以在Spark的端到端流程中会存在多次行列转换、堆内外复制以及序列化/反序列化过程,从而影响任务的端到端性能。OmniShuffle Shuffle加速通过实现Native的Shuffle,消除堆内外内存复制;在Writer和Reader中适配堆外的列式数据结构,消除行列转换和序列化/反序列化过程,从而进一步提升OmniShuffle Shuffle加速与OmniOperator算子加速两者叠加后的性能。
- 支持ESS和RSS两种模式。ESS模式下,OmniShuffle与Spark部署在相同的节点。RSS模式下,OmniShuffle部署在独立的集群,以实现存储集群和计算集群的解耦,提供高性能/高可用/可伸缩的通用Shuffle服务。
- Boost Tuning:OCK Boost Tuning for Spark SQL通过基于历史记录的实时调整实现Spark SQL作业的并行度自动调整,消除用户针对并行度的调优工作量,同时减少90%以上Shuffle Reduce侧Spill,从而实现缩短作业运行时间,提高大数据集群作业吞吐量。
OmniShuffle Shuffle加速性能提升
384GB内存/节点,4节点集群(3个计算节点+1个管理节点),每节点配置双路鲲鹏920 5220处理器,至少10GE网络(10GE TCP、25GE TCP/RDMA 100GE TCP/RDMA),12×4TB SATA盘典型配置。
在ESS模式下:
- Terasort场景:1TB数据量,性能提升40%+。
- PageRank(Spark Core)场景:90GB数据量,性能提升100%+。
- TPC-DS场景:8TB数据量,OmniShuffle Shuffle加速Spark性能提升30%,OmniShuffle Shuffle加速叠加OmniOperator算子加速Spark性能提升60%+。
图2 OmniShuffle Shuffle加速基于TPC-DS性能测试结果
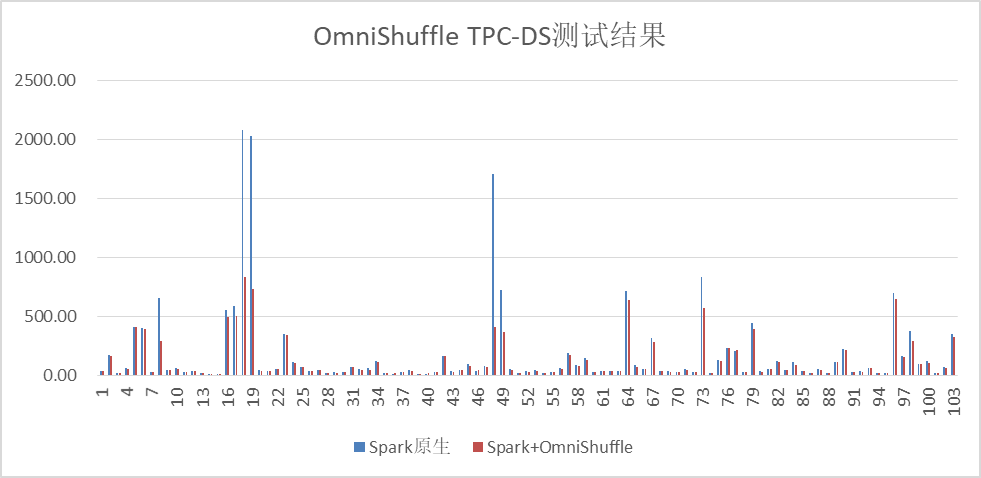 图3 OmniShuffle Shuffle加速叠加OmniOperator算子加速基于TPC-DS性能测试结果
图3 OmniShuffle Shuffle加速叠加OmniOperator算子加速基于TPC-DS性能测试结果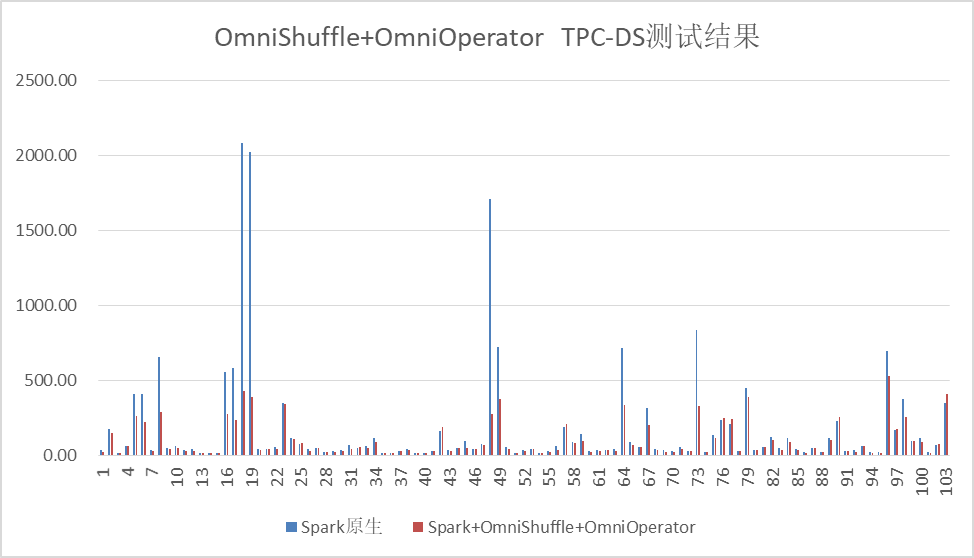
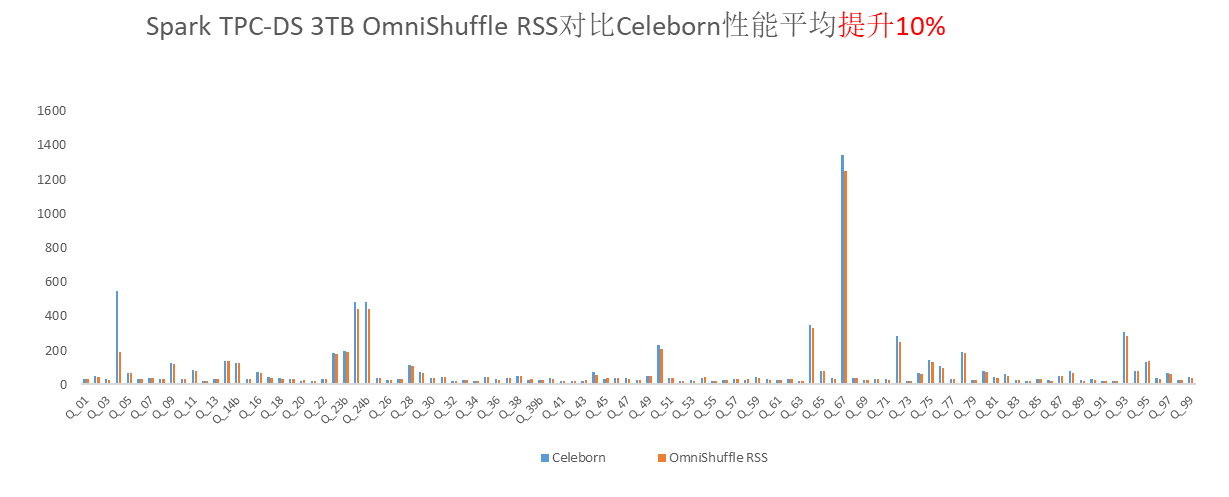
在RSS模式下:
TPC-DS场景:3TB数据量,相比友商Celeborn性能提升10%。
图4 OmniShuffle Shuffle加速基于TPC-DS性能测试结果
父主题: 方案特性