CD
run API
- API
run(edgeInfo: RDD[(Long, Long, Double)],part: Int,minLoopLen: Int,maxLoopLen: Int,minRate: Double,maxRate: Double): RDD[Array[Long]]
- 功能描述
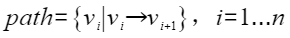
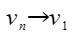
- API描述
- 包名:package org.apache.spark.graphx.lib
- 类名:CycleDetectionWithConstrains
- 方法名:run
- 输入:
- 参数详情:
参数名称
参数含义
取值类型
graph
带权重的有向图边数据
RDD[(Long, Long,Double)],边权重为正数
part
计算时分区个数
Int如100等,正整数
minLoop
小的环路长度
Int,一般取值为2以上,正整数
maxLoop
大的环路长度
Int,一般取值为10以下,正整数,需大于等于minLoop
minRate
小的边权比
Double如0.8等,正浮点数
maxRate
大的边权比
Double如1.2等,正浮点数,需大于等于minRate
- 核心参数:
- minLoop: 小的环路长度。
- maxLoop: 长的环路长度。
- minRate: 边权比(下一边/当前边) 小的比率。
- maxRate: 边权比(下一边/当前边)最大的比率。
g. 输出:RDD[Array[Long]] 满足约束的环路信息,即环路长度在[minLoop,maxLoop],边权比在[minRate, maxRate]。其中每一行表示一个环,以节点ID表示,顺序是环路的次序,无起始之分。
- 使用样例
CycleDetectionWithConstrains样例:
val conf = new SparkConf().setAppName("Cycle Detection").setMaster(host) val sc = new SparkContext(conf) val input = sc.parallelize(Array((1, 2, 11), (2, 3, 12), (2, 4, 12), (3, 4, 13), (4, 1, 12))) .map(f => (f._1.toLong, f._2.toLong, f._3.toDouble)) val part = 1 val minLoopLen = 2 val maxLoopLen = 10 val minRate = 0.8 val maxRate = 1.2 val cycles = CycleDetectionWithConstrains.run(input, part, minLoopLen, maxLoopLen, minRate, maxRate) - 样例结果

每一行表示一个环路信息,以节点ID为标识,符合上述约束。
1,2,4 1,2,3,4
父主题: 算法API