实现原理
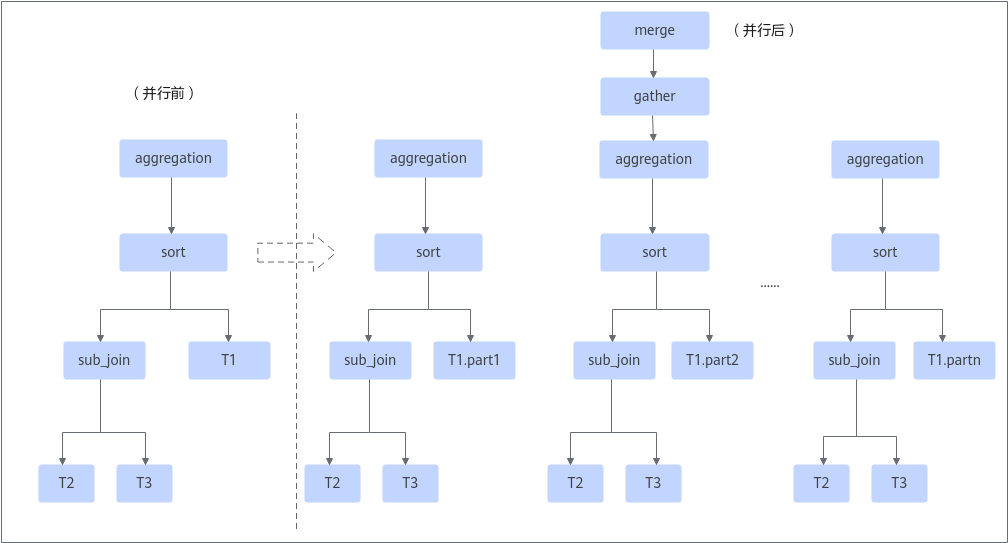
在并行查询中涉及到2个关键事件:表的切分和执行计划的改造。
- 表的切分
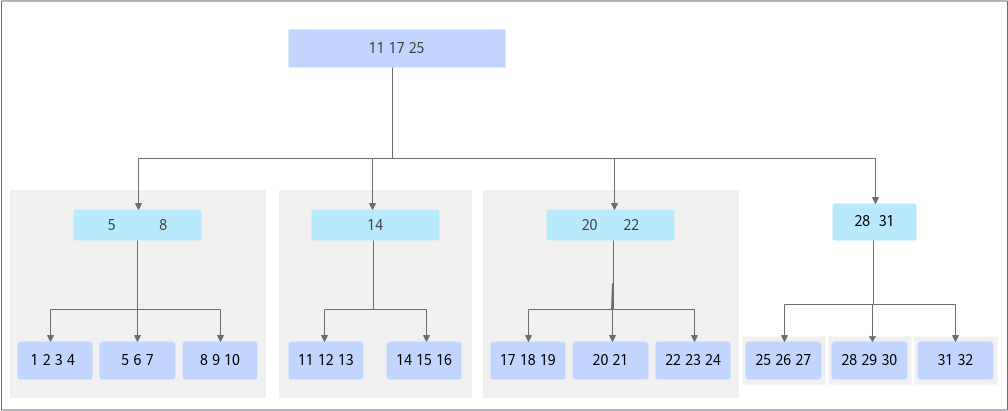
将扫描的数据划分成多份,让多个线程并行扫描。innoDB引擎是索引组织表,数据以B+tree的形式存储在磁盘上。分区的逻辑为,从根节点页面出发,逐层往下扫描,当判断某一层的分支数超过了配置的线程数,则停止拆分。在实现时,实际上总共会进行两次分区。第一次是按根节点页的分支数划分分区,每个分支的最左叶子节点的记录为左下界,并将这个记录记为相邻上一个分支的右上界。通过这种方式,将B+tree划分成若干子树,每个子树就是一个扫描分区。经过第一次分区后,可能出现分区数不能充分利用多核问题,比如配置了并行扫描线程为3,第一次分区后,产生了4个分区,那么前3个分区并行做完后,第4个分区至多只有一个线程扫描,最终效果就是不能充分利用多核资源。
为解决第一次分区的负载不均衡问题,将对第4个分区进行第二次分区。第二次分区后,可以获得多个更小数据量的块,这样可以使每个线程的扫描数据更加均衡。
父主题: 并行查询特性介绍