执行任务并查看结果
在客户端下载并解压样例工程-开发程序中样例代码中对应的数据集到“/tmp/data/epsilon”目录,并执行任务,具体步骤如下。
- 进入“/tmp/data”目录。
1cd /tmp/data
- 获取公开数据集并上传数据集到HDFS上(eg. graph500-23.zip)。
1hadoop fs -put /tmp/data/graph500-23.e /tmp/graph_data
- 将样例工程-开发程序中生成的kal_examples_2.11-0.1.jar和run_tc.sh放入客户端“/home/test/boostkit/”目录,并在目录下执行./run_tc.sh。如果遇到写文件的权限问题,建议使用hdfs用户执行命令。
run_tc.sh内容如下。
1 2 3 4 5 6 7 8 9 10 11
spark-submit \ --class com.bigdata.examples.TCRunner \ --driver-class-path "./lib/*" \ --jars "./lib/boostkit-graph-kernel-2.11-2.2.0-spark2.3.2-aarch64.jar" \ --conf "spark.executor.extraClassPath=boostkit-graph-kernel-2.11-2.2.0-spark2.3.2-aarch64.jar" \ --master yarn \ --deploy-mode client \ --driver-cores 36 \ --driver-memory 50g \ --executor-cores 4 --num-executors 72 --executor-memory 12g \ ./kal_examples_2.11-0.1.jar
- 执行任务。
1sh run_tc.shTriangleCounting is finished , and costTime = 82.14 's
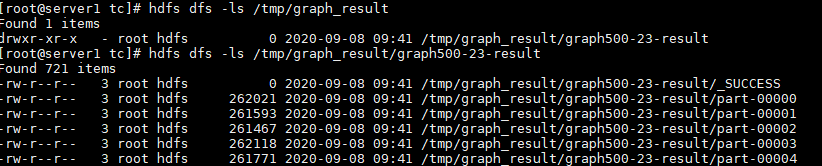
- 查看结果。
hdfs dfs -ls graph_data/graph500-23-result
父主题: 样例工程