分类回归
场景介绍
分类回归分析是一种预测性的建模技术,其目的是探索标签和特征之间的联系。其中,标签可以视作因变量,特征可以视作自变量。此类算法通常被用于预测分析和建模回归。
实际应用中,Linear Regression算法和Logistic Regression等算法通常被应用于互联网金融P2P业务信用风险分析和路网交通流量预测等场景;SVM被应用于国际碳金融市场价格预测和路网交通流量预测等场景;GBDT、XGBoost等算法通常被应用于债务风险评级和预警、出行方式推荐等场景。
回归类算法通常涉及多次迭代,收敛逼近标签变量来进行训练。鲲鹏BoostKit大数据机器学习算法库通过优化迭代算法,充分发挥鲲鹏芯片高并发的特点,并同时减少训练过程中的收敛迭代次数实现性能倍级提升。
算法原理
- GBDT算法
GBDT(Gradient Boosting Decision Tree,梯度提升决策树)算法是一种十分流行的决策树集成算法,不仅可以适用于分类任务,也可用于回归任务。GBDT通过迭代地训练多棵树来达到最小化损失函数的目的。Spark中的GBDT算法支持二分类和回归,支持连续性特征和类别型特征,通过分布式计算来处理大数据场景下的训练和推理。
- Random Forest算法
Random Forest,随机森林算法实现如下功能:给定一份样本数据,包含特征向量和标签值,同时训练多棵决策树,得到一个分类模型或回归模型。使用输出的模型,传入特征向量,可预测出概率最大的标签值。
- SVM算法
SVM(Support Vector Machines,支持向量机)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。SVM使用铰链损失函数计算经验风险并在求解系统中加入了正则化项以优化结构风险,是一个具有稀疏性和稳健性的分类器。Spark中的LinearSVC算法主要引入了两个优化策略:通过算法原理优化减少对f函数(分布式计算目标函数损失和梯度)的调用次数;增加动量参数更新加速收敛。
- Decision Tree算法
Decision Tree,决策树算法是机器学习、计算机视觉等领域内应用极为广泛的一个算法,它不仅可以用来做分类,也可用来做回归。决策树(Decision Tree)算法实现如下功能:给定一份样本数据,包含特征向量和标签值,训练一棵二叉树,得到一个分类模型或回归模型。使用输出的模型,传入特征向量,可预测出概率最大的标签值。
- Linear Regression算法
回归算法是一种有监督学习算法,用来建立自变量X和观测变量Y之间的映射关系。如果观测变量是连续的,则称其为回归(Regression)。机器学习中,线性回归(Linear Regression)利用线性模型来建模自变量X和观测变量Y之间的映射关系,其未知的模型参数是从训练数据中估计。
- Logistic Regression算法
Logistic Regression,逻辑回归算法虽然名字里带“回归”,但是它实际上是一种分类方法。逻辑回归是利用线性模型来建模自变量X和观测变量Y之间的映射关系,其未知的模型参数是从训练数据中估计的。
- XGBoost算法
XGBoost(极端梯度提升算法)是一个深度优化的分布式梯度提升算法库,拥有高效、灵活和可移植的特性。该库在梯度提升的框架下实现机器学习算法,提供了一个并行树提升算法,可以快速而准确地解决许多数据科学问题。
- KNN算法
KNN(K-Nearest Neighbors,K最近邻算法)是一种机器学习领域中的非参数统计法,用于找到距离给定样本最近的k个样本。可以用于分类、回归、信息检索等领域。
编程实例
本示例以GBDT算法来介绍编程示例。
GBDT分为ML Classification API和ML Regression API两大类模型接口。
|
模型接口类别 |
函数接口 |
|---|---|
|
ML Classification API |
def fit(dataset: Dataset[_]): GBTClassificationModel |
|
def fit(dataset: Dataset[_], paramMap: ParamMap): GBTClassificationModel |
|
|
def fit(dataset: Dataset[_], paramMaps: Array[ParamMap]): Seq[GBTClassificationModel] |
|
|
def fit(dataset: Dataset[_], firstParamPair: ParamPair[_], otherParamPairs: ParamPair[_]*): GBTClassificationModel |
|
|
ML Regression API |
def fit(dataset: Dataset[_]): GBTRegressionModel |
|
def fit(dataset: Dataset[_], paramMap: ParamMap): GBTRegressionModel |
|
|
def fit(dataset: Dataset[_], paramMaps: Array[ParamMap]): Seq[GBTRegressionModel] |
|
|
def fit(dataset: Dataset[_], firstParamPair: ParamPair[_], otherParamPairs: ParamPair[_]*): GBTRegressionModel |
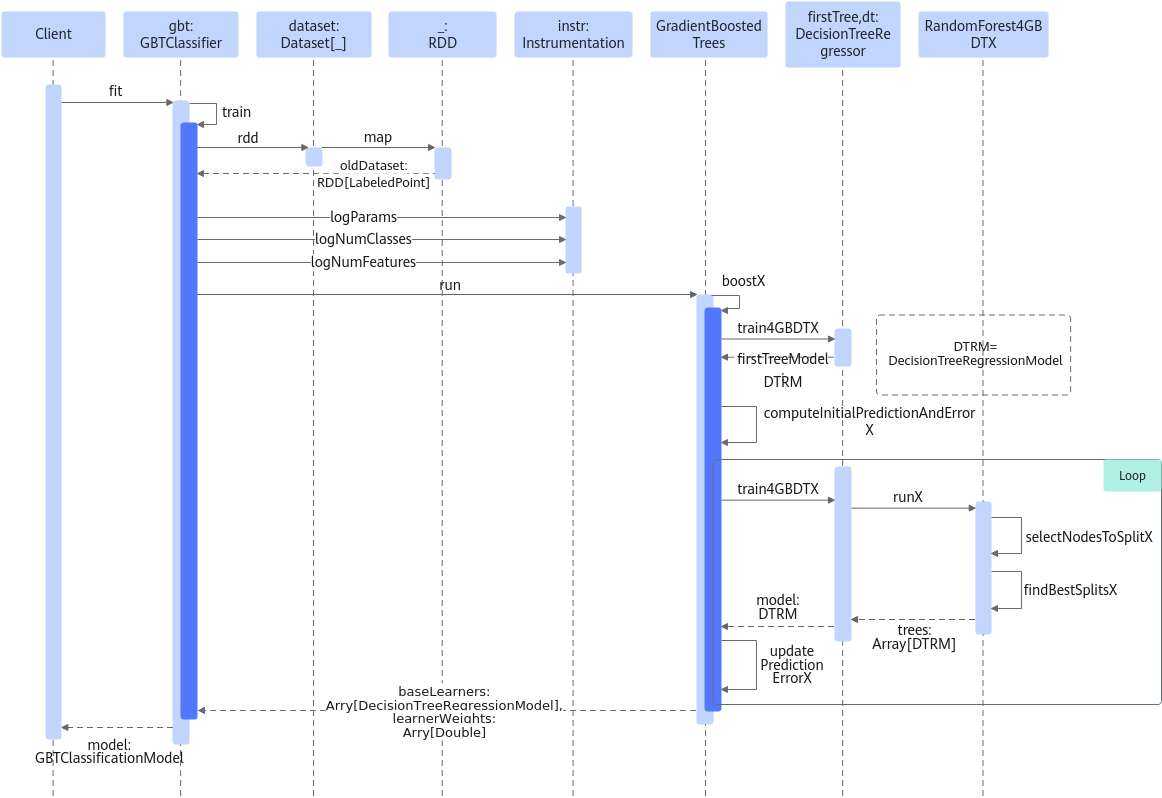
GBDT算法分类模型时序图如图1所示。
ML Classification API
- 输入输出
- 包名:package org.apache.spark.ml.classification
- 类名:GBTClassifier
- 方法名:fit
- 输入:Dataset[_],训练样本数据,必须字段如下。
参数名称
取值类型
缺省值
描述
labelCol
Double
label
预测标签
featuresCol
Vector
features
特征标签
- 输入:paramMap,paramMaps, firstParamPair, otherParamPairs,fit接口的模型参数,说明如下。
参数名称
取值类型
示例
描述
paramMap
ParamMap
ParamMap(A.c -> b)
将b的值赋给模型A的参数c
paramMaps
Array[ParamMap]
Array[ParamMap](n)
形成n个ParamMap模型参数列表
firstParamPair
ParamPair
ParamPair(A.c, b)
将b的值赋给模型A的参数c
otherParamPairs
ParamPair
ParamPair(A.e, f)
将f的值赋给模型A的参数e
- 基于原生算法优化的参数
def setCheckpointInterval(value: Int): GBTClassifier.this.type def setFeatureSubsetStrategy(value: String): GBTClassifier.this.type def setFeaturesCol(value: String): GBTClassifier def setImpurity(value: String): GBTClassifier.this.type def setLabelCol(value: String): GBTClassifier def setLossType(value: String): GBTClassifier.this.type def setMaxBins(value: Int): GBTClassifier.this.type def setMaxDepth(value: Int): GBTClassifier.this.type def setMaxIter(value: Int): GBTClassifier.this.type def setMinInfoGain(value: Double): GBTClassifier.this.type def setMinInstancesPerNode(value: Int): GBTClassifier.this.type def setPredictionCol(value: String): GBTClassifier def setProbabilityCol(value: String): GBTClassifierdoUseAcc def setRawPredictionCol(value: String): GBTClassifier def setSeed(value: Long): GBTClassifier.this.type def setStepSize(value: Double): GBTClassifier.this.type def setSubsamplingRate(value: Double): GBTClassifier.this.type def setThresholds(value: Array[Double]): GBTClassifier
- 新增算法参数。
参数名称
参数含义
取值类型
doUseAcc
特征并行训练模式开关
True/False[Boolean]

参数及fit代码接口示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
import org.apache.spark.ml.param.{ParamMap, ParamPair} val gbdt = new GBTClassifier() //定义def fit(dataset: Dataset[_], paramMap: ParamMap) 接口参数 val paramMap = ParamMap(gbdt.maxDepth -> maxDepth) .put(gbdt.maxIter, maxIter) // 定义def fit(dataset: Dataset[_], paramMaps: Array[ParamMap]): 接口参数 val paramMaps: Array[ParamMap] = new Array[ParamMap](2) for (i <- 0 to 2) { paramMaps(i) = ParamMap(gbdt.maxDepth -> maxDepth) .put(gbdt.maxIter, maxIter) }//对paramMaps进行赋值 // 定义def fit(dataset: Dataset[_], firstParamPair: ParamPair[_], otherParamPairs: ParamPair[_]*) 接口参数 val maxDepthParamPair = ParamPair(gbdt.maxDepth, maxDepth) val maxIterParamPair = ParamPair(gbdt.maxIter, maxIter) val maxBinsParamPair = ParamPair(gbdt.maxBins, maxBins) // 调用各个fit接口 model = gbdt.fit(trainingData) model = gbdt.fit(trainingData, paramMap) models = gbdt.fit(trainingData, paramMaps) model = gbdt.fit(trainingData, maxDepthParamPair, maxIterParamPair, maxBinsParamPair)
- 输出:GBTClassificationModel,GBDT分类模型,模型预测时的输出字段。
参数名称
取值类型
缺省值
描述
predictionCol
Double
prediction
Predicted label
- 使用样例
fit(dataset: Dataset[_]): GBTClassificationModel样例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57
import org.apache.spark.ml.Pipeline import org.apache.spark.ml.classification.{GBTClassificationModel, GBTClassifier} import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer} // Load and parse the data file, converting it to a DataFrame. val data = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt") // Index labels, adding metadata to the label column. // Fit on whole dataset to include all labels in index. val labelIndexer = new StringIndexer() .setInputCol("label") .setOutputCol("indexedLabel") .fit(data) // Automatically identify categorical features, and index them. // Set maxCategories so features with > 4 distinct values are treated as continuous. val featureIndexer = new VectorIndexer() .setInputCol("features") .setOutputCol("indexedFeatures") .setMaxCategories(4) .fit(data) // Split the data into training and test sets (30% held out for testing). val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3)) // Train a GBT model. val gbt = new GBTClassifier() .setLabelCol("indexedLabel") .setFeaturesCol("indexedFeatures") .setMaxIter(10) // Convert indexed labels back to original labels. val labelConverter = new IndexToString() .setInputCol("prediction") .setOutputCol("predictedLabel") .setLabels(labelIndexer.labels) // Chain indexers and GBT in a Pipeline. val pipeline = new Pipeline() .setStages(Array(labelIndexer, featureIndexer, gbt, labelConverter)) // Train model. This also runs the indexers. val model = pipeline.fit(trainingData) // Make predictions. val predictions = model.transform(testData) // Select (prediction, true label) and compute test error. val evaluator = new MulticlassClassificationEvaluator() .setLabelCol("indexedLabel") .setPredictionCol("prediction") .setMetricName("accuracy") val accuracy = evaluator.evaluate(predictions) println("Test Error = " + (1.0 - accuracy)) val gbtModel = model.stages(2).asInstanceOf[GBTClassificationModel] println("Learned classification GBT model:\n" + gbtModel.toDebugString)
- 结果样例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158
Test Error = 0.0714285714285714 Learned classification GBT model: GBTClassificationModel (uid=gbtc_72086dba9af5) with 10 trees Tree 0 (weight 1.0): If (feature 406 <= 9.5) Predict: 1.0 Else (feature 406 > 9.5) Predict: -1.0 Tree 1 (weight 0.1): If (feature 406 <= 9.5) If (feature 209 <= 241.5) If (feature 154 <= 55.0) Predict: 0.4768116880884702 Else (feature 154 > 55.0) Predict: 0.4768116880884703 Else (feature 209 > 241.5) Predict: 0.47681168808847035 Else (feature 406 > 9.5) If (feature 461 <= 143.5) Predict: -0.47681168808847024 Else (feature 461 > 143.5) Predict: -0.47681168808847035 Tree 2 (weight 0.1): If (feature 406 <= 9.5) If (feature 657 <= 116.5) If (feature 154 <= 9.5) Predict: 0.4381935810427206 Else (feature 154 > 9.5) Predict: 0.43819358104272066 Else (feature 657 > 116.5) Predict: 0.43819358104272066 Else (feature 406 > 9.5) If (feature 322 <= 16.0) Predict: -0.4381935810427206 Else (feature 322 > 16.0) Predict: -0.4381935810427206 Tree 3 (weight 0.1): If (feature 406 <= 9.5) If (feature 598 <= 166.5) If (feature 180 <= 3.0) Predict: 0.4051496802845983 Else (feature 180 > 3.0) Predict: 0.4051496802845984 Else (feature 598 > 166.5) Predict: 0.4051496802845983 Else (feature 406 > 9.5) Predict: -0.4051496802845983 Tree 4 (weight 0.1): If (feature 406 <= 9.5) If (feature 537 <= 47.5) If (feature 606 <= 7.0) Predict: 0.3765841318352991 Else (feature 606 > 7.0) Predict: 0.37658413183529926 Else (feature 537 > 47.5) Predict: 0.3765841318352994 Else (feature 406 > 9.5) If (feature 124 <= 35.5) If (feature 376 <= 1.0) If (feature 516 <= 26.5) If (feature 266 <= 50.5) Predict: -0.3765841318352991 Else (feature 266 > 50.5) Predict: -0.37658413183529915 Else (feature 516 > 26.5) Predict: -0.3765841318352992 Else (feature 376 > 1.0) Predict: -0.3765841318352994 Else (feature 124 > 35.5) Predict: -0.3765841318352994 Tree 5 (weight 0.1): If (feature 406 <= 9.5) If (feature 570 <= 3.5) Predict: 0.35166478958101005 Else (feature 570 > 3.5) Predict: 0.35166478958101 Else (feature 406 > 9.5) If (feature 266 <= 14.0) If (feature 267 <= 12.5) Predict: -0.35166478958101005 Else (feature 267 > 12.5) If (feature 267 <= 36.0) Predict: -0.35166478958101005 Else (feature 267 > 36.0) Predict: -0.3516647895810101 Else (feature 266 > 14.0) Predict: -0.35166478958101005 Tree 6 (weight 0.1): If (feature 406 <= 9.5) If (feature 207 <= 7.5) Predict: 0.32974984655529926 Else (feature 207 > 7.5) Predict: 0.3297498465552993 Else (feature 406 > 9.5) If (feature 490 <= 185.0) Predict: -0.32974984655529926 Else (feature 490 > 185.0) Predict: -0.3297498465552993 Tree 7 (weight 0.1): If (feature 406 <= 9.5) If (feature 568 <= 22.0) Predict: 0.3103372455197956 Else (feature 568 > 22.0) Predict: 0.31033724551979563 Else (feature 406 > 9.5) If (feature 379 <= 133.5) If (feature 237 <= 250.5) Predict: -0.3103372455197956 Else (feature 237 > 250.5) Predict: -0.3103372455197957 Else (feature 379 > 133.5) If (feature 433 <= 183.5) If (feature 516 <= 9.0) Predict: -0.3103372455197956 Else (feature 516 > 9.0) Predict: -0.3103372455197957 Else (feature 433 > 183.5) Predict: -0.3103372455197957 Tree 8 (weight 0.1): If (feature 406 <= 9.5) If (feature 184 <= 19.0) Predict: 0.2930291649125433 Else (feature 184 > 19.0) If (feature 155 <= 147.0) If (feature 180 <= 3.0) Predict: 0.2930291649125433 Else (feature 180 > 3.0) Predict: 0.2930291649125433 Else (feature 155 > 147.0) Predict: 0.2930291649125434 Else (feature 406 > 9.5) If (feature 379 <= 133.5) Predict: -0.2930291649125433 Else (feature 379 > 133.5) If (feature 433 <= 52.5) Predict: -0.2930291649125433 Else (feature 433 > 52.5) If (feature 462 <= 143.5) Predict: -0.2930291649125433 Else (feature 462 > 143.5) Predict: -0.2930291649125434 Tree 9 (weight 0.1): If (feature 406 <= 9.5) If (feature 183 <= 3.0) Predict: 0.27750666438358246 Else (feature 183 > 3.0) If (feature 183 <= 19.5) Predict: 0.27750666438358246 Else (feature 183 > 19.5) Predict: 0.2775066643835825 Else (feature 406 > 9.5) If (feature 239 <= 50.5) If (feature 435 <= 102.0) Predict: -0.27750666438358246 Else (feature 435 > 102.0) Predict: -0.2775066643835825 Else (feature 239 > 50.5) Predict: -0.27750666438358257
ML Regression API
- 输入输出
- 包名:package org.apache.spark.ml.classification
- 类名:GBTRegressor
- 方法名:fit
- 输入:Dataset[_],训练样本数据,必须字段如下。
参数名称
取值类型
缺省值
描述
labelCol
Double
label
预测标签
featuresCol
Vector
features
特征标签
- 输入:paramMap,paramMaps, firstParamPair, otherParamPairs,fit接口的模型参数,说明如下。
参数名称
取值类型
示例
描述
paramMap
ParamMap
ParamMap(A.c -> b)
将b的值赋给模型A的参数c
paramMaps
Array[ParamMap]
Array[ParamMap](n)
形成n个ParamMap模型参数列表
firstParamPair
ParamPair
ParamPair(A.c, b)
将b的值赋给模型A的参数c
otherParamPairs
ParamPair
ParamPair(A.e, f)
将f的值赋给模型A的参数e
- 基于原生算法优化的参数
def setCheckpointInterval(value: Int): GBTRegressor.this.type def setFeatureSubsetStrategy(value: String): GBTRegressor.this.type def setFeaturesCol(value: String): GBTRegressor def setImpurity(value: String): GBTRegressor.this.type def setLabelCol(value: String): GBTRegressor def setLossType(value: String): GBTRegressor.this.type def setMaxBins(value: Int): GBTRegressor.this.type def setMaxDepth(value: Int): GBTRegressor.this.type def setMaxIter(value: Int): GBTRegressor.this.type def setMinInfoGain(value: Double): GBTRegressor.this.type def setMinInstancesPerNode(value: Int): GBTRegressor.this.type def setPredictionCol(value: String): GBTRegressor def setSeed(value: Long): GBTRegressor.this.type def setStepSize(value: Double): GBTRegressor.this.type def setSubsamplingRate(value: Double): GBTRegressor.this.type
参数及fit代码接口示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
import org.apache.spark.ml.param.{ParamMap, ParamPair} val gbdt = new GBTRegressor() //定义回归模型 //定义def fit(dataset: Dataset[_], paramMap: ParamMap) 接口参数 val paramMap = ParamMap(gbdt.maxDepth -> maxDepth) .put(gbdt.maxIter, maxIter) // 定义def fit(dataset: Dataset[_], paramMaps: Array[ParamMap]): 接口参数 val paramMaps: Array[ParamMap] = new Array[ParamMap](2) for (i <- 0 to 2) { paramMaps(i) = ParamMap(gbdt.maxDepth -> maxDepth) .put(gbdt.maxIter, maxIter) } //对paramMaps进行赋值 // 定义def fit(dataset: Dataset[_], firstParamPair: ParamPair[_], otherParamPairs: ParamPair[_]*) 接口参数 val maxDepthParamPair = ParamPair(gbdt.maxDepth, maxDepth) val maxIterParamPair = ParamPair(gbdt.maxIter, maxIter) val maxBinsParamPair = ParamPair(gbdt.maxBins, maxBins) // 调用各个fit接口 model = gbdt.fit(trainingData) //返回GBTRegressionModel model = gbdt.fit(trainingData, paramMap) //返回GBTRegressionModel models = gbdt.fit(trainingData, paramMaps) //返回Seq[GBTRegressionModel] model = gbdt.fit(trainingData, maxDepthParamPair, maxIterParamPair, maxBinsParamPair) //返回GBTRegressionModel
- 输出:GBTRegressionModel或Seq[GBTRegressionModel],GBDT回归模型,模型预测时的输出字段如下。
参数名称
取值类型
缺省值
描述
predictionCol
Double
prediction
Predicted label
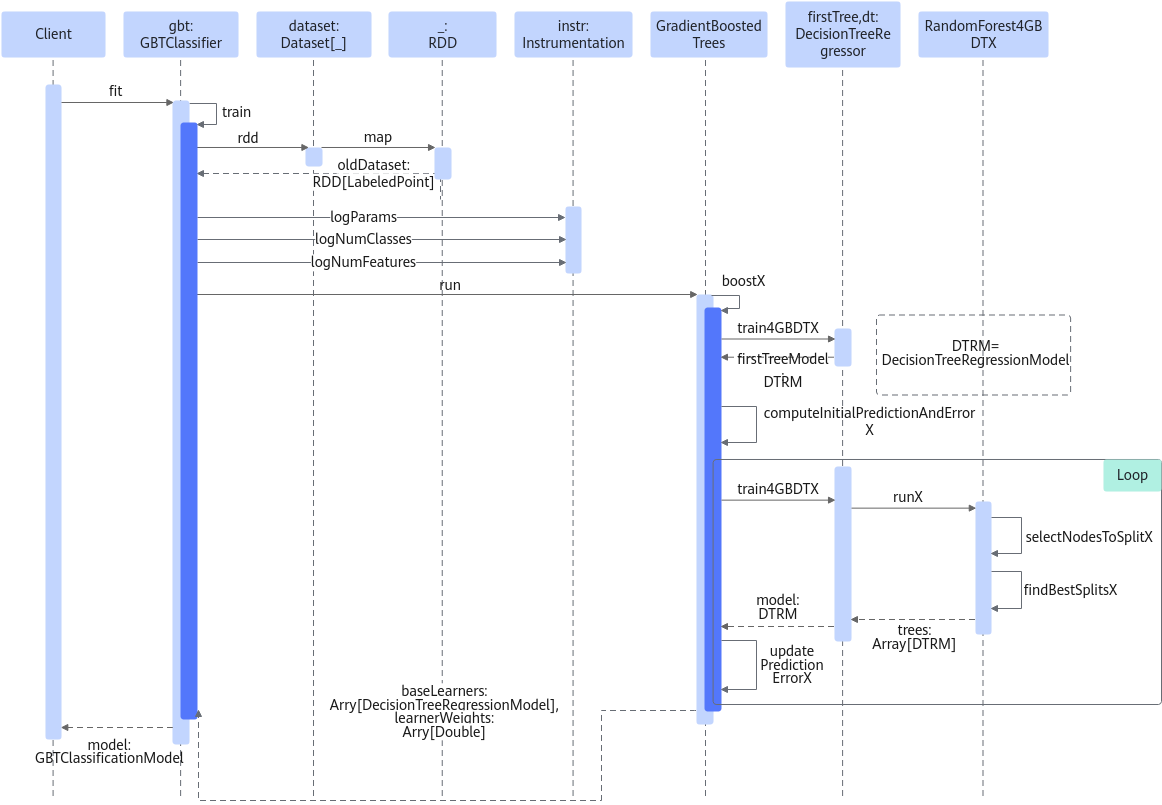
GBDT算法回归模型时序图如图2所示。
- 使用样例
fit(dataset: Dataset[_]): GBTRegressionModel样例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48
import org.apache.spark.ml.Pipeline import org.apache.spark.ml.evaluation.RegressionEvaluator import org.apache.spark.ml.feature.VectorIndexer import org.apache.spark.ml.regression.{GBTRegressionModel, GBTRegressor} // Load and parse the data file, converting it to a DataFrame. val data = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt") // Automatically identify categorical features, and index them. // Set maxCategories so features with > 4 distinct values are treated as continuous. val featureIndexer = new VectorIndexer() .setInputCol("features") .setOutputCol("indexedFeatures") .setMaxCategories(4) .fit(data) // Split the data into training and test sets (30% held out for testing). val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3)) // Train a GBT model. val gbt = new GBTRegressor() .setLabelCol("label") .setFeaturesCol("indexedFeatures") .setMaxIter(10) // Chain indexer and GBT in a Pipeline. val pipeline = new Pipeline() .setStages(Array(featureIndexer, gbt)) // Train model. This also runs the indexer. val model = pipeline.fit(trainingData) // Make predictions. val predictions = model.transform(testData) // Select example rows to display. predictions.select("prediction", "label", "features").show(5) // Select (prediction, true label) and compute test error. val evaluator = new RegressionEvaluator() .setLabelCol("label") .setPredictionCol("prediction") .setMetricName("rmse") val rmse = evaluator.evaluate(predictions) println("Root Mean Squared Error (RMSE) on test data = " + rmse) val gbtModel = model.stages(1).asInstanceOf[GBTRegressionModel] println("Learned regression GBT model:\n" + gbtModel.toDebugString)
- 结果样例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
Root Mean Squared Error (RMSE) on test data = 0.0 Learned regression GBT model: GBTRegressionModel (uid=gbtr_842c8acff963) with 10 trees Tree 0 (weight 1.0): If (feature 434 <= 70.5) If (feature 99 in {0.0,3.0}) Predict: 0.0 Else (feature 99 not in {0.0,3.0}) Predict: 1.0 Else (feature 434 > 70.5) Predict: 1.0 Tree 1 (weight 0.1): Predict: 0.0 Tree 2 (weight 0.1): Predict: 0.0 Tree 3 (weight 0.1): Predict: 0.0 Tree 4 (weight 0.1): Predict: 0.0 Tree 5 (weight 0.1): Predict: 0.0 Tree 6 (weight 0.1): Predict: 0.0 Tree 7 (weight 0.1): Predict: 0.0 Tree 8 (weight 0.1): Predict: 0.0 Tree 9 (weight 0.1): Predict: 0.0