推荐和模式挖掘
场景介绍
随着信息资源规模的迅猛增长和互联网行业的飞速发展,用户在大量繁杂的信息中获得目标内容愈发困难,因此急需商家进行筛选过滤,留下有价值的信息。交替最小二乘法可以通过协同过滤对用户历史购买记录和当前商品进行比较,补全客户历史喜好。
在推荐过程中,一般使用用户名、商品、喜好程度来度量,通过显式反馈对商品直接评分;隐式反馈是指从用户行为中收集到的数据,例如用户观看视频的时长,侧面反馈。通过优化矩阵分块技术,保持访存和计算的连续性,有效提升Cache命中率,降低时延。通过实际测试,ALS、SimRank等算法在同等精度下,性能提升50%以上。
算法原理
编程实例
本示例以PrefixSpan算法来介绍编程示例。
PrefixSpan为MLlib API
|
模型接口类别 |
函数接口 |
|---|---|
|
MLlib API |
def run[Item, Itemset <: Iterable[Item], Sequence <: Iterable[Itemset]](data: JavaRDD[Sequence]): PrefixSpanModel[Item] def run[Item](data: RDD[Array[Array[Item]]])(implicit arg0: ClassTag[Item]): PrefixSpanModel[Item] |
PrefixSpan算法时序图如图1所示。
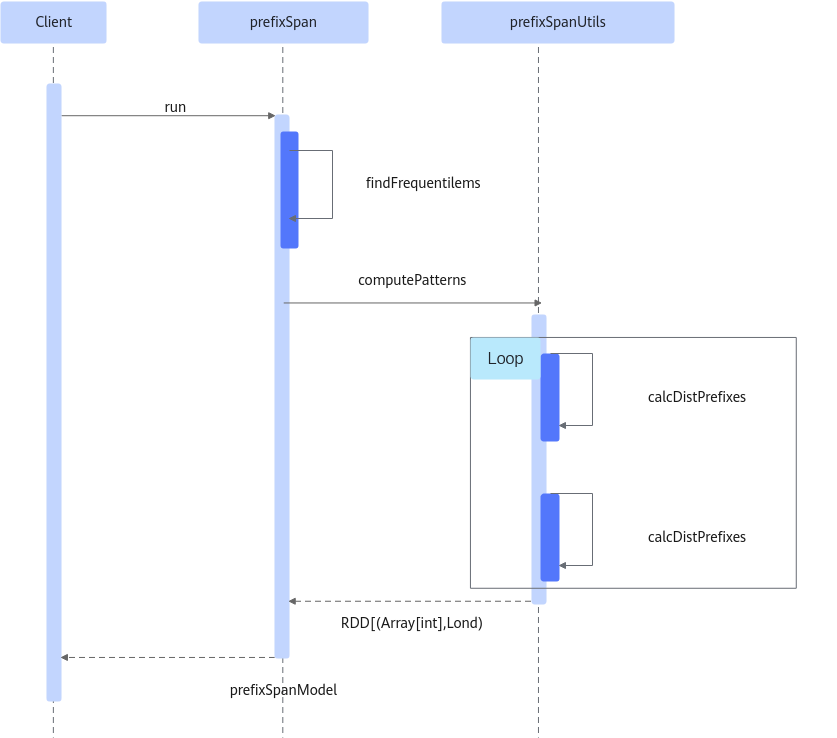
- 输入输出
- 包名:package org.apache.spark.mllib.fpm
- 类名:PrefixSpan
- 方法名:run
- 输入:JavaRDD[Sequence] / RDD[Array[Array[Item]]],全量的序列数据
- 基于原生算法优化的参数
MaxLocalProjDBSize //Prefix本地求解所允许的最大投影数据量 MaxPatternLength //频繁序列模式的最大长度 MinSupport //频繁序列模式的最小支持度
- 新增算法参数
参数名称
spark conf参数名
参数含义
取值类型
localTimeout
spark.boostkit.ml.ps.localTimeout
本地求解的超时时间,单位是秒。
Int,缺省值为300,必须大于等于0。
filterCandidates
spark.boostkit.ml.ps.filterCandidates
是否过滤prefix候选集。
Boolean,缺省值为false。
projDBStep
spark.boostkit.ml.ps.projDBStep
进阶参数,通常保持缺省值即可;投影数据量的调整步调。
Double,缺省值为10。

参数及run代码接口示例:
1 2 3 4 5
val prefixSpan = new PrefixSpan() .setMinSupport(params.minSupport) .setMaxPatternLength(params.maxPatternLength) .setMaxLocalProjDBSize(params.maxLocalProjDBSize) val model = prefixSpan.run(sequences)
- 输出:PrefixSpanModel[Item],频繁序列模型
- 使用样例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
import org.apache.spark.mllib.fpm.PrefixSpan val sequences = sc.parallelize(Seq( Array(Array(1, 2), Array(3)), Array(Array(1), Array(3, 2), Array(1, 2)), Array(Array(1, 2), Array(5)), Array(Array(6)) ), 2).cache() val prefixSpan = new PrefixSpan() .setMinSupport(0.5) .setMaxPatternLength(5) val model = prefixSpan.run(sequences) model.freqSequences.collect().foreach { freqSequence => println( s"${freqSequence.sequence.map(_.mkString("[", ", ", "]")).mkString("[", ", ", "]")}," + s" ${freqSequence.freq}") }
- 结果样例
1 2 3 4 5
[[2]], 3 [[3]], 2 [[1]], 3 [[2, 1]], 3 [[1], [3]], 2