使用OmniCache物化视图推荐视图
本次任务示例使用TPC-DS的数据表作为测试表。
- 生成测试数据。
- 使用hive-testbench工具生成tpcds-8T数据。该工具是hortonworks开源的Hive测试工具。下载网址:https://github.com/hortonworks/hive-testbench,或者使用如下命令下载。
wget https://github.com/hortonworks/hive-testbench/archive/hdp3.zip --no-check-certificate
- 安装Maven。下载并安装到指定目录(此处以指定“/opt/tools/installed/”目录为例)。
wget https://archive.apache.org/dist/maven/maven-3/3.5.4/binaries/apache-maven-3.5.4-bin.tar.gz tar -zxf apache-maven-3.5.4-bin.tar.gz mv apache-maven-3.5.4 /opt/tools/installed/
- 修改Maven环境变量。
- 打开“/etc/profile”文件。
vim /etc/profile
- 按“i”进入编辑模式,在文件末尾增加下面代码。
export MAVEN_HOME=/opt/tools/installed/apache-maven-3.5.4 export PATH=$MAVEN_HOME/bin:$PATH
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 使环境变量生效。
source /etc/profile
- 打开“/etc/profile”文件。
- 检查Maven是否安装成功。
mvn -v
- 使用hive-testbench工具生成tpcds-8T数据。该工具是hortonworks开源的Hive测试工具。下载网址:https://github.com/hortonworks/hive-testbench,或者使用如下命令下载。
- TPC-DS编译。
- 进入“tpcds-gen”目录。
cd tpcds-gen
- 打开pom文件。
vim pom.xml
- 按“i”进入编辑模式,将<dependencies>标签内的Hadoop版本修改成环境的版本进行编译。例如:本文档使用的是Hadoop版本为3.1.1(开源自带的版本为2.2.0)。
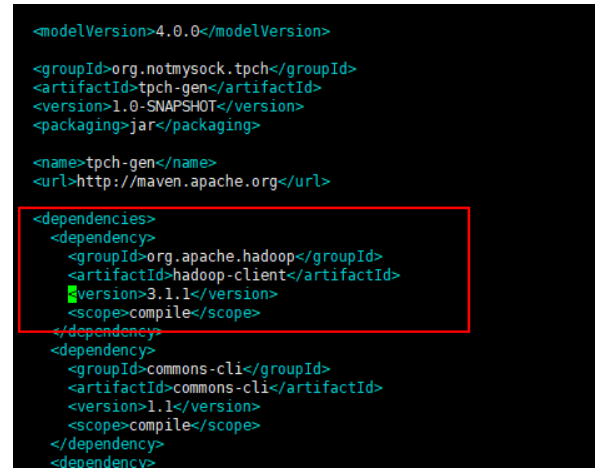

在进行编译前需要保证自己的环境是联网的,能下载各种包,也可以先在联网环境编译成功后,放到非联网环境。
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 编译TPC-DS。如果安装的时候,证书引起报错,请参见编译TPC-DS时证书引起报错解决。
cd /opt/hive-testbench-hdp3/ sh tpcds-build.sh
- 进入“tpcds-gen”目录。
- TPC-DS脚本修改。
由于该脚本是针对HDP3版本的,所以当用户使用的是Apache的版本时,需要对tpcds-setup.sh做如下修改。
- 修改Beeline命令。
- 打开“/opt/hive-testbench-hdp3/tpcds-setup.sh”脚本。
vim /opt/hive-testbench-hdp3/tpcds-setup.sh
- 按“i”进入编辑模式,脚本指定了HIVE的命令为Beeline,这里需要根据自己的环境修改,为了测试方便,此处修改为HIVE="hive "。

- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 打开“/opt/hive-testbench-hdp3/tpcds-setup.sh”脚本。
- 注释hive.optimize.sort.dynamic.partition.threshold参数。
- 打开/opt/hive-testbench-hdp3/settings/load-partitioned.sql文件。
vim /opt/hive-testbench-hdp3/settings/load-partitioned.sql
- 按“i”进入编辑模式,“#”注释最后一行。
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 打开/opt/hive-testbench-hdp3/settings/load-partitioned.sql文件。
- 注释set hive.optimize.sort.dynamic.partition.threshold=0;参数。
- 打开/opt/hive-testbench-hdp3/settings/load-flat.sql文件。
vim /opt/hive-testbench-hdp3/settings/load-flat.sql
- 按“i”进入编辑模式,“#”注释最后一行。
注释后如下所示:
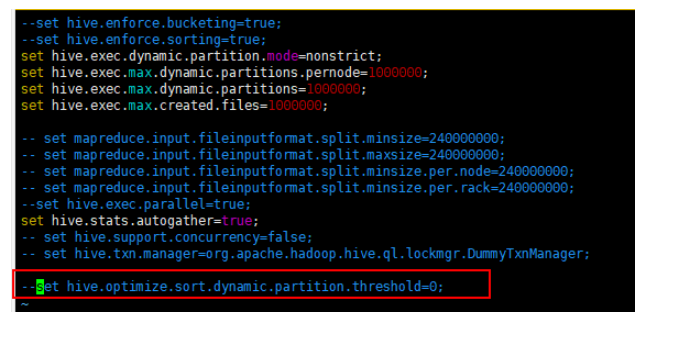
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 打开/opt/hive-testbench-hdp3/settings/load-flat.sql文件。
- 修改Beeline命令。
- TPC-DS数据生成。
测试生成8TB数据(一般进行Hive性能测试时可以选8000GB的数据量)。
sh tpcds-setup.sh 8000
- 修改配置文件。
- 打开文件。
vim config/omnicache_config.cfg
- 按“i”进入编辑模式,修改如下参数。
# 数据库名称 database = tpcds_bin_partitioned_decimal_orc_8000 # 日志解析的JAR包路径 logparser_jar_path = /opt/omnicache/boostkit-omnicache-logparser-spark-3.1.1-1.0.0-aarch64.jar # OmniCache Plugin的路径 cache_plugin_jar_path = /opt/omnicache/boostkit-omnicache-spark-3.1.1-1.0.0-aarch64.jar # spark-defaults.conf路径下面配置的spark history输出的路径 hdfs_input_path = hdfs://server1:9000/spark2-history # SQL语句的存放路径,这里以tpcds sql为例 sqls_path = hdfs://server1:9000/omnicache_0919/tpcds
表1 OmniCache物化视图部分配置 配置项
含义
参考值
database
用于测试的数据库名称
-
logparser_jar_path
日志解析JAR包路径
/opt/omnicache/boostkit-omnicache-logparser-spark-3.1.1-1.0.0-aarch64.jar
cache_plugin_jar_path
OmniCache物化视图的JAR包路径
/opt/omnicache/boostkit-omnicache-spark-3.1.1-1.0.0-aarch64.jar
hdfs_input_path
Spark任务运行日志在HDFS上的访问地址
hdfs://server1:9000/spark2-history
sqls_path
测试SQL在HDFS上的访问地址
hdfs://server1:9000/omnicache_0919/tpcds
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 打开文件。
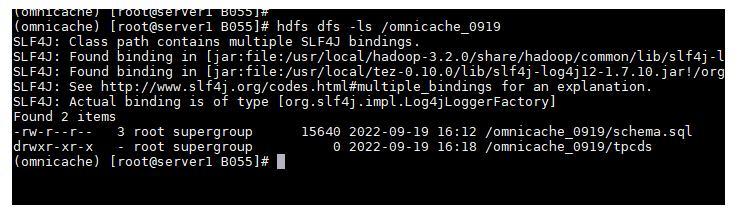
- 获取测试SQL(以tpcds为例)。
- 初始化数据库。这一步主要是获取目标表的建表信息,用于后续创建推荐视图。
屏幕打印“init_database succeed!”说明执行成功。
python3 main.pyc init_database
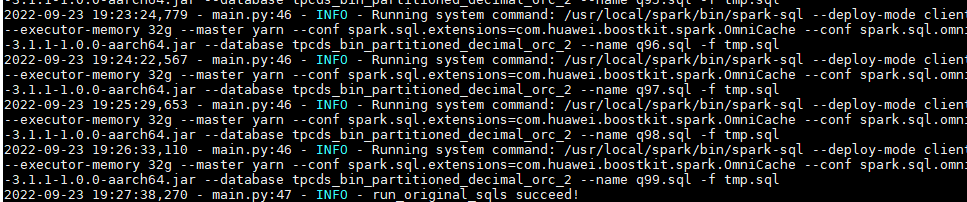
- 运行测试SQL(以TPC-DS测试SQL为例)。
屏幕打印“run_original_sqls succeed!”说明执行成功。
python3 main.pyc run_original_sqls
- 解析运行日志。
- 通过http://ip:18080地址访问Spark History Server查看原生SQL任务起止时间。
- 打开配置文件“config/omnicache_config.cfg”。
vim config/omnicache_config.cfg
- 按“i”进入编辑模式,修改如下参数。
# 测试sql运行开始时间 q_log_start_time = 2022-09-15 11:58 # 测试sql运行结束时间 q_log_end_time = 2022-09-15 17:15
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 运行日志解析脚本。
屏幕打印“parse_query_logs succeed!”说明执行成功。
python3 main.pyc parse_query_logs

- 生成候选视图。
- 可选:修改配置文件“config/omnicache_config.cfg”。
- 可选:打开文件。
vim config/omnicache_config.cfg
- 按“i”进入编辑模式,在文件中修改以下内容。
# 候选TOP mv的数量限制,实际推荐数量小于等于该值 cnt_limit = 40
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 可选:打开文件。
- 运行脚本。

- 可选:修改配置文件“config/omnicache_config.cfg”。
- 运行创建topN视图(需要人为确认,是否可以真实的创建这个候选的视图)。
屏幕打印“create_top_views succeed!”说明执行成功。
python3 main.pyc create_top_views

- 运行物化视图重写任务。
屏幕打印“run_rewrite_sqls succeed!”说明执行成功。
python3 main.pyc run_rewrite_sqls

- 解析重写任务日志。
- 通过http://ip:18080地址访问Spark History Server查看重写任务起止时间。
- 修改配置文件“config/omnicache_config.cfg”。
- 打开文件。
vim config/omnicache_config.cfg
- 按“i”进入编辑模式,在文件中修改以下内容。
# 重写任务开始时间 q_mv_log_start_time = 2022-09-15 20:18 # 重写任务结束时间 q_mv_log_end_time = 2022-09-15 21:17
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 打开文件。
- 运行脚本。
屏幕打印“parse_query_mv_logs succeed!”说明执行成功。
python3 main.pyc parse_query_mv_logs

- 训练代价评估模型。
屏幕打印“train_cost_estimation_model succeed!”说明执行成功。
python3 main.pyc cost_estimation

- 训练推荐模型。
屏幕打印“train_recommend_model succeed!”说明执行成功。
python3 main.pyc recommend

- 获取推荐的物化视图。屏幕打印“get_recommend_mvs succeed!”说明执行成功。
python3 main.pyc get_recommend_mvs
- 创建推荐的物化视图(需要人为确认,是否可以真实的创建这个推荐的视图)。屏幕打印“create_recommend_views succeed!”说明执行成功。
python3 main.pyc create_recommend_views