部署Spark引擎
规划集群环境
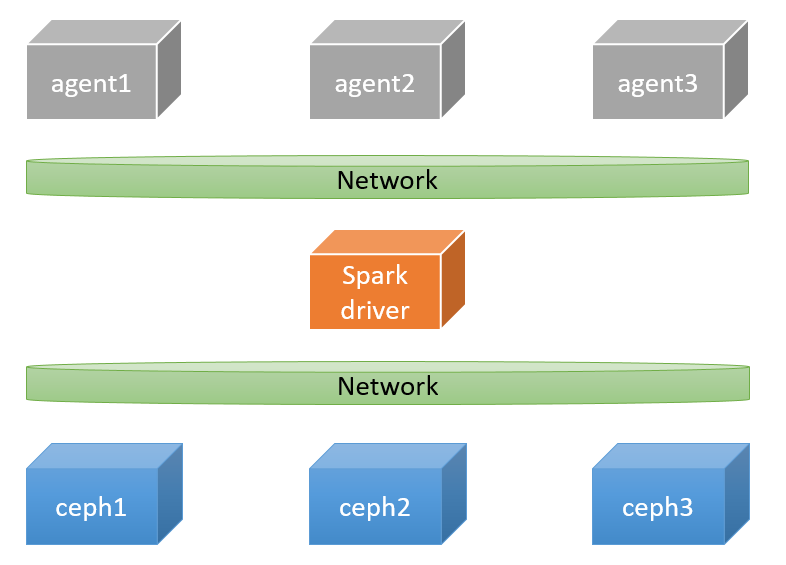
本章节规划的环境有七台服务器组成,分别是任务提交节点(1台),计算节点(3台),存储节点(3台)。其中Spark driver作为大数据集群的任务提交节点,计算节点分别是大数据集群的agent1、agent2和agent3。存储节点分别是大数据集群的ceph1、ceph2、ceph3。如图1所示。
集群所使用的硬件环境如表1所示。
项目 |
型号 |
|---|---|
服务器名称 |
TaiShan服务器 |
处理器 |
鲲鹏920 5220处理器 |
内存大小 |
384GB (12 * 32GB) |
内存频率 |
2666MHz |
网卡 |
业务网络25GE,管理网络GE |
硬盘 |
系统盘:1*RAID 0(1*1.2T SAS HDD) 管理节点:12*RAID 0(1*4T SATA HDD) 业务节点:12*RAID 0(1*4T SATA HDD) 1*3.2T NVMe |
RAID卡 |
LSI SAS3508 |
使用到的相关软件版本如表2所示。
安装Spark引擎
安装过程选择“/usr/local/spark-plugin-jar”作为软件安装的目录,将Spark编译依赖的Jar都放在该目录下,如表3所示。
安装节点 |
安装目录 |
安装组件 |
获取方式 |
|---|---|---|---|
服务端(server1) |
/usr/local/spark-plugin-jar |
slice-0.38.jar |
鲲鹏社区下载 |
boostkit-omnidata-server-1.2.0-aarch64.jar |
华为Support官网下载 |
||
boostkit-omnidata-spark-sql_2.12-3.0.0-1.2.0.jar |
鲲鹏社区下载或者使用源码进行编译 |
||
commons-lang3-3.10.jar |
鲲鹏社区下载 |
||
curator-client-2.12.0.jar |
鲲鹏社区下载 |
||
curator-framework-2.12.0.jar |
鲲鹏社区下载 |
||
curator-recipes-2.12.0.jar |
鲲鹏社区下载 |
||
guava-26.0-jre.jar |
鲲鹏社区下载 |
||
hadoop-aws-3.2.0.jar |
鲲鹏社区下载 |
||
hetu-transport-1.4.1.jar |
鲲鹏社区下载 |
||
hdfs-ceph-3.2.0.jar |
鲲鹏社区下载 |
||
jackson-datatype-guava-2.12.4.jar |
鲲鹏社区下载 |
||
jackson-datatype-jdk8-2.12.4.jar |
鲲鹏社区下载 |
||
jackson-datatype-joda-2.12.4.jar |
鲲鹏社区下载 |
||
jackson-datatype-jsr310-2.12.4.jar |
鲲鹏社区下载 |
||
jackson-module-parameter-names-2.12.4.jar |
鲲鹏社区下载 |
||
jasypt-1.9.3.jar |
鲲鹏社区下载 |
||
haf-jni-call-1.0.1.jar |
华为Support官网下载 |
||
jol-core-0.2.jar |
鲲鹏社区下载 |
||
joni-2.1.5.3.jar |
鲲鹏社区下载 |
||
log-0.193.jar |
鲲鹏社区下载 |
||
perfmark-api-0.23.0.jar |
鲲鹏社区下载 |
||
presto-main-1.4.1.jar |
鲲鹏社区下载 |
||
presto-spi-1.4.1.jar |
鲲鹏社区下载 |
||
protobuf-java-3.12.0.jar |
鲲鹏社区下载 |
- 创建“/usr/local/spark-plugin-jar”目录。
1mkdir -p /usr/local/spark-plugin-jar
- 在任务提交节点(spark driver)上,将在软件获取中得到boostkit-omnidata-server-1.2.0-aarch64.jar(BoostKit-omnidata_1.2.0.zip\BoostKit-omnidata_1.2.0.tar.gz\boostkit-omnidata-server-1.2.0-aarch64.tar.gz\omnidata\lib中),上传到“/usr/local/spark-plugin-jar”目录。
1cp boostkit-omnidata-server-1.2.0-aarch64.jar /usr/local/spark-plugin-jar
- 将在软件获取中得到的haf-jni-call-1.0.1.jar(BoostKit-haf_1.0.1.zip\haf-1.0.1.tar.gz\haf-host-1.0.1.tar.gz\lib\jar中),上传到“/usr/local/spark-plugin-jar”目录。
1cp haf-jni-call-1.0.1.jar /usr/local/spark-plugin-jar
- 将在软件获取中得到的hdfs-ceph-3.2.0.jar,上传到“/usr/local/spark-plugin-jar”目录。
1cp hdfs-ceph-3.2.0.jar /usr/local/spark-plugin-jar
- 使用FTP工具将boostkit-omnidata-spark-sql_2.12-3.0.0-1.2.0-aarch64.zip压缩包上传到安装环境并解压。
1unzip boostkit-omnidata-spark-sql_2.12-3.0.0-1.2.0-aarch64.zip - 将boostkit-omnidata-spark-sql_2.12-3.0.0-1.1.0-aarch64.zip压缩包内的jar包拷贝到“/usr/local/spark-plugin-jar”目录。
1 2
cd boostkit-omnidata-spark-sql_2.12-3.0.0-1.2.0-aarch64 cp *.jar /usr/local/spark-plugin-jar
- 新增算子下推的参数到Spark的配置文件($SPARK_HOME/conf/spark-defaults.conf)中。
以下过程中$SPARK_HOME用/usr/local/spark替代。
- 编辑Spark配置文件。
1vim /usr/local/spark/conf/spark-defaults.conf - 将下面参数配置添加到spark-defaults.conf中。
spark.sql.cbo.enabled true spark.sql.cbo.planStats.enabled true spark.sql.ndp.enabled true spark.sql.ndp.filter.selectivity.enable true spark.sql.ndp.filter.selectivity 0.5 spark.sql.ndp.alive.omnidata 3 spark.sql.ndp.table.size.threshold 10 spark.sql.ndp.zookeeper.address agent1:2181,agent2:2181,agent3:2181 spark.sql.ndp.zookeeper.path /sdi/status spark.sql.ndp.zookeeper.timeout 15000 spark.driver.extraLibraryPath /opt/haf-install/haf-host/lib spark.executor.extraLibraryPath /opt/haf-install/haf-host/lib spark.executorEnv.HAF_CONFIG_PATH /opt/haf-install/haf-host/
以上的参数也可以通过set命令直接在spark-sql设置。
新增算子下推的参数信息如表4所示。
表4 算子下推的参数含义 参数
推荐值
含义
spark.sql.cbo.enabled
true
是否开启cbo优化,设置为true时,启用cbo以估计执行计划来统计信息。
spark.sql.cbo.planStats.enabled
true
设置为true时,逻辑计划将从目录中获取行和列的统计信息。
spark.sql.ndp.enabled
true
是否开启算子下推。
spark.sql.ndp.filter.selectivity.enable
true
是否开启filter选择率来判断是否下推。
spark.sql.ndp.filter.selectivity
0.5
filter选择率小于该值才会下推(selectivity越小,表示需要过滤的数据量越小),默认值为0.5,类型为double。
需要开启spark.sql.ndp.filter.selectivity.enable=true。
如果需要强制下推,可以将参数设置为1.0。
spark.sql.ndp.table.size.threshold
10240
表大于该值才会下推,默认值为10240,单位为字节。
spark.sql.ndp.alive.omnidata
3
集群OmniData算子下推 Server数量
spark.sql.ndp.zookeeper.address
agent1:2181,agent2:2181,agent3:2181
连接ZooKeeper地址。
spark.sql.ndp.zookeeper.path
/sdi/status
ZooKeeper存放下推资源信息的目录。
spark.sql.ndp.zookeeper.timeout
15000
ZooKeeper超时时间,单位为ms。
spark.driver.extraLibraryPath
/opt/haf-install/haf-host/lib
Spark运行时driver依赖的库文件路径。
spark.executor.extraLibraryPath
/opt/haf-install/haf-host/lib
Spark执行executor依赖的库文件路径。
spark.executorEnv.HAF_CONFIG_PATH
/opt/haf-install/haf-host/
使能HAF时的配置文件路径。
- 编辑Spark配置文件。

HAF在主机节点的日志目录:“/var/log/haf-host/haf-user”。