OmniData算子下推叠加OmniOperator算子加速在Spark引擎上的应用
通过OmniData算子下推特性优化数据加载流程,同时使用OmniOperator算子加速特性提升算子执行效率,从而提升端到端引擎查询性能。
安装OmniData算子下推叠加OmniOperator算子加速特性
进行OmniData算子下推叠加OmniOperator算子加速特性的安装之前,需完成OmniData算子下推和OmniOperator算子加速两个特性在Spark上的安装。
- 在管理节点(server1)下创建目录“/opt/omni-operator-omnidata”,并将“/opt/omni-operator”中的全部文件拷贝至所建目录下。
1 2
mkdir -p /opt/omni-operator-omnidata cp -r /opt/omni-operator/* /opt/omni-operator-omnidata/
- 将OmniData算子下推插件包拷贝至“/opt/omni-operator-omnidata/lib”目录下。
1cp -r /opt/boostkit/* /opt/omni-operator-omnidata/lib
- 配置“omni.conf”文件。
- 打开文件。
1vi /opt/omni-operator-omnidata/conf/omni.conf - 按“i”进入编辑模式,添加或修改参数。
1 2 3 4 5 6 7 8 9 10 11
enableHMPP=true enableBatchExprEvaluate=false hiveUdfPropertyFilePath=/opt/omni-operator-omnidata/hive-udf/udf.properties hiveUdfDir=/opt/omni-operator-omnidata/hive-udf/udf RoundingRule=DOWN CheckReScaleRule=CHECK_RESCALE EmptySearchStrReplaceRule=NOT_REPLACE CastDecimalToDoubleRule=CONVERT_WITH_STRING NegativeStartIndexOutOfBoundsRule=INTERCEPT_FROM_BEYOND SupportContainerVecRule=NOT_SUPPORT StringToDateFormatRule=ALLOW_REDUCED_PRECISION
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 打开文件。
- 将“/opt/omni-operator-omnidata”目录拷贝到计算节点(agent1、agent2、agent3),将“hostname”替换为相应节点的主机名。
scp -r /opt/omni-operator-omnidata hostname:/opt/
- 新增OmniData算子下推叠加OmniOperator算子加速特性的参数到Spark的配置文件($SPARK_HOME/conf/spark-defaults.conf)中。
- 编辑Spark配置文件。
1vi /usr/local/spark/conf/spark-defaults.conf - 按“i”进入编辑模式,将以下参数配置添加到spark-defaults.conf中。
1spark.sql.ndp.operator.combine.enable true - 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 编辑Spark配置文件。
执行Spark引擎业务
Spark算子下推使用spark-sql命令来执行。
本次任务示例使用TPC-H的1T数据的非分区表作为测试表,测试SQL为tpch-sql6。
相关的表信息如表1所示。

由于Spark 3.1.1 Yarn模式下不打印INFO级别的日志信息,所以Spark 3.1.1需要做日志重定向。
- 定义日志文件log4j.properties。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
log4j.rootCategory=INFO, FILE log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n log4j.logger.org.apache.spark.sql.execution=DEBUG log4j.logger.org.apache.spark.repl.Main=INFO log4j.appender.FILE=org.apache.log4j.FileAppender log4j.appender.FILE.file=/usr/local/spark/logs/file.log log4j.appender.FILE.layout=org.apache.log4j.PatternLayout log4j.appender.FILE.layout.ConversionPattern=%m%n
- 修改log4j.properties中的log4j.appender.FILE.file为自定义的目录和文件名。
- 启动Spark-SQL命令行窗口。
OmniData叠加OmniOperator特性启动命令如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
/usr/local/spark/bin/spark-sql \ --driver-cores 5 \ --driver-memory 5g \ --num-executors 18 \ --executor-cores 21 \ --executor-memory 10g \ --master yarn \ --conf spark.executor.memoryOverhead=5g \ --conf spark.memory.offHeap.enabled=true \ --conf spark.memory.offHeap.size=45g \ --conf spark.task.cpus=1 \ --conf spark.sql.codegen.wholeStage=true \ --conf spark.sql.orc.impl=native \ --conf spark.sql.extensions=com.huawei.boostkit.spark.ColumnarPlugin \ --conf spark.shuffle.manager=org.apache.spark.shuffle.sort.OmniColumnarShuffleManager \ --conf spark.sql.join.columnar.preferShuffledHashJoin=true \ --conf spark.executor.extraClassPath=/opt/omni-operator-omnidata/lib/* \ --conf spark.driver.extraClassPath=/opt/omni-operator-omnidata/lib/* \ --conf spark.executorEnv.LD_LIBRARY_PATH=/opt/omni-operator-omnidata/lib/:/usr/local/lib/HMPP:/home/omm/omnidata-install/haf-host/lib \ --conf spark.driverEnv.LD_LIBRARY_PATH=/opt/omni-operator-omnidata/lib/:/usr/local/lib/HMPP:/home/omm/omnidata-install/haf-host/lib \ --conf spark.executor.extraLibraryPath=/opt/omni-operator-omnidata/lib:/home/omm/omnidata-install/haf-host/lib \ --conf spark.driverEnv.extraLibraryPath=/opt/omni-operator-omnidata/lib:/home/omm/omnidata-install/haf-host/lib \ --conf spark.executorEnv.LD_PRELOAD=/opt/omni-operator-omnidata/lib/libjemalloc.so.2 \ --conf spark.driverEnv.LD_PRELOAD=/opt/omni-operator-omnidata/lib/libjemalloc.so.2 \ --driver-java-options -Djava.library.path=/opt/omni-operator-omnidata/lib \ --jars /opt/omni-operator-omnidata/lib/boostkit-omniop-spark-3.1.1-1.3.0-aarch64.jar \ --jars /opt/omni-operator-omnidata/lib/boostkit-omniop-bindings-1.3.0-aarch64.jar \ --conf spark.executorEnv.OMNI_CONNECTED_ENGINE=Spark \ --conf spark.executorEnv.HAF_CONFIG_PATH=/home/omm/omnidata-install/haf-host/etc/ \ --conf spark.omni.sql.columnar.fusion=false \ --conf spark.omni.sql.columnar.sortSpill.enabled=true \ --conf spark.omni.sql.columnar.sortSpill.rowThreshold=400000 \ --conf spark.omni.sql.columnar.sortSpill.dirDiskReserveSize=214748364800 \ --driver-java-options -Dlog4j.configuration=file:/usr/local/spark/conf/log4j.properties
SparkExtension相关的启动参数信息如表2所示。
表2 SparkExtension相关启动参数信息 启动参数名称
缺省值
含义
spark.sql.extensions
com.huawei.boostkit.spark.ColumnarPlugin
启用SparkExtension。
spark.shuffle.manager
sort
是否启用列式Shuffle,若启用则需添加配置项--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.OmniColumnarShuffleManager。OmniShuffle Shuffle加速启用请配置OmniShuffle Shuffle加速自有的shuffleManager类。默认sort走原生的Shuffle。
spark.omni.sql.columnar.hashagg
true
是否启用列式HashAgg,true表示启用,false表示关闭。
spark.omni.sql.columnar.project
true
是否启用列式Project,true表示启用,false表示关闭。
spark.omni.sql.columnar.projfilter
true
是否启用列式ConditionProject(Project + Filter融合算子),true表示启用,false表示关闭。
spark.omni.sql.columnar.filter
true
是否启用列式Filter,true表示启用,false表示关闭。
spark.omni.sql.columnar.sort
true
是否启用列式Sort,true表示启用,false表示关闭。
spark.omni.sql.columnar.window
true
是否启用列式Window,true表示启用,false表示关闭。
spark.omni.sql.columnar.broadcastJoin
true
是否启用列式BroadcastHashJoin,true表示启用,false表示关闭。
spark.omni.sql.columnar.nativefilescan
true
是否启用列式NativeFilescan,true表示启用,false表示关闭。
spark.omni.sql.columnar.orcNativefilescan
true
是否启用ORC列式NativeFilescan,true表示启用,false表示关闭。
spark.omni.sql.columnar.sortMergeJoin
true
是否启用列式SortMergeJoin,true表示启用,false表示关闭。
spark.omni.sql.columnar.takeOrderedAndProject
true
是否启用列式TakeOrderedAndProject,true表示启用,false表示关闭。
spark.omni.sql.columnar.shuffledHashJoin
true
是否启用列式ShuffledHashJoin,true表示启用,false表示关闭。
spark.shuffle.columnar.shuffleSpillBatchRowNum
10000
Shuffle输出的每个Batch中包含数据的行数。请根据实际环境的内存调整参数,可以适当增大此参数,从而减少写入磁盘文件的批次,提升写入速度。
spark.shuffle.columnar.shuffleSpillMemoryThreshold
2147483648
Shuffle内存溢写上限,Shuffle内存上限达到缺省值时会发生溢写,单位:Byte。请根据实际环境的内存调整参数,可以适当增大此参数,从而减少Shuffle内存溢写到磁盘文件次数,减少磁盘IO操作。
spark.shuffle.columnar.compressBlockSize
65536
Shuffle数据压缩块大小,单位:Byte。请根据实际环境的内存调整参数,建议采用缺省值。
spark.sql.execution.columnar.maxRecordsPerBatch
4096
列式Shuffle初始化Buffer大小,单位:Byte。请根据实际环境的内存调整参数,可以适当增大此参数,从而减少Shuffle读写次数,提升性能。
spark.sql.join.columnar.preferShuffledHashJoin
false
Join发生时,是否优先使用ShuffledHashJoin,true表示启用,false表示关闭。
spark.shuffle.compress
true
Shuffle是否开启压缩。true表示压缩,false表示不压缩。
spark.io.compression.codec
lz4
Shuffle压缩格式。支持uncompressed、zlib、snappy、lz4和zstd格式。
spark.omni.sql.columnar.sortSpill.rowThreshold
214783647
sort算子溢写触发条件,处理数据行超过此值触发溢写,单位:行。请根据实际环境的内存调整参数,可以适当增大此参数,从而减少sort算子溢写到磁盘文件的次数,减少磁盘IO操作。
spark.omni.sql.columnar.sortSpill.dirDiskReserveSize
10737418240
sort溢写磁盘预留可用空间大小,如果实际小于此值会抛异常,单位:Byte。根据实际环境的磁盘容量和业务场景调整参数,建议不超过业务数据大小,取值上限为实际环境的磁盘容量大小。
spark.omni.sql.columnar.sortSpill.enabled
false
sort算子是否开启溢写能力。true表示开启溢写能力,false表示关闭。
- 执行sql6语句。
1 2 3 4 5 6 7 8 9
select sum(l_extendedprice * l_discount) as revenue from tpch_flat_orc_1000.lineitem where l_shipdate >= '1993-01-01' and l_shipdate < '1994-01-01' and l_discount between 0.06 - 0.01 and 0.06 + 0.01 and l_quantity < 25;
待任务执行完毕,查看log4j.properties中所配置的日志文件,若日志中包含下推信息,则OmniData算子下推生效。
1 2
Selectivity: 0.014160436451808448 Push down with [PushDownInfo(ListBuffer(FilterExeInfo((((((((isnotnull(l_shipdate#11) AND isnotnull(l_discount#7)) AND isnotnull(l_quantity#5)) AND (l_shipdate#11 >= 8401)) AND (l_shipdate#11 < 8766)) AND (l_discount#7 >= 0.05)) AND (l_discount#7 <= 0.07)) AND (l_quantity#5 < 25.0)),List(l_quantity#5, l_extendedprice#6, l_discount#7, l_shipdate#11))),ListBuffer(AggExeInfo(List(sum((l_extendedprice#6 * l_discount#7))),List(),List(sum#36))),None,Map(server1 -> server1, agent2 -> agent2, agent1 -> agent1))]

执行explain语句,若显示的执行计划中存在OmniOperator算子加速相关的算子,则OmniOperator算子加速生效。
1 2 3 4 5 6 7 8 9
explain select sum(l_extendedprice * l_discount) as revenue from tpch_flat_orc_1000.lineitem where l_shipdate >= '1993-01-01' and l_shipdate < '1994-01-01' and l_discount between 0.06 - 0.01 and 0.06 + 0.01 and l_quantity < 25;
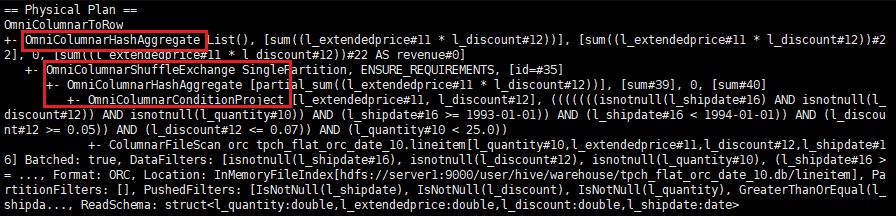
若两特性均生效,可证明OmniData算子下推叠加OmniOperator算子加速特性生效。