OmniAdvisor参数调优特性
介绍OmniAdvisor参数调优特性架构。
OmniAdvisor参数调优特性首先对历史的Spark、Hive SQL任务进行参数解析,然后利用AI算法智能化的对任务进行参数采样调优,最终对该任务实现端到端在线参数调优。
OmniAdvisor参数调优特性可以对在线系统进行端到端调优。其主要分为四大模块:
- SQL日志解析模块:用于解析Spark/Hive日志,获取SQL参数信息。
- SQL参数采样调优模块:用于采样不同配置的SQL参数,并用新采样的参数执行任务。
- SQL参数推荐模块:对于已完成调优的任务,可以在数据库中查找历史任务的最佳参数作为该任务的执行参数。
- SQL异常参数处理模块:采样或者推荐的SQL参数如果在执行中发生异常,则需要进行异常处理。
图1 OmniAdvisor参数调优特性软件架构图
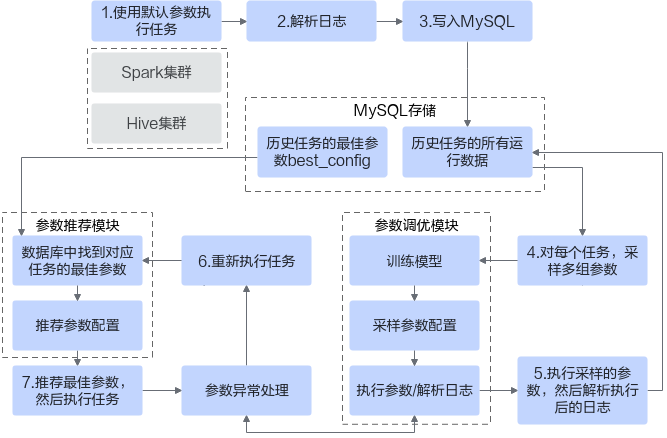
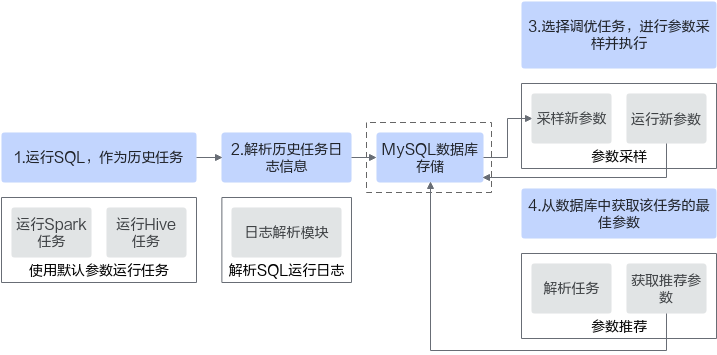
- 首先用户需要使用默认参数执行Spark任务或者Hive Tez任务。
- 执行任务后,集群上会保留任务执行的日志信息(Spark集群需要配置spark.history.fs.logDirectory,Hive TEZ引擎需要启动Timeline server服务),通过日志解析模块来解析任务执行后的日志信息。将分析得到的SQL参数信息、SQL执行状态、执行时间等信息存入到MySQL数据库中。
- 用户选择需要调优的任务列表,对每个调优任务,先从数据库中获取历史参数,然后对这个历史参数进行参数采样,再执行采样后得到的参数,并将执行的结果进行解析,进而更新数据库中的信息。
- 当用户需要重新执行任务的时候,可以在数据库中查找历史任务的最佳参数作为该任务的执行参数。
图2 OmniAdvisor参数调优特性场景分析图
父主题: 关键特性