执行Spark引擎业务
Spark使用交互式页面命令行来执行SQL任务,需要注意的是Spark侧看SparkExtension是否生效需要在SQL语句前加EXPLAIN语句,或者在Spark UI页面查看,如果算子是以Omni开头的则代表SparkExtension生效。
本次任务示例使用tpcds_bin_partitioned_varchar_orc_2的数据表作为测试表,测试SQL为TPC-DS测试集的Q82。
相关的表信息如表1所示。
|
表名 |
表格式 |
总行数 |
|---|---|---|
|
item |
orc |
26000 |
|
inventory |
orc |
16966305 |
|
date_dim |
orc |
73049 |
|
store_sales |
orc |
5760749 |
- 启动Spark-SQL命令行窗口。
- 原生Spark-SQL启动命令如下。
1/usr/local/spark/bin/spark-sql --deploy-mode client --driver-cores 8 --driver-memory 20g --master yarn --executor-cores 8 --executor-memory 26g --num-executors 36 --conf spark.executor.extraJavaOptions='-XX:+UseG1GC -XX:+UseNUMA' --conf spark.locality.wait=0 --conf spark.network.timeout=600 --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.adaptive.enabled=true --conf spark.sql.autoBroadcastJoinThreshold=100M --conf spark.sql.broadcastTimeout=600 --conf spark.sql.shuffle.partitions=1000 --conf spark.sql.orc.impl=native --conf spark.task.cpus=1 --database tpcds_bin_partitioned_varchar_orc_2
- SparkExtension 3.1.1插件启动步骤如下。
- 进入“/usr/local/spark/conf”目录创建spark-defaults-omnioperator.conf文件。
1 2
cd /usr/local/spark/conf cp spark-defaults.conf spark-defaults-omnioperator.conf
- 修改spark-defaults-omnioperator.conf文件权限为555。
1chmod 555 spark-defaults-omnioperator.conf
- 打开“spark-defaults-omnioperator.conf”文件。
1vi spark-defaults-omnioperator.conf - 按“i”进入编辑模式,在文件末尾追加以下参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
spark.sql.optimizer.runtime.bloomFilter.enabled true spark.driverEnv.LD_LIBRARY_PATH /opt/omni-operator/lib spark.driverEnv.LD_PRELOAD /opt/omni-operator/lib/libjemalloc.so.2 spark.driverEnv.OMNI_HOME /opt/omni-operator spark.driver.extraClassPath /opt/omni-operator/lib/boostkit-omniop-spark-3.1.1-1.7.0-aarch64.jar:/opt/omni-operator/lib/boostkit-omniop-bindings-1.7.0-aarch64.jar:/opt/omni-operator/lib/dependencies/protobuf-java-3.15.8.jar:/opt/omni-operator/lib/dependencies/boostkit-omniop-native-reader-3.1.1-1.7.0.jar spark.driver.extraLibraryPath /opt/omni-operator/lib spark.driver.defaultJavaOptions -Djava.library.path=/opt/omni-operator/lib spark.executorEnv.LD_LIBRARY_PATH ${PWD}/omni/omni-operator/lib spark.executorEnv.LD_PRELOAD ${PWD}/omni/omni-operator/lib/libjemalloc.so.2 spark.executorEnv.MALLOC_CONF narenas:2 spark.executorEnv.OMNI_HOME ${PWD}/omni/omni-operator spark.executor.extraClassPath ${PWD}/omni/omni-operator/lib/boostkit-omniop-spark-3.1.1-1.7.0-aarch64.jar:${PWD}/omni/omni-operator/lib/boostkit-omniop-bindings-1.7.0-aarch64.jar:${PWD}/omni/omni-operator/lib/dependencies/protobuf-java-3.15.8.jar:${PWD}/omni/omni-operator/lib/dependencies/boostkit-omniop-native-reader-3.1.1-1.7.0.jar spark.executor.extraLibraryPath ${PWD}/omni/omni-operator/lib spark.omni.sql.columnar.fusion false spark.shuffle.manager org.apache.spark.shuffle.sort.OmniColumnarShuffleManager spark.sql.codegen.wholeStage false spark.sql.extensions com.huawei.boostkit.spark.ColumnarPlugin spark.omni.sql.columnar.RewriteSelfJoinInInPredicate true spark.sql.execution.filterMerge.enabled true spark.omni.sql.columnar.dedupLeftSemiJoin true spark.omni.sql.columnar.radixSort.enabled true spark.executorEnv.MALLOC_CONF tcache:false spark.sql.adaptive.coalescePartitions.minPartitionNum 200 spark.sql.join.columnar.preferShuffledHashJoin true
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 执行启动命令。
1/usr/local/spark/bin/spark-sql --archives hdfs://server1:9000/user/root/omni-operator.tar.gz#omni --deploy-mode client --driver-cores 8 --driver-memory 40g --master yarn --executor-cores 12 --executor-memory 5g --conf spark.memory.offHeap.enabled=true --conf spark.memory.offHeap.size=35g --num-executors 24 --conf spark.executor.extraJavaOptions='-XX:+UseG1GC' --conf spark.locality.wait=0 --conf spark.network.timeout=600 --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.adaptive.enabled=true --conf spark.sql.adaptive.skewedJoin.enabled=true --conf spark.sql.autoBroadcastJoinThreshold=100M --conf spark.sql.broadcastTimeout=600 --conf spark.sql.shuffle.partitions=600 --conf spark.sql.orc.impl=native --conf spark.task.cpus=1 --properties-file /usr/local/spark/conf/spark-defaults-omnioperator.conf --database tpcds_bin_partitioned_varchar_orc_2
- 进入“/usr/local/spark/conf”目录创建spark-defaults-omnioperator.conf文件。
- SparkExtension 3.3.1插件启动步骤如下。
- 在“/usr/local/spark/conf”目录创建spark-defaults-omnioperator.conf文件。
1 2
cd /usr/local/spark/conf cp spark-defaults.conf spark-defaults-omnioperator.conf
- 修改spark-defaults-omnioperator.conf文件权限为555。
1chmod 555 spark-defaults-omnioperator.conf
- 打开“spark-defaults-omnioperator.conf”文件。
1vi spark-defaults-omnioperator.conf - 按“i”进入编辑模式,在文件末尾追加以下参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
spark.sql.optimizer.runtime.bloomFilter.enabled true spark.driverEnv.LD_LIBRARY_PATH /opt/omni-operator/lib spark.driverEnv.LD_PRELOAD /opt/omni-operator/lib/libjemalloc.so.2 spark.driverEnv.OMNI_HOME /opt/omni-operator spark.driver.extraClassPath /opt/omni-operator/lib/boostkit-omniop-spark-3.3.1-1.7.0-aarch64.jar:/opt/omni-operator/lib/boostkit-omniop-bindings-1.7.0-aarch64.jar:/opt/omni-operator/lib/dependencies/protobuf-java-3.15.8.jar:/opt/omni-operator/lib/dependencies/boostkit-omniop-native-reader-3.3.1-1.7.0.jar spark.driver.extraLibraryPath /opt/omni-operator/lib spark.driver.defaultJavaOptions -Djava.library.path=/opt/omni-operator/lib spark.executorEnv.LD_LIBRARY_PATH ${PWD}/omni/omni-operator/lib spark.executorEnv.LD_PRELOAD ${PWD}/omni/omni-operator/lib/libjemalloc.so.2 spark.executorEnv.MALLOC_CONF narenas:2 spark.executorEnv.OMNI_HOME ${PWD}/omni/omni-operator spark.executor.extraClassPath ${PWD}/omni/omni-operator/lib/boostkit-omniop-spark-3.3.1-1.7.0-aarch64.jar:${PWD}/omni/omni-operator/lib/boostkit-omniop-bindings-1.7.0-aarch64.jar:${PWD}/omni/omni-operator/lib/dependencies/protobuf-java-3.15.8.jar:${PWD}/omni/omni-operator/lib/dependencies/boostkit-omniop-native-reader-3.3.1-1.7.0.jar spark.executor.extraLibraryPath ${PWD}/omni/omni-operator/lib spark.omni.sql.columnar.fusion false spark.shuffle.manager org.apache.spark.shuffle.sort.OmniColumnarShuffleManager spark.sql.codegen.wholeStage false spark.sql.extensions com.huawei.boostkit.spark.ColumnarPlugin spark.omni.sql.columnar.RewriteSelfJoinInInPredicate true spark.sql.execution.filterMerge.enabled true spark.omni.sql.columnar.dedupLeftSemiJoin true spark.omni.sql.columnar.radixSort.enabled true spark.executorEnv.MALLOC_CONF tcache:false spark.sql.adaptive.coalescePartitions.minPartitionNum 200 spark.sql.join.columnar.preferShuffledHashJoin true
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 执行启动命令。
1/usr/local/spark/bin/spark-sql --archives hdfs://server1:9000/user/root/omni-operator.tar.gz#omni --deploy-mode client --driver-cores 8 --driver-memory 40g --master yarn --executor-cores 12 --executor-memory 5g --conf spark.memory.offHeap.enabled=true --conf spark.memory.offHeap.size=35g --num-executors 24 --conf spark.executor.extraJavaOptions='-XX:+UseG1GC' --conf spark.locality.wait=0 --conf spark.network.timeout=600 --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.adaptive.enabled=true --conf spark.sql.adaptive.skewedJoin.enabled=true --conf spark.sql.autoBroadcastJoinThreshold=100M --conf spark.sql.broadcastTimeout=600 --conf spark.sql.shuffle.partitions=600 --conf spark.sql.orc.impl=native --conf spark.task.cpus=1 --properties-file /usr/local/spark/conf/spark-defaults-omnioperator.conf --database tpcds_bin_partitioned_varchar_orc_2
- 在“/usr/local/spark/conf”目录创建spark-defaults-omnioperator.conf文件。

- hdfs://server1:9000/user/root/omni-operator.tar.gz#omni:依据用户Hadoop的core-site.xml中配置的fs.defaultFS实际值设置“hdfs://server1:9000”。“/user/root/omni-operator.tar.gz”用户可自行定义,与打包与上传OmniOperator安装包的操作关联。“#omni”表示实际运行时omni-operator.tar.gz解压的目录,用户可自行定义。
- 上述启动命令为Yarn模式使用,若使用local模式启动SparkExtension插件,需将--master yarn改为--master local,同时在启动前需在所有节点的“~/.bashrc”文件中添加export LD_PRELOAD=/opt/omni-operator/lib/libjemalloc.so.2并更新环境变量。启动命令中“${PWD}/omni”全部替换为“/opt”。
SparkExtension相关的启动参数信息如表2所示。
表2 SparkExtension相关启动参数信息 启动参数名称
缺省值
含义
spark.sql.extensions
com.huawei.boostkit.spark.ColumnarPlugin
启用SparkExtension。
spark.shuffle.manager
sort
是否启用列式Shuffle,若启用请配置OmniShuffle Shuffle加速自有的shuffleManager类,需添加配置项--conf spark.shuffle.manager="org.apache.spark.shuffle.sort.OmniColumnarShuffleManager"。默认sort使用原生的Shuffle。
spark.omni.sql.columnar.hashagg
true
是否启用列式HashAgg,true表示启用,false表示关闭。
spark.omni.sql.columnar.project
true
是否启用列式Project,true表示启用,false表示关闭。
spark.omni.sql.columnar.projfilter
true
是否启用列式ConditionProject(Project + Filter融合算子),true表示启用,false表示关闭。
spark.omni.sql.columnar.filter
true
是否启用列式Filter,true表示启用,false表示关闭。
spark.omni.sql.columnar.sort
true
是否启用列式Sort,true表示启用,false表示关闭。
spark.omni.sql.columnar.window
true
是否启用列式Window,true表示启用,false表示关闭。
spark.omni.sql.columnar.broadcastJoin
true
是否启用列式BroadcastHashJoin,true表示启用,false表示关闭。
spark.omni.sql.columnar.nativefilescan
true
是否启用列式NativeFilescan,true表示启用,false表示关闭,包括ORC和Parquet的文件格式。
spark.omni.sql.columnar.sortMergeJoin
true
是否启用列式SortMergeJoin,true表示启用,false表示关闭。
spark.omni.sql.columnar.takeOrderedAndProject
true
是否启用列式TakeOrderedAndProject,true表示启用,false表示关闭。
spark.omni.sql.columnar.shuffledHashJoin
true
是否启用列式ShuffledHashJoin,true表示启用,false表示关闭。
spark.shuffle.columnar.shuffleSpillBatchRowNum
10000
Shuffle输出的每个batch中包含数据的行数。请根据实际环境的内存调整参数,可以适当增大此参数,从而减少写入磁盘文件的批次,提升写入速度。
spark.shuffle.columnar.shuffleSpillMemoryThreshold
2147483648
Shuffle内存溢写上限,Shuffle内存上限达到缺省值时会发生溢写,单位:Byte。请根据实际环境的内存调整参数,可以适当增大此参数,从而减少Shuffle内存溢写到磁盘文件次数,减少磁盘IO操作。
spark.omni.sql.columnar.sortMergeJoin.fusion
false
是否开启sortMergeJoin融合,true表示和sort子节点融合,false表示和sort子节点不融合。
spark.shuffle.columnar.compressBlockSize
65536
Shuffle数据压缩块大小,单位:Byte。请根据实际环境的内存调整参数,建议采用缺省值。
spark.sql.execution.columnar.maxRecordsPerBatch
4096
列式Shuffle初始化Buffer大小,单位:Byte。请根据实际环境的内存调整参数,可以适当增大此参数,从而减少Shuffle读写次数,提升性能。
spark.shuffle.compress
true
Shuffle是否开启压缩。true表示压缩,false表示不压缩。
spark.io.compression.codec
lz4
Shuffle压缩格式。支持uncompressed、zlib、snappy、lz4和zstd格式。
spark.omni.sql.columnar.sortSpill.rowThreshold
214783647
sort算子溢写触发条件,处理数据行超过此值触发溢写,单位:行。请根据实际环境的内存调整参数,可以适当增大此参数,从而减少sort算子溢写到磁盘文件的次数,减少磁盘IO操作。
spark.omni.sql.columnar.sortSpill.memFraction
90
sort算子溢写触发条件,处理数据使用堆外内存超过此百分比触发溢写,与堆外内存总大小参数“spark.memory.offHeap.size”同时使用。请根据实际环境的内存调整参数,可以适当增大此参数,从而减少sort算子溢写到磁盘文件的次数,减少磁盘IO操作。
spark.omni.sql.columnar.broadcastJoin.shareHashtable
true
在Broadcast Join场景下,是否开启builder侧只构建一份hash table,并允许所有lookup join侧共用。true表示开启,false表示关闭。
spark.omni.sql.columnar.sortSpill.dirDiskReserveSize
10737418240
sort溢写磁盘预留可用空间大小,如果实际小于此值会抛异常,单位:Byte。根据实际环境的磁盘容量和业务场景调整参数,建议不超过业务数据大小,取值上限为实际环境的磁盘容量大小。
spark.omni.sql.columnar.sortSpill.enabled
false
sort算子是否开启溢写能力。true表示开启溢写能力,false表示关闭。
spark.omni.sql.columnar.heuristicJoinReorder
true
是否开启join重排序优化策略。默认为true表示开启,false表示关闭。启发式join可以根据where过滤条件的数量和table表的大小,自动优化join的顺序。
spark.default.parallelism
200
Spark并行执行的任务数。
spark.sql.shuffle.partitions
200
Spark执行聚合操作或者Join操作时的Shuffle分区数。
spark.sql.adaptive.enabled
false
是否启用自适应查询执行优化,可以在查询执行过程中动态地调整执行计划,true开启,false关闭。
spark.executorEnv.MALLOC_CONF
narenas:1
控制Spark中每一个Executor进程中的内存分配策略。
spark.sql.autoBroadcastJoinThreshold
10M
控制在执行Join操作时使用boradcastjoin小表的阈值大小。
spark.sql.broadcastTimeout
300
控制广播小表到其它节点的超时时间。
spark.omni.sql.columnar.fusion
false
是否把多个算子融合成一个算子。true表示是,false表示否。
spark.locality.wait
3
数据本地化等待时长。
spark.sql.cbo.enabled
false
是否开启CBO。true表示开启,false表示关闭。
spark.sql.codegen.wholeStage
true
是否开启全阶段代码生成。true表示开启,false表示关闭。
spark.sql.orc.impl
native
native表示使用原生版本的ORC库,hive表示使用Hive中的ORC库。
spark.serializer
空
使用Kryo序列化。
spark.executor.extraJavaOptions
空
Executor使用Hadoop本地库加速路径。
spark.driver.extraJavaOptions
空
Driver使用Hadoop本地库加速路径。
spark.network.timeout
120
所有网络交互的默认超时时间,单位:s。
spark.omni.sql.columnar.RewriteSelfJoinInInPredicate
false
是否启用将in表达式中的self join转换为hashagg,删除没用到的列,减少数据量。true表示开启,false表示关闭。
spark.sql.execution.filterMerge.enabled
false
是否开启将在同一个表上的结构相似的多个表达式合并处理,减少Scan数据量。true表示开启,false表示关闭。
spark.omni.sql.columnar.dedupLeftSemiJoin
false
是否启用对leftsemi join右表去重,减少join数据量。true表示开启,false表示关闭。
spark.omni.sql.columnar.radixSort.enabled
false
是否开启基数排序优化,当单个任务排序行数超过阈值后,调用基数排序,默认值100,0000。true表示开启,false表示关闭。
spark.sql.join.columnar.preferShuffledHashJoin
false
是否开启尽可能使用ShuffledHashJoin。true表示开启,false表示关闭。
spark.sql.adaptive.skewedJoin.enabled
false
是否开启自适应倾斜连接优化。自适应倾斜连接优化会在连接操作中检测到数据倾斜的情况下,自动采用一些特殊的连接算法来处理倾斜数据,从而提高连接操作的效率。true表示开启,false表示关闭。
spark.sql.adaptive.coalescePartitions.minPartitionNum
1
合并后的最小Shuffle分区数。如果不设置,默认为Spark集群的默认并行度。
spark.omni.sql.columnar.bloomfilterSubqueryReuse
false
是否开启重用BloomFilter subquery,在BloomFilter生效的情况下尝试重用数据表,减少一次scan操作。true表示开启,false表示关闭。
spark.omni.sql.columnar.adaptivePartialAggregation.enabled
false
是否开启自适应跳过HashAgg分组聚合操作Partial阶段处理优化。该优化为运行时优化,在满足必要条件:存在分组聚合操作,但不存在First/Last聚合前提下,若采样识别为高基数场景,则跳过分组聚合Partial阶段处理,直接向下游算子输出数据。true表示开启,false表示关闭。
spark.omni.sql.columnar.adaptivePartialAggregationMinRows
500000
adaptivePartialAggregation优化的最小采样行数。采样达到该行数时,开始计算采样数据的聚合情况。
spark.omni.sql.columnar.adaptivePartialAggregationRatio
0.8
adaptivePartialAggregation优化的最小聚合阈值。若采样数据聚合情况达到该阈值,则应用该优化。
spark.omni.sql.columnar.pushOrderedLimitThroughAggEnable.enabled
false
是否开启pushOrderedLimitThroughAgg优化。在执行计划包含Sort+Limit Operator,且排序字段为分组聚合操作中分组字段的子集时,该优化将TopNSort Operator下推到分组聚合partial阶段后,以减少下游算子数据处理量。true表示开启,false表示关闭。
该优化不会和adaptivePartialAggregation优化同时生效。
spark.omni.sql.columnar.combineJoinedAggregates.enabled
false
是否开启combineJoinedAggregates优化。该优化通过合并基于相同数据的子查询减少重复的读表操作。true表示开启,false表示关闭。
spark.omni.sql.columnar.wholeStage.fallback.threshold
-1
在AQE开启的情况下,如果Stage回退的算子个数大于等于这个阈值,则该Stage的全部算子(除OmniColumnarToRow和OmniAQEShuffleReadExec算子)全部回退为原生算子。当设置为-1时,关闭此功能。
spark.omni.sql.columnar.query.fallback.threshold
-1
在AQE关闭的情况下,如果整个执行计划回退的算子个数大于等于这个阈值,则该Stage的全部算子全部回退为原生算子。当设置为-1时,关闭此功能。
spark.omni.sql.columnar.unixTimeFunc.enabled
true
是否启用from_unixtime和unix_timestamp表达式,true表示启用,false表示关闭。
spark.sql.orc.filterPushdown
true
控制ORC文件格式的数据查询时是否启用谓词下推功能。
- 原生Spark-SQL启动命令如下。
- 查看SparkExtension是否生效。
在SparkExtension和原生Spark-SQL交互式命令行窗口分别运行以下SQL语句。
建议同时启动两个命令行界面,并在每个窗口中分别启动SparkExtension和开源版本Spark-SQL,方便对比。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
set spark.sql.adaptive.enabled=false; explain select i_item_id ,i_item_desc ,i_current_price from item, inventory, date_dim, store_sales where i_current_price between 76 and 76+30 and inv_item_sk = i_item_sk and d_date_sk=inv_date_sk and d_date between cast('1998-06-29' as date) and cast('1998-08-29' as date) and i_manufact_id in (512,409,677,16) and inv_quantity_on_hand between 100 and 500 and ss_item_sk = i_item_sk group by i_item_id,i_item_desc,i_current_price order by i_item_id limit 100;
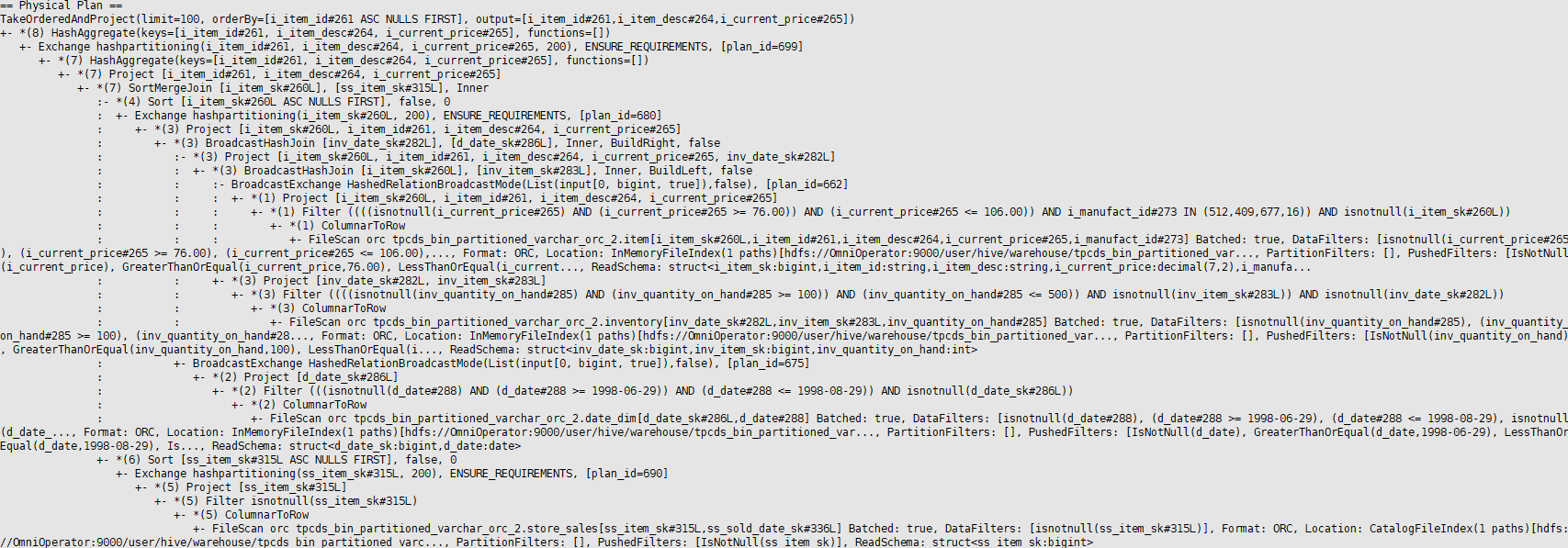
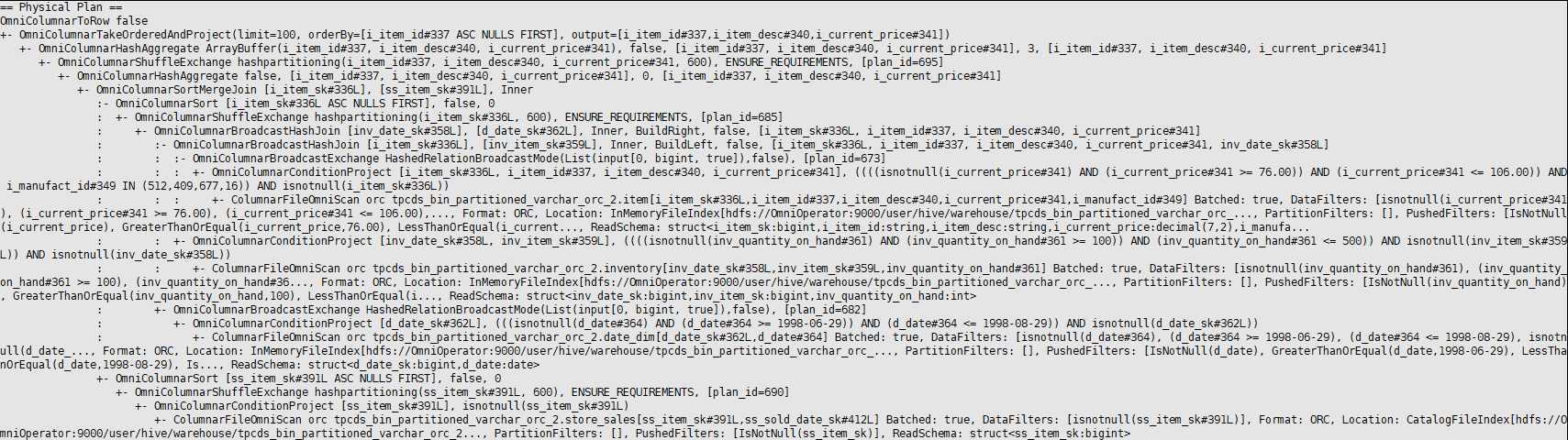
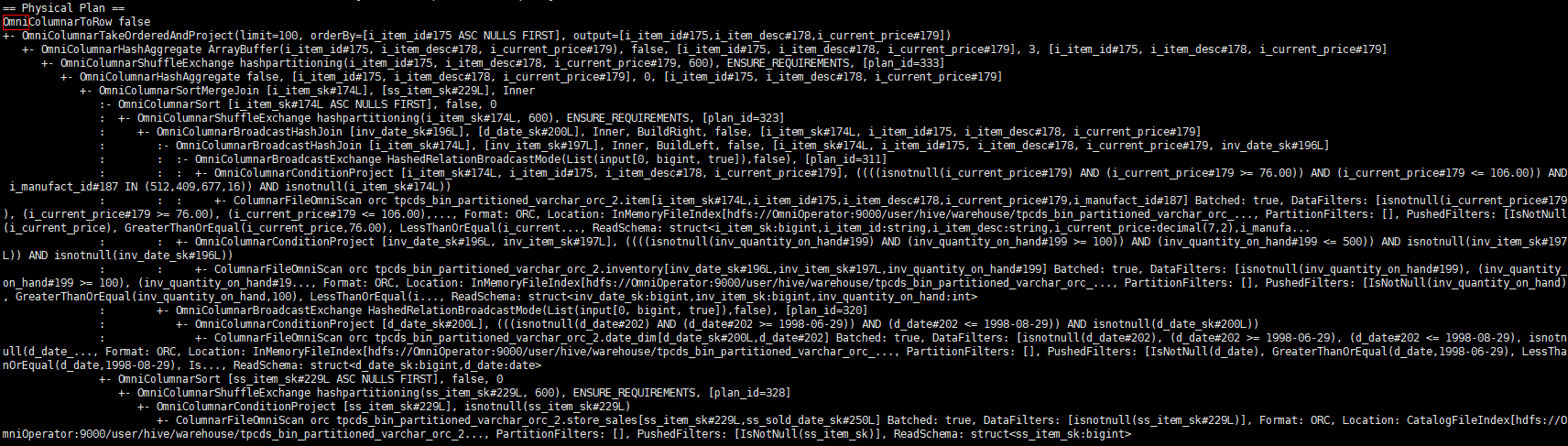
SparkExtension输出执行计划如下图,如果算子以Omni开头则证明SparkExtension生效。
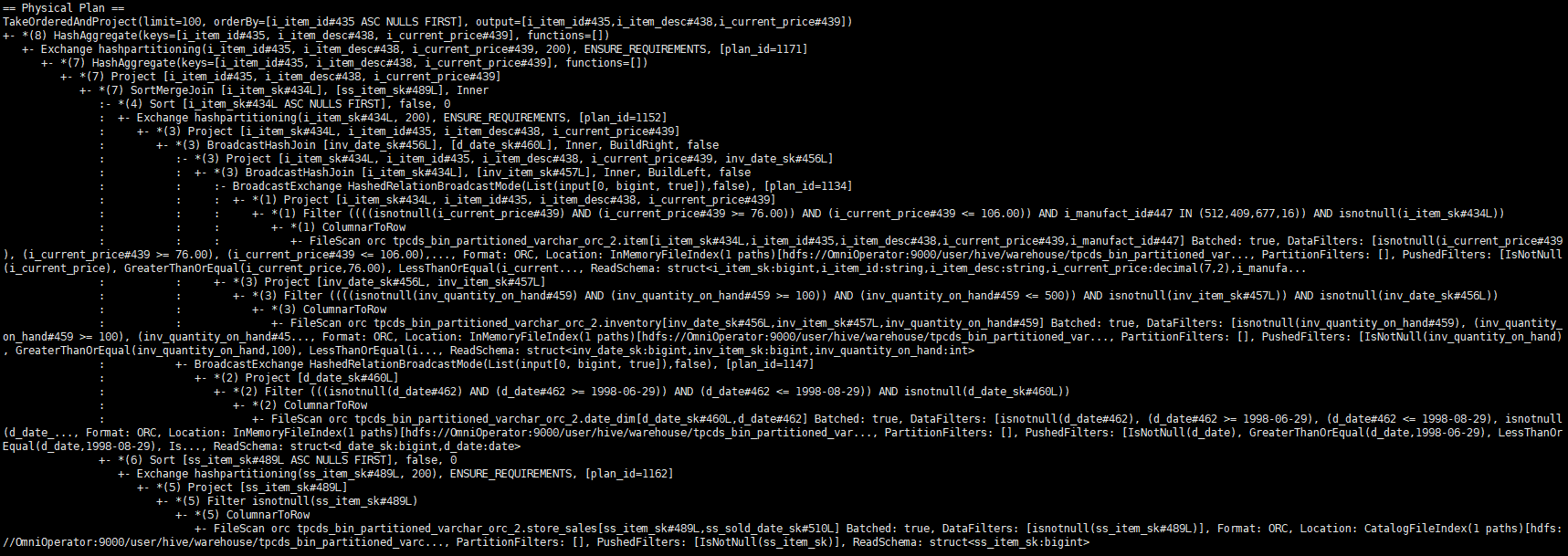
原生Spark-SQL输出执行计划如下图。
- 运行SQL语句。
在SparkExtension和原生Spark-SQL交互式命令行窗口分别运行以下SQL语句。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
set spark.sql.adaptive.enabled=false; select i_item_id ,i_item_desc ,i_current_price from item, inventory, date_dim, store_sales where i_current_price between 76 and 76+30 and inv_item_sk = i_item_sk and d_date_sk=inv_date_sk and d_date between cast('1998-06-29' as date) and cast('1998-08-29' as date) and i_manufact_id in (512,409,677,16) and inv_quantity_on_hand between 100 and 500 and ss_item_sk = i_item_sk group by i_item_id,i_item_desc,i_current_price order by i_item_id limit 100;
- 输出结果对比。