架构介绍
OmniShuffle的Shuffle加速特性是一个大数据引擎Spark的性能加速组件,运行在客户数据中心的大数据集群内,通过内存池统一编址、数据内存语义交换及融合Shuffle等关键特性,减少数据磁盘I/O开销,提高数据分析的时效性和集群资源利用率。
大数据Spark中Shuffle密集型的作业,在Map过程完成后,需要进行大量数据的跨节点交换。统计数据显示,Spark Shuffle过程在很多场景中占据了最多的时间和资源开销,甚至可以占到Spark业务端到端时间开销的50%到80%。Spark提供Shuffle Manager插件的能力,可以对Shuffle过程进行优化。开发者和用户可以通过Shuffle Manager定义的接口构建定制的Shuffle Manager,控制Shuffle的策略、方法和过程。
OmniShuffle的Shuffle加速作为Spark的性能加速组件,通过Spark提供的插件机制,实现Shuffle Manager和Broadcast Manager插件接口,无侵入式替换Spark的原生Shuffle和Broadcast。
OmniShuffle的Shuffle加速通过实现Shuffle Manager插件接口使能In-memory Shuffle,即在内存池中通过内存语义完成Shuffle过程,减少Shuffle数据落盘,降低数据落盘读取、序列化和反序列化、压缩和解压缩带来的时间开销和算力开销。通过实现Broadcast Manager接口使能基于内存池共享的方式进行变量广播,提升广播变量在各个Executor之间的共享传输效率。同时,OmniShuffle的Shuffle加速支持RDMA(Remote Direct Memory Access)和TCP两种网络模式。相比TCP,RDMA可提高传输效率,降低对算力的要求,实现节点间数据的高效交换。
OmniShuffle的Shuffle加速通过基于历史记录的实时调整方式实现Spark SQL作业的并行度自动调整,消除用户针对并行度的调优工作量,同时消除90%以上Shuffle Reduce侧Spill,从而缩短作业运行时间,提高大数据集群作业吞吐量。
整体方案
OmniShuffle的Shuffle加速通过实现Shuffle的Shuffle Manager插件接口使能In-memory Shuffle,OmniShuffle的Shuffle加速整体方案架构如图1所示,子系统的介绍如表1所示。

业务流程
OmniShuffle的Shuffle加速主要通过实现Spark Shuffle Manager接口,实现In-memory Shuffle,OmniShuffle的Shuffle加速业务具体流程如图2所示。
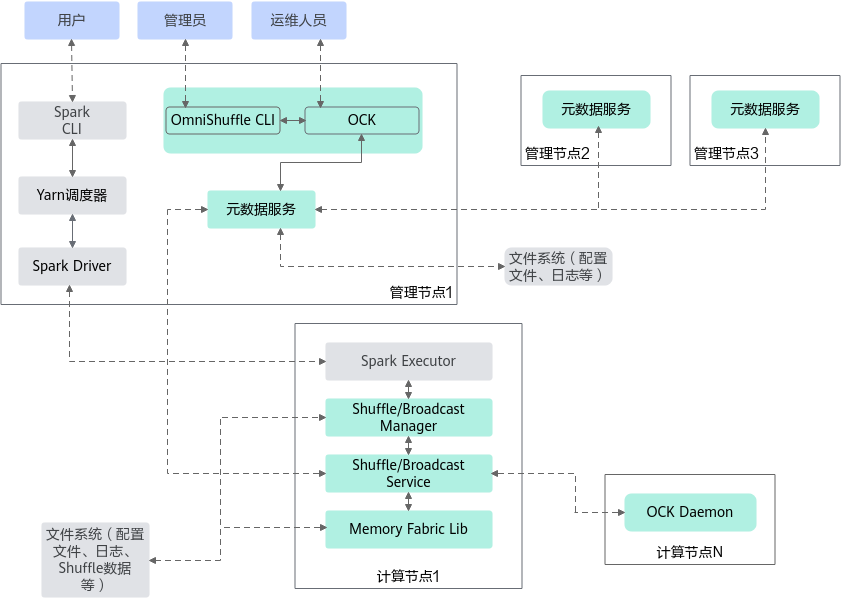
OmniShuffle的Shuffle加速与Spark对接后,用户通过访问Spark的CLI可以查看集群的运行状态。管理员和运维人员可以通过OmniShuffle的Shuffle加速的CLI查看集群的运行状态。