执行Hive引擎业务
Hive使用交互式页面命令行来执行SQL任务,需要注意的是Hive侧查看HiveExtension是否生效需要在SQL语句前加EXPLAIN语句,如果算子是以Omni开头的则代表HiveExtension生效。
本次任务示例使用tpcds_bin_partitioned_varchar_orc_2的数据表作为测试表,测试SQL为TPC-DS测试集的Q82。
相关的表信息如表1所示。
|
表名 |
表格式 |
总行数 |
|---|---|---|
|
item |
orc |
26000 |
|
inventory |
orc |
16966305 |
|
date_dim |
orc |
73049 |
|
store_sales |
orc |
5760749 |
- 启动Hive-SQL命令行窗口。
原生Hive-SQL启动命令如下:
hive --database tpcds_bin_partitioned_varchar_orc_2 --hiveconf hive.fetch.task.conversion=none --hiveconf hive.cbo.enable=true --hiveconf hive.exec.reducers.max=600 --hiveconf hive.exec.compress.intermediate=true --hiveconf hive.tez.container.size=8192 --hiveconf tez.am.resource.memory.mb=8192 --hiveconf tez.task.resource.memory.mb=8192 --hiveconf tez.runtime.io.sort.mb=128 --hiveconf hive.merge.tezfiles=true --hiveconf tez.am.container.reuse.enabled=true
HiveExtension启动命令如下:
hive --database tpcds_bin_partitioned_varchar_orc_2 --hiveconf hive.fetch.task.conversion=none --hiveconf hive.cbo.enable=true --hiveconf hive.exec.reducers.max=600 --hiveconf hive.exec.compress.intermediate=true --hiveconf hive.tez.container.size=8192 --hiveconf tez.am.resource.memory.mb=8192 --hiveconf tez.task.resource.memory.mb=8192 --hiveconf tez.runtime.io.sort.mb=128 --hiveconf hive.merge.tezfiles=true --hiveconf tez.am.container.reuse.enabled=true --hiveconf hive.exec.pre.hooks=com.huawei.boostkit.hive.OmniExecuteWithHookContext --hiveconf tez.task.launch.env=OMNI_CONF=/opt/omni-operator/hive,LD_LIBRARY_PATH=/opt/omni-operator/lib

- 上述启动命令中,OMNI_CONF路径应与配置Hive配置文件中自定义的配置文件目录一致。
- 若数据集包含String类型的数据,且String类型数据单个字段数据量较大时(长度大于512),建议追加以下配置。
--hiveconf omni.hive.string.length=2000
- 若使用较大的Parquet格式数据集(如10TB),建议将Tez任务的hive.tez.container.size及相关的其他参数调大,推荐的启动命令如下:
hive --database tpcds_bin_partitioned_varchar_parquet_10000 --hiveconf tez.task.launch.env=OMNI_CONF=/opt/omni-operator/hive,LD_LIBRARY_PATH=/opt/omni-operator/lib --hiveconf hive.vectorized.execution.enabled=true --hiveconf hive.cbo.enable=true --hiveconf hive.exec.reducers.max=600 --hiveconf hive.exec.compress.intermediate=true --hiveconf hive.tez.container.size=61440 --hiveconf tez.am.resource.memory.mb=61440 --hiveconf tez.task.resource.memory.mb=61440 --hiveconf mapreduce.reduce.java.opts=-Xmx49152m --hiveconf mapreduce.map.java.opts=-Xmx49152m --hiveconf tez.runtime.io.sort.mb=128 --hiveconf hive.merge.tezfiles=true --hiveconf tez.am.container.reuse.enabled=true --hiveconf hive.exec.pre.hooks=com.huawei.boostkit.hive.OmniExecuteWithHookContext --hiveconf tez.container.max.java.heap.fraction=0.5
- 上述启动命令为Yarn模式使用,若使用local模式启动,需要在启动命令末尾追加以下参数。
--hiveconf tez.local.mode=true --hiveconf tez.runtime.optimize.local.fetch=true
HiveExtenion相关的启动参数信息如表2所示。
表2 HiveExtension相关启动参数信息 启动参数名称
缺省值
含义
hive.exec.pre.hooks
com.huawei.boostkit.hive.OmniExecuteWithHookContext
启用HiveExtension。
tez.task.launch.env
OMNI_CONF=/opt/omni-operator/hive,LD_LIBRARY_PATH=/opt/omni-operator/lib
Tez任务进程的环境设置。
hive.fetch.task.conversion
more
控制Hive是否将数据查询转换为MapReduce任务,none表示所有任务都执行MapReduce。
hive.cbo.enable
true
是否启用基于成本的优化器,true表示启用,false表示关闭。
hive.exec.reducers.max
1009
设置reducer的最大数目。
hive.exec.compress.intermediate
false
是否压缩多个map-reduce作业之间由Hive生成的中间文件,true表示启用,false表示关闭。
hive.tez.container.size
-1
设置Tez任务在默认情况下生成的container的大小,单位为MB。
tez.am.resource.memory.mb
1024
设置集群中每个Tez作业对应的ApplicationMaster占用内存大小,单位为MB。
tez.task.resource.memory.mb
1024
Tez容器中已启动任务使用的内存量,单位为MB。
tez.runtime.io.sort.mb
100
设置输出排序内存大小,单位为MB。
hive.merge.tezfiles
false
是否合并Tez作业产生的文件,true表示启用, false表示关闭。
tez.am.container.reuse.enabled
true
是否启用容器重用,true表示启用, false表示关闭。
tez.local.mode
false
是否启用local模式,true表示启用,false表示关闭。
tez.runtime.optimize.local.fetch
true
是否启用local模式获取文件逻辑优化,true表示启用,false表示关闭。
hive.vectorized.execution.enabled
true
是否启用Hive向量化,true表示开启,false表示关闭。
mapreduce.map.java.opts
-Xmx200m
Map任务可以使用的最大堆内存
mapreduce.reduce.java.opts
-Xmx200m
Reduce任务可以使用的最大堆内存
tez.container.max.java.heap.fraction
0.8
Tez主任务进程可以使用的堆内存占容器内存的比例
omni.hive.string.length
空
Hive Extension所支持的String类型数据最大长度
- 查看HiveExtenison是否生效。
在HiveExtension和原生Hive-SQL交互式命令行窗口分别运行以下SQL语句。
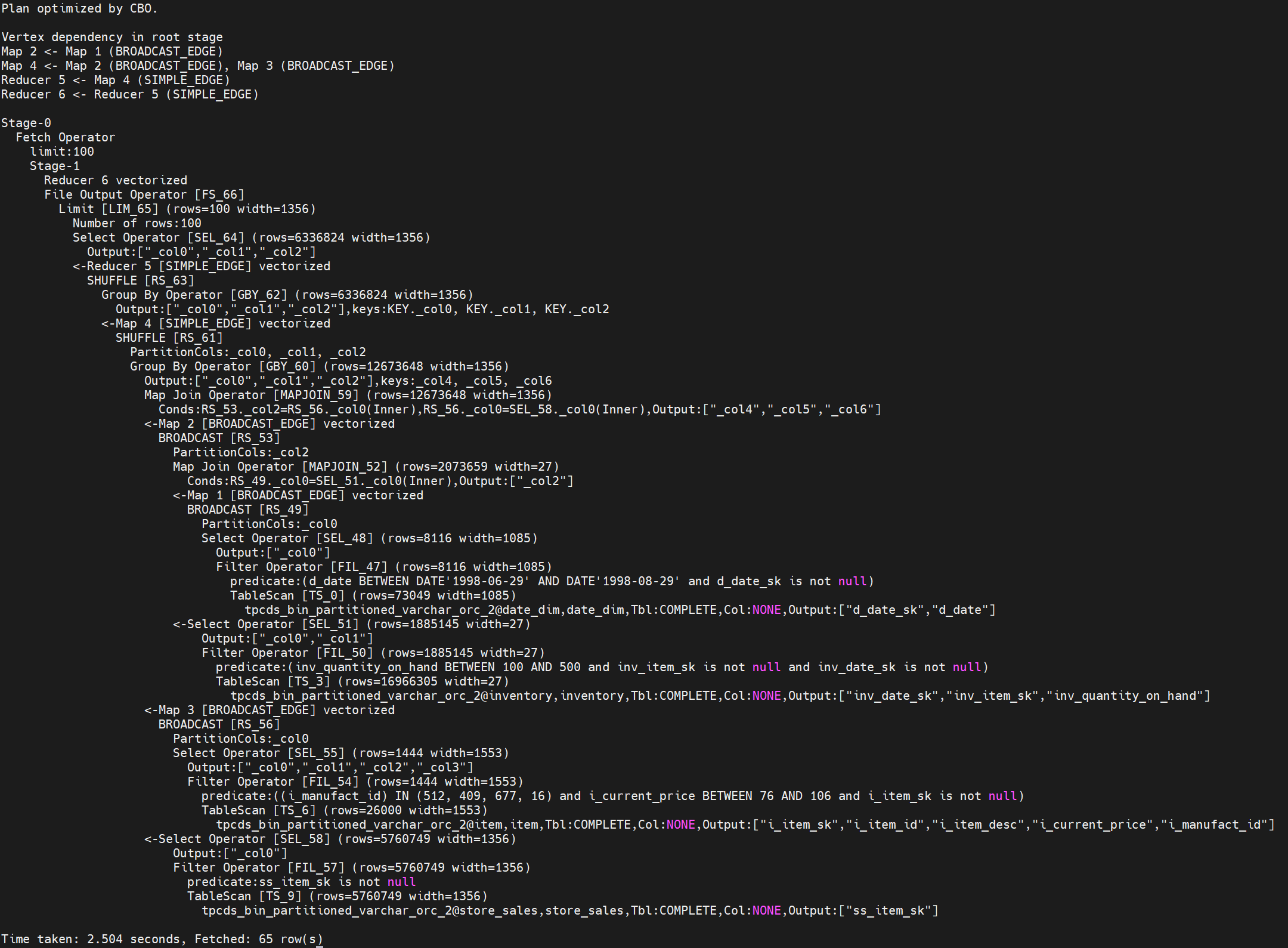
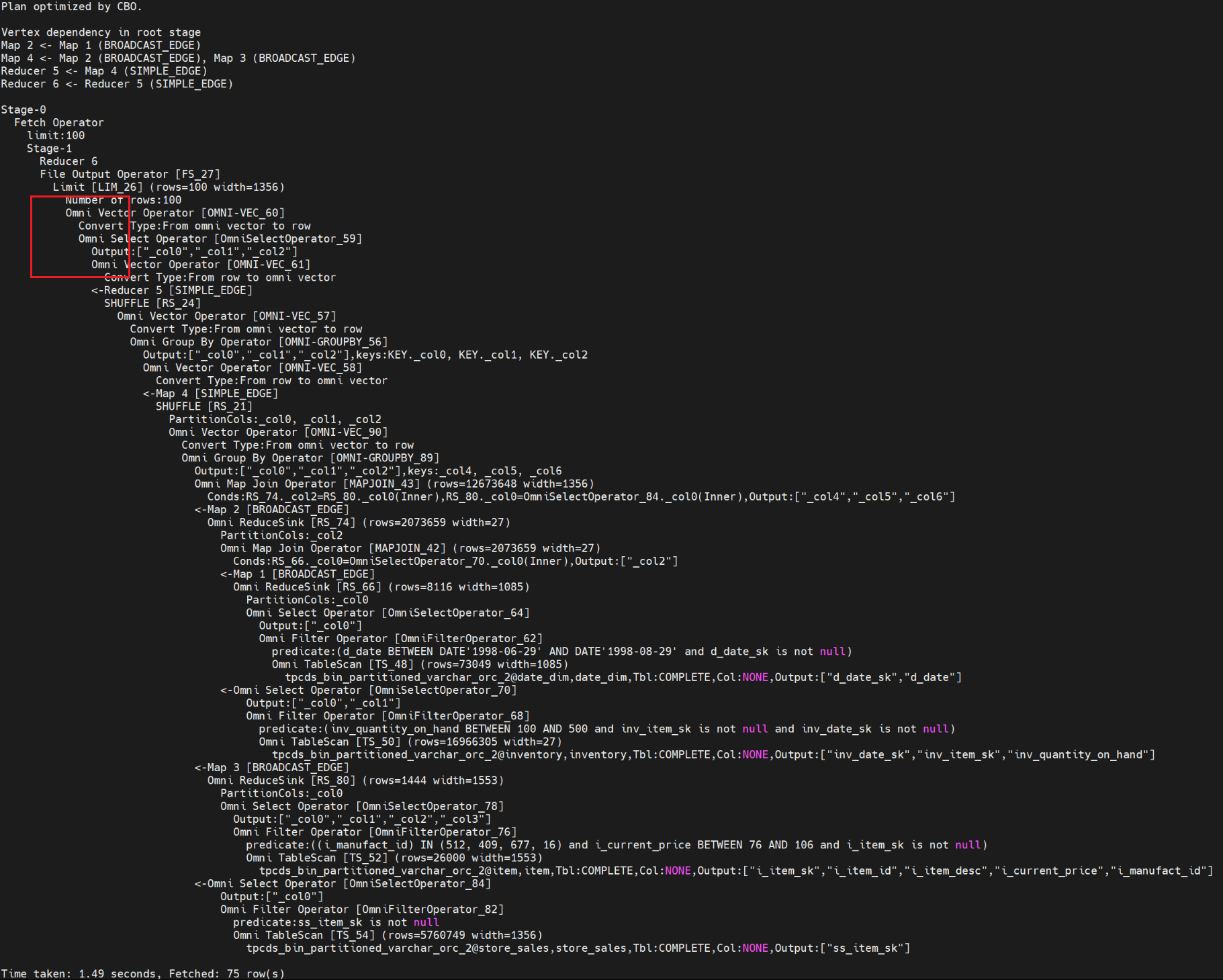
explain select i_item_id ,i_item_desc ,i_current_price from item, inventory, date_dim, store_sales where i_current_price between 76 and 76+30 and inv_item_sk = i_item_sk and d_date_sk=inv_date_sk and d_date between cast('1998-06-29' as date) and cast('1998-08-29' as date) and i_manufact_id in (512,409,677,16) and inv_quantity_on_hand between 100 and 500 and ss_item_sk = i_item_sk group by i_item_id,i_item_desc,i_current_price order by i_item_id limit 100;HiveExtension输出执行计划如下图,算子以Omni开头则说明HiveExtension生效。
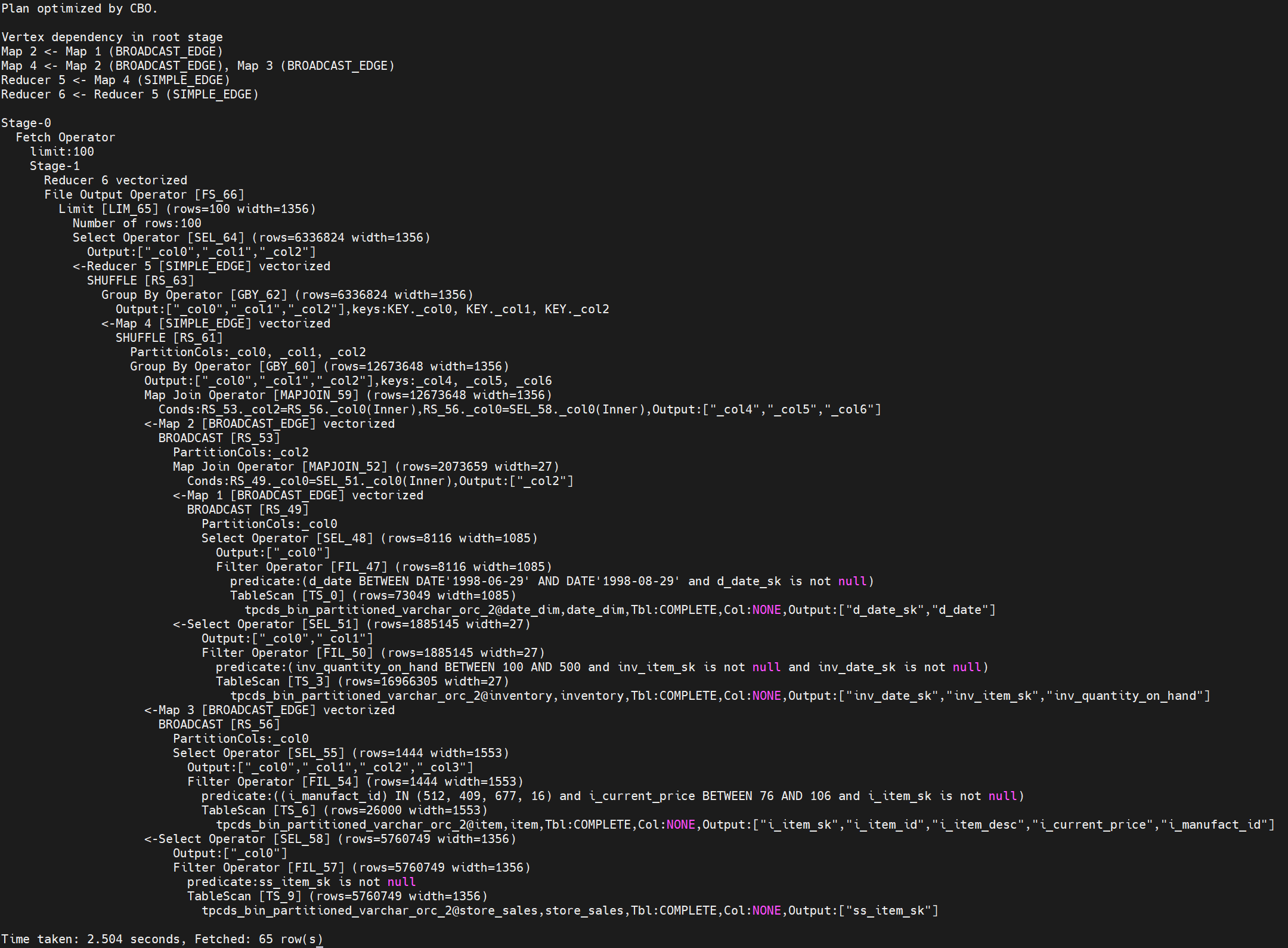
原生Hive-SQL输出执行计划如下图。
- 运行SQL语句。
在HiveExtension和原生Hive-SQL交互式命令行窗口分别运行以下SQL语句。
select i_item_id ,i_item_desc ,i_current_price from item, inventory, date_dim, store_sales where i_current_price between 76 and 76+30 and inv_item_sk = i_item_sk and d_date_sk=inv_date_sk and d_date between cast('1998-06-29' as date) and cast('1998-08-29' as date) and i_manufact_id in (512,409,677,16) and inv_quantity_on_hand between 100 and 500 and ss_item_sk = i_item_sk group by i_item_id,i_item_desc,i_current_price order by i_item_id limit 100; - 输出过程对比。