矩阵转置&block示例
调优思路
- 在对B矩阵进行转置保证cache line对齐寻址的情况下,迭代小区域的block减少cache miss。
- block的size调整需要根据实际cache size大小和具体环境配置综合考虑。
图1 矩阵转置示意
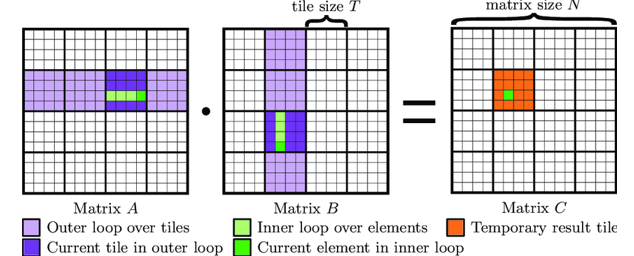
图2 矩阵转置&block代码

操作步骤
- 运行矩阵行列大小为8192的block_transpose_B_matmult示例。
1./matmul 8192 4
返回信息如下:
1 2 3
Size is 8192, Matrix multiplication method is: 4, Check correctness is: 0 Initialization time = 2.787273s Matrix multiplication time = 3.711554s
矩阵行列大小为8192情况下,并行计算耗时3.7秒左右。
- 创建矩阵行列大小为8192的block_transpose_B_matmult示例的Roofline任务。
1devkit tuner roofline -o block_transpose_B_matmult_8192 -m region ./matmul 8192 4
返回信息如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Note: 1. Roofline task is currently only supported on the 920 platform. 2. The application must be a binary file in ELF format, and read permissions are required to detect the format of the application. 3. Roofline task collection needs to ensure the application has finished running. 4. The estimated time of roofline collection is about 3 * application estimated time. 5. Roofline analysis is available only on physical machines. 6. You can learn about the roofline profiling method by looking at document /usr/local/devkit/tuner/docs/ROOFLINE_KNOW_HOW.MD RFCOLLECT: Start collection for ./matmul RFCOLLECT: Launch application to collect performance metrics of ./matmul Size is 8192, Matrix multiplication method is: 4, Check correctness is: 0 Initialization time = 2.794598s ROOFLINE_EVENTS are initialized. Matrix multiplication time = 3.743286s RFCOLLECT: Launch application to do binary instrumentation of ./matmul Size is 8192, Matrix multiplication method is: 4, Check correctness is: 0 Initialization time = 8.353251s Matrix multiplication time = 3.849523s RFCOLLECT: Launch benchmarks for measuring roofs RFCOLLECT: Processing all collected data RFCOLLECT: Result is captured at /matrix_multiplication/rfcollect-20240506-195201.json RFCOLLECT: Run "rfreport /matrix_multiplication/rfcollect-20240506-195201.json" to get report. Get roofline report ... The roofline json report: /matrix_multiplication/block_transpose_B_matmult_8192.json The roofline html report: /matrix_multiplication/block_transpose_B_matmult_8192.html
- 查看block_transpose_B_matmult_8192_html报告。
此时获取的roofs的并行度为128,获取到Elapsed Time 3.646s, GFLOP Count 1168.231,Performance 320.399 GFLOPS。
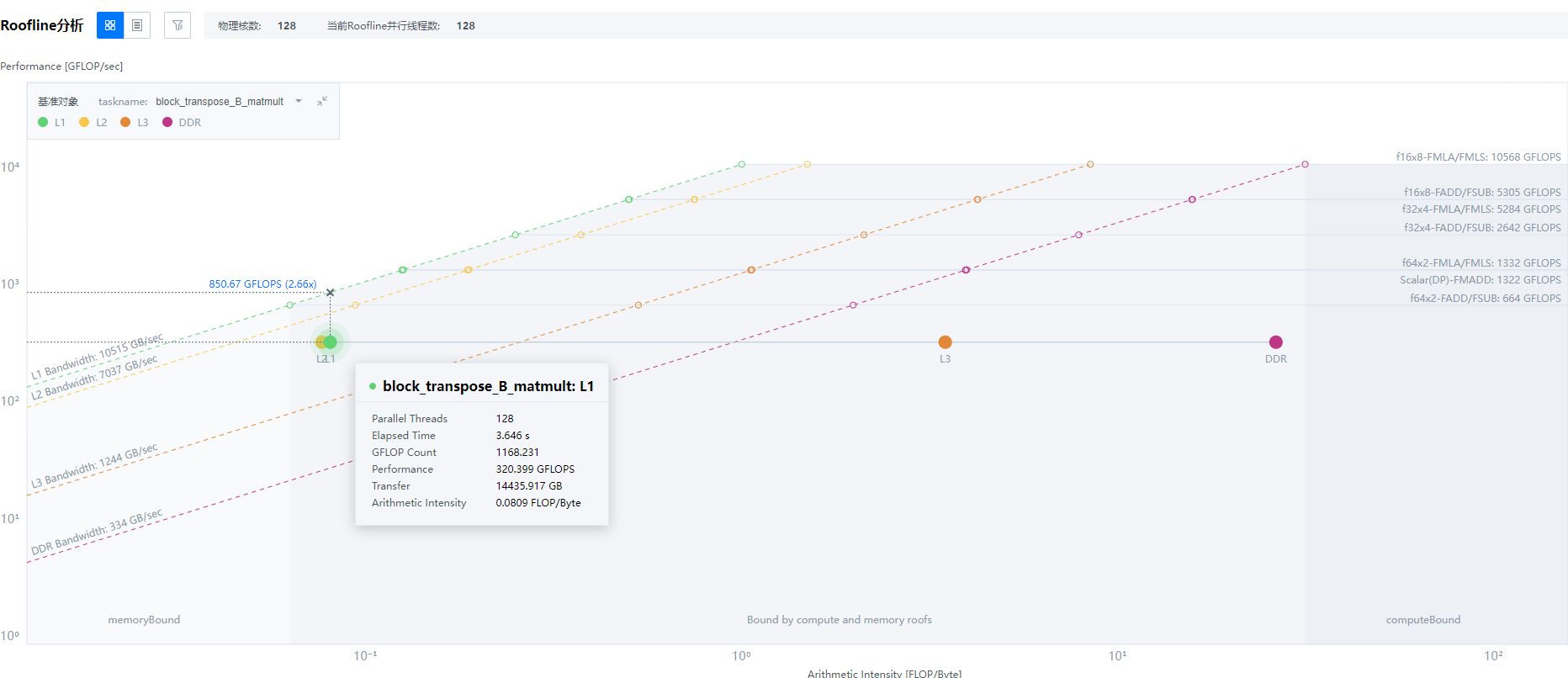
优化效果
使用内部block块循环增加了6.25%的额外计算(从1099.512 GFLOP到1168.231 GFLOP), 但整体性能有191.9%提升,因此端到端性能有大幅提升,详见下表。
- 图3中的L1、L2、L3和DDR均处于Compute and Memory Bound区域。
- 当前内存瓶颈在L1和L2,主要在L2。
- 缓存局部效应:Cache line utilization相比于矩阵转置型示例变好,计算密度(FLOP/Byte):L1 ≈ L2 < L3 < DDR。
|
case |
Elapsed Time(s) |
GFLOP Count |
Performance |
单位时间性能倍率(相比于前一case) |
端到端性能倍率(相比于前一case) |
单位时间性能倍率(相比于基准case) |
端到端性能倍率(相比于基准case) |
|---|---|---|---|---|---|---|---|
|
parallel_matmult_8192 |
516.824 |
1099.512 |
2.127 |
-- |
-- |
-- |
-- |
|
transpose_B_matmult_8192 |
10.017 |
1099.512 |
109.763 |
51.595 |
51.595 |
51.595 |
51.595 |
|
block_transpose_B_matmult_8192 |
3.646 |
1168.231 |
320.399 |
2.919 |
2.747 |
150.634 |
141.751 |
图4 对比分析
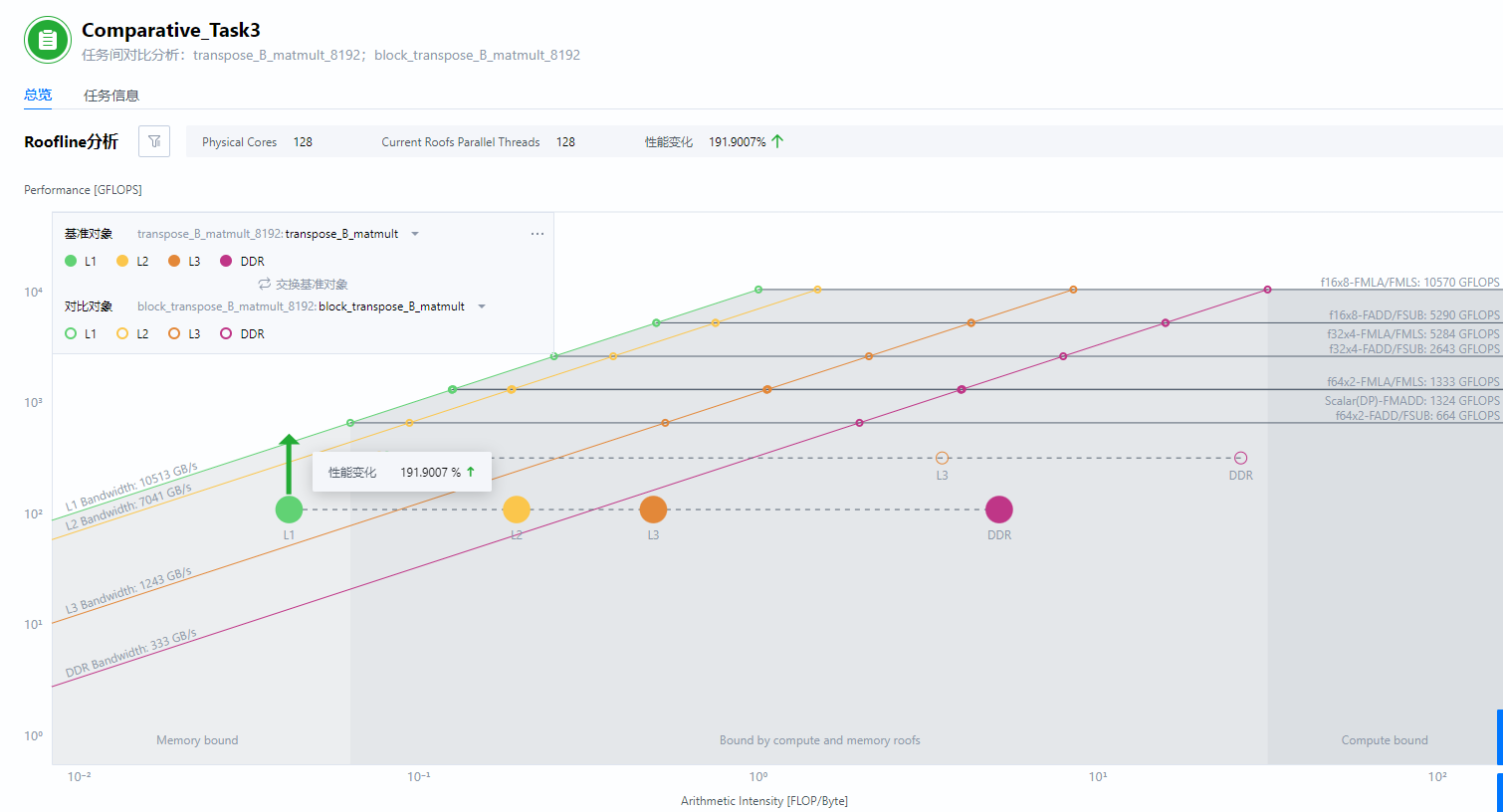

Web模式的Roofline分析任务支持对比任务,可以使用Web模式查看对比分析结果。
对比transpose_B_matmult 8192与block_transpose_B_matmult 8192。
- Going UP:Performance提升了1.919倍。
- Going RIGHT:
- 所有点的计算密度都有了增加(good)。
- DDR点更加远离cache点,访存瓶颈得到进一步优化。
- 缓存未命中和来自DDR的加载都减少,缓存重用增加,从而观察到性能改进。
- DDR目前接近Compute Bound,可以开始做计算方式的优化。
父主题: 使用Roofline进行性能分析