KML示例
对于之前并行示例到矩阵转置&block&vector示例运行时间进行优化。

操作步骤
- 运行矩阵行列大小为8192的kml_matmult示例。
1./matmul 8192 6
返回信息如下:
1 2 3
Size is 8192, Matrix multiplication method is: 6, Check correctness is: 0 Initialization time = 2.789213s Matrix multiplication time = 0.271790s
矩阵行列大小为8192,并行计算耗时0.27秒左右。
- 创建kml_matmult 8192示例的Roofline任务。
1devkit tuner roofline -o kml_matmult_8192 -m region ./matmul 8192 6
返回信息如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Note: 1. Roofline task is currently only supported on the 920 platform. 2. The application must be a binary file in ELF format, and read permissions are required to detect the format of the application. 3. Roofline task collection needs to ensure the application has finished running. 4. The estimated time of roofline collection is about 3 * application estimated time. 5. Roofline analysis is available only on physical machines. 6. You can learn about the roofline profiling method by looking at document /usr/local/devkit/tuner/docs/ROOFLINE_KNOW_HOW.MD RFCOLLECT: Start collection for ./matmul RFCOLLECT: Launch application to collect performance metrics of ./matmul Size is 8192, Matrix multiplication method is: 6, Check correctness is: 0 Initialization time = 2.794584s ROOFLINE_EVENTS are initialized. Matrix multiplication time = 0.432760s RFCOLLECT: Launch application to do binary instrumentation of ./matmul Size is 8192, Matrix multiplication method is: 6, Check correctness is: 0 Initialization time = 8.353567s Matrix multiplication time = 0.283024s RFCOLLECT: Launch benchmarks for measuring roofs RFCOLLECT: Processing all collected data RFCOLLECT: Result is captured at /matrix_multiplication/rfcollect-20240506-203926.json RFCOLLECT: Run "rfreport /matrix_multiplication/rfcollect-20240506-203926.json" to get report. Get roofline report ... The roofline json report: /matrix_multiplication/kml_matmult_8192.json The roofline html report: /matrix_multiplication/kml_matmult_8192.html
- 查看kml_matmult_8192报告。图2 kml_matmult_8192报告
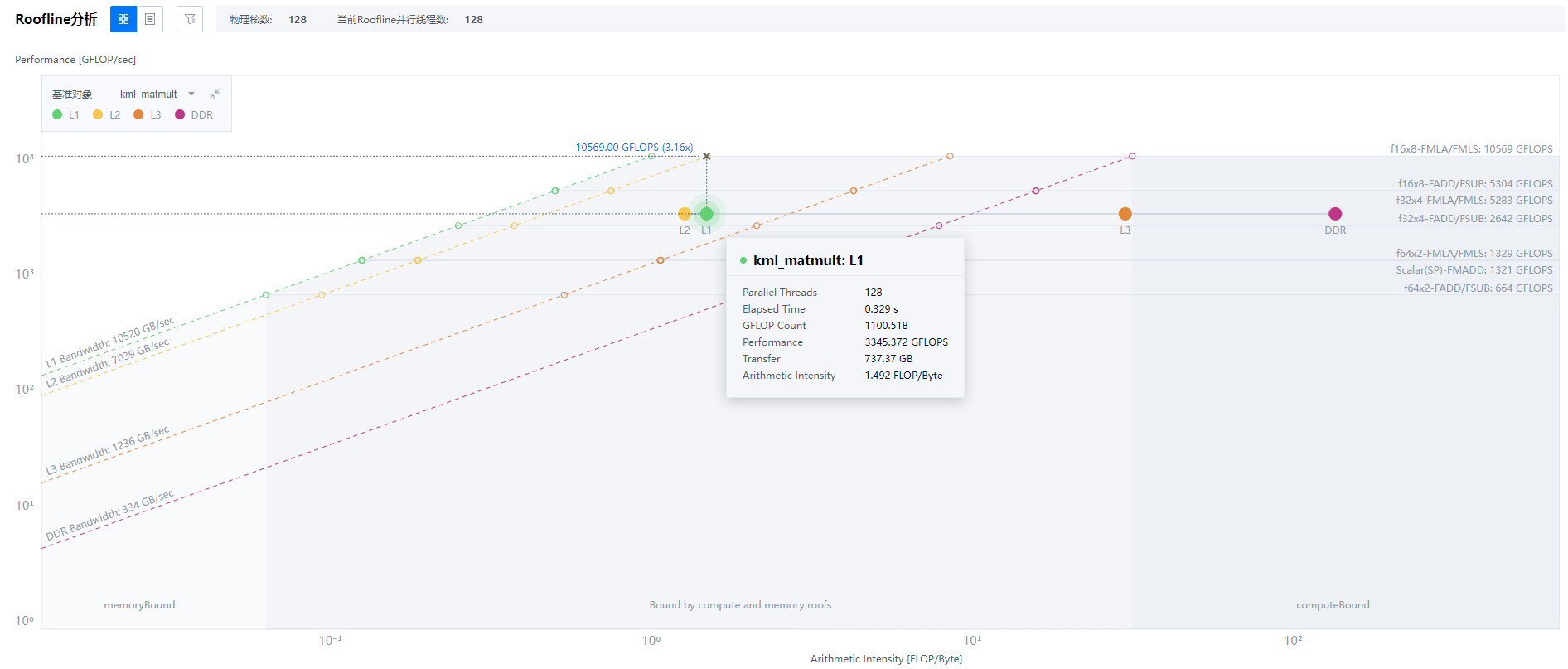
获取的roofs的并行度为128,获取到Elapsed Time 0.329s,GFLOP Count 1100.518,Performance 3345.372 GFLOPS。
优化效果
使用KML数学库加速后,计算量恢复到了原有的值(基于数学推导优化,计算量基本不变),数据库优化带来了极大的性能提升,因此端到端性能有了极大的提升,详见下表。
从最基础的并行计算,到最终使用数学库优化, 可以看到程序的端到端时间从516.824秒优化到了0.329秒,整体性能提升1570倍。
|
case |
Elapsed Time(s) |
GFLOP Count |
Performance |
单位时间性能倍率(相比于前一case) |
端到端性能倍率(相比于前一case) |
单位时间性能倍率(相比于基准case) |
端到端性能倍率(相比于基准case) |
|---|---|---|---|---|---|---|---|
|
parallel_matmult_8192 |
516.824 |
1099.512 |
2.127 |
-- |
-- |
-- |
-- |
|
transpose_B_matmult_8192 |
10.017 |
1099.512 |
109.763 |
51.595 |
51.595 |
51.595 |
51.595 |
|
block_transpose_B_matmult_8192 |
3.646 |
1168.231 |
320.399 |
2.919 |
2.747 |
150.634 |
141.751 |
|
intrinsics_transpose_B_matmult_8192 |
2.652 |
1717.987 |
647.781 |
2.013 |
1.369 |
303.181 |
194.003 |
|
kml_matmult_8192 |
0.329 |
1100.518 |
3345.372 |
5.188 |
8.097 |
1572.812 |
1570.894 |
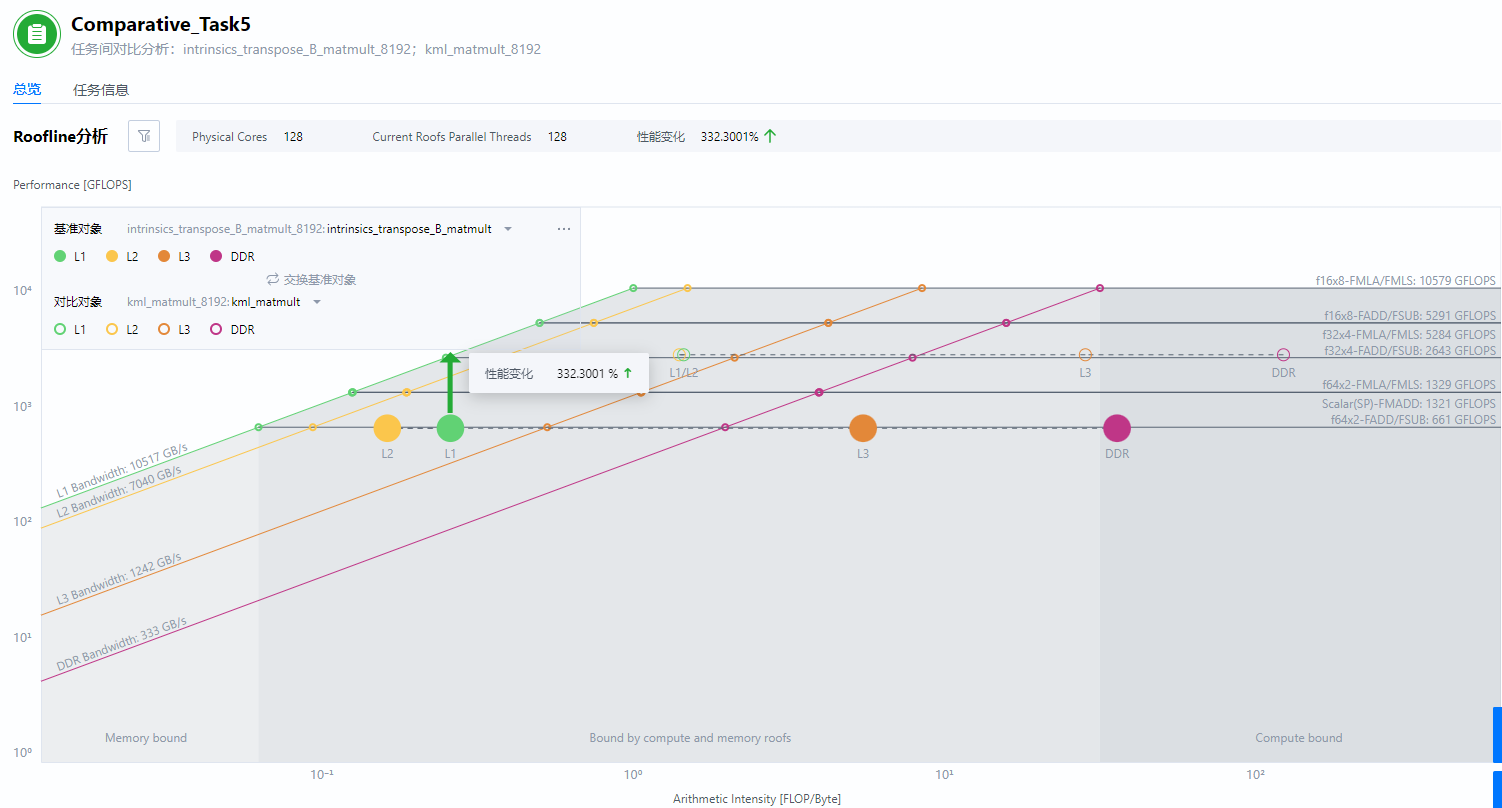

Web模式的Roofline分析任务支持对比任务,可以使用Web模式查看对比分析结果。
- Going UP:Performance提升了3倍多。
- Going RIGHT:较少的右移,使用向量化指令让计算变得更快,计算密度(FLOP/Byte)没有发生太大的变化 (预期中)。