Spark配置
操作步骤
- 使用PuTTY工具,以root用户登录服务器。
- 执行以下命令下载scala。
cd /path/to/HADOOP wget https://downloads.lightbend.com/scala/2.12.4/scala-2.12.4.tgz tar xvf scala-2.12.4.tgz
- 执行以下命令解压Spark安装包。
tar -xvf spark-2.4.4-bin-hadoop2.7.tgz
- 执行以下命令进入解压后的目录。
cd /path/to/HADOOP/spark-2.4.4-bin-hadoop2.7/conf
- 执行以下命令修改“spark-defaults.conf”配置文件。
mv spark-defaults.conf.template spark-defaults.conf vi spark-defaults.conf
- 按“i”进入编辑模式,编辑“spark-defaults.conf”文件,新增以下内容。
spark.master spark://armnode2:7077 spark.scheduler.mode FAIR spark.eventLog.enabled true spark.eventLog.dir hdfs://armnode2:9000/sparklog spark.shuffle.consolidateFiles true spark.shuffle.manager SORT spark.sql.hive.convertMetastoreOrc false

“armnode2”为安装环境的主机名,用户根据实际情况进行配置,可以使用“hostname”查询安装环境的主机名。
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 按“i”进入编辑模式,编辑“spark-defaults.conf”文件,新增以下内容。
- 执行以下命令修改“slaves”配置文件。
mv slaves.template slaves vi slaves
- 按“i”进入编辑模式,编辑“slaves”文件,新增安装环境的主机名。
armnode2
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 按“i”进入编辑模式,编辑“slaves”文件,新增安装环境的主机名。
- 执行以下命令修改“spark-env.sh”配置文件。
mv spark-env.sh.template spark-env.sh vi spark-env.sh
- 按“i”进入编辑模式,编辑“spark-env.sh”文件,新增以下内容。
export JAVA_HOME=/path/to/HADOOP/jdk1.8.0_171 export SCALA_HOME=/path/to/HADOOP/scala-2.12.4 export SPARK_HOME=/path/to/HADOOP/spark-2.4.4-bin-hadoop2.7 export SPARK_MASTER_IP=armnode2 export HADOOP_HOME=/path/to/HADOOP/hadoop-3.1.2 export HADOOP_CONF_DIR=/path/to/HADOOP/hadoop-3.1.2/etc/hadoop export SPARK_DIST_CLASSPATH=$(/path/to/HADOOP/hadoop-3.1.2/bin/hadoop classpath) export SPARK_DRIVER_MEMORY=30g export SPARK_WORKER_INSTANCES=10 export SPARK_WORKER_CORES=16 export SPARK_WORKER_MEMORY=20g export SPARK_EXECUTOR_MEMORY=10g export SPARK_LOCAL_DIRS=/path/to/HADOOP/hadoop-3.1.2/hdfs/spark/tmp export SPARK_WORKER_DIR=/path/to/HADOOP/hadoop-3.1.2/hdfs/spark/work
“armnode2”为安装环境的主机名,用户根据实际情况进行配置,可以使用“hostname”查询安装环境的主机名。
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 按“i”进入编辑模式,编辑“spark-env.sh”文件,新增以下内容。
- 执行以下命令进入配置文件目录。
cd /path/to/HADOOP
- 执行以下命令配置环境变量。
- 打开文件。
vi env.sh - 按“i”进入编辑模式,新建环境变量文件,添加如下内容。
export JAVA_HOME=/path/to/HADOOP/jdk1.8.0_171 export JRE_HOME=$JAVA_HOME/jre export PATH=:$JAVA_HOME/bin:$PATH export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export HADOOP_HOME=/path/to/HADOOP/hadoop-3.1.2 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HDFS_DATANODE_USER=root export HDFS_NAMENODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export SCALA_HOME=/path/to/HADOOP/scala-2.12.4 export PATH=$SCALA_HOME/bin:$PATH export SPARK_HOME=/path/to/HADOOP/spark-2.4.4-bin-hadoop2.7 export PATH=$SPARK_HOME/bin:$PATH
Hadoop配置文件说明:
Hadoop的运行方式是由配置文件决定的(运行Hadoop时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除core-site.xml中的配置项。
此外,伪分布式虽然只需要配置fs.defaultFS和dfs.replication就可以运行(官方教程如此),不过若没有配置hadoop.tmp.dir参数,则默认使用的临时目录为/tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行format才行。所以我们进行了设置,同时也指定dfs.namenode.name.dir和dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 执行以下命令使环境变量生效。
source env.sh
- 打开文件。
- 配置完成后,执行NameNode的格式化。
hdfs namenode -format
显示如下内容表示正常结束。

- 执行以下命令开启NameNode和DataNode守护进程。
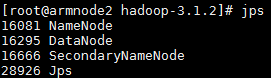
start-dfs.sh jps
启动完成后,可以通过命令jps来判断是否成功启动,若成功启动则会列出如图1所示进程: “NameNode”、“DataNode”和“SecondaryNameNode”(如果“SecondaryNameNode”没有启动,请运行sbin/stop-dfs.sh关闭进程,然后再次尝试启动尝试)。如果没有“NameNode”或“DataNode”,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
- 执行以下命令进入spark相应路径。
cd /path/to/HADOOP/spark-2.4.4-bin-hadoop2.7/sbin
- 执行以下命令开启spark进程。
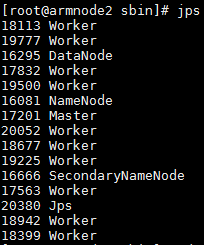
./start-all.sh jps
启动完成后,可以通过命令jps来判断是否成功启动,若成功启动则会列出多个“Worker”进程,如图2所示。
父主题: 编译和安装