编译和安装
操作步骤
- 使用PuTTY工具,以root用户登录服务器。
- 执行以下命令下载源码到“/path/to”目录。
cd /path/to git clone -b v5.0.1428 https://github.com/rcedgar/muscle.git
- 执行以下命令进入“src”目录。
cd /path/to/muscle/src
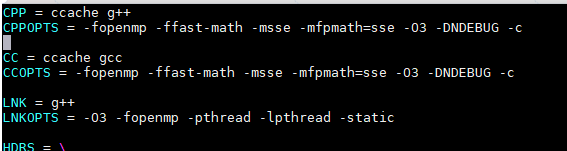
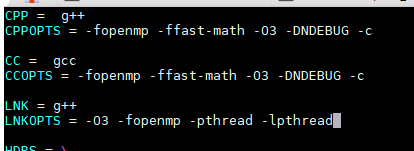
- 执行以下命令修改“Makefile”文件。
- 执行以下命令修改“pairhmm.h”文件。
- 执行以下命令修改“pairhmm.cpp”文件。
- 执行以下命令修改“perturbhmm.cpp”文件。
- 执行以下命令修改“multisequence.cpp”文件。
- 执行以下命令修改“myutils.cpp”文件。
- 执行以下命令修改“timing.h”文件。
- 打开“timing.h”文件。
vi timing.h
- 按“i”进入编辑模式。
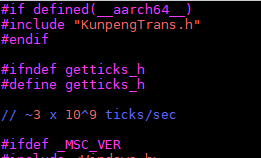
- 在文件开头添加一个宏定义。
#if defined(__aarch64__) #include "KunpengTrans.h" #endif
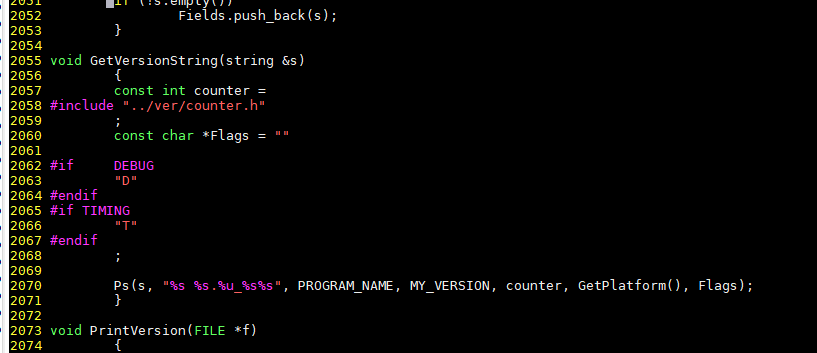
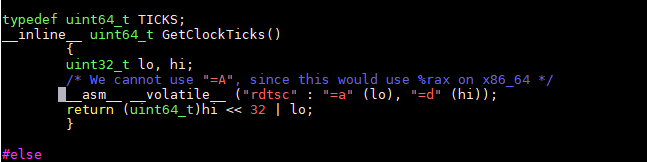
修改前:
修改后:
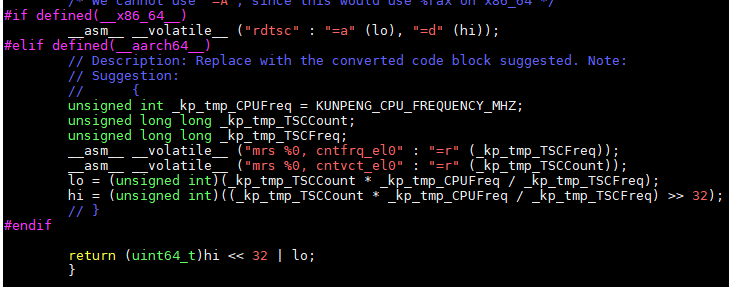
- 修改第25行的相关代码“__asm__ __volatile__ ("rdtsc" : "=a" (lo), "=d" (hi))”,修改代码如下。
#if defined(__x86_64__) __asm__ __volatile__ ("rdtsc" : "=a" (lo), "=d" (hi)); #elif defined(__aarch64__) // Description: Replace with the converted code block suggested. Note: // Suggestion: // { unsigned int _kp_tmp_CPUFreq = KUNPENG_CPU_FREQUENCY_MHZ; unsigned long long _kp_tmp_TSCCount; unsigned long long _kp_tmp_TSCFreq; __asm__ __volatile__ ("mrs %0, cntfrq_el0" : "=r" (_kp_tmp_TSCFreq)); __asm__ __volatile__ ("mrs %0, cntvct_el0" : "=r" (_kp_tmp_TSCCount)); lo = (unsigned int)(_kp_tmp_TSCCount * _kp_tmp_CPUFreq / _kp_tmp_TSCFreq); hi = (unsigned int)((_kp_tmp_TSCCount * _kp_tmp_CPUFreq / _kp_tmp_TSCFreq) >> 32); // } #endif修改前:
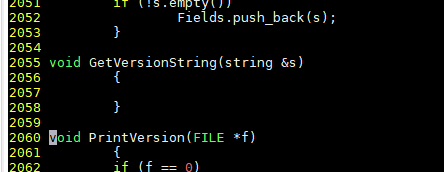
修改后:
- 在文件开头添加一个宏定义。
- 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 打开“timing.h”文件。
- 执行以下命令创建“KunpengTrans.h”文件。
- 创建“KunpengTrans.h”文件。
- 按“i”进入编辑模式,添加如下内容。
/* * @Description: KunpengTrans.h * @Copyright (c) Huawei Technologies Co., Ltd. 2020-2020. All rights reserved. */ #ifndef KUNPENG_TRANS_H #define KUNPENG_TRANS_H #include <string.h> /* ATTENTION: * Please set KUNPENG_CPU_FREQUENCY_MHZ to the actual cpu frequecy of your running environment. */ const int KUNPENG_CPU_FREQUENCY_MHZ = 2600; const int EAX_LEAF = 7; const int SHIFT_THREE = 3; /* CASE eax = 0; Highest Function Parameter and Manufacturer ID */ void GetCPUManuID(unsigned int *ebx, unsigned int *edx, unsigned int *ecx); // %ecx #define bit_SSE3 (1 << 0) #define bit_PCLMUL (1 << 1) #define bit_LZCNT (1 << 5) #define bit_SSSE3 (1 << 9) #define bit_FMA (1 << 12) #define bit_CMPXCHG16B (1 << 13) #define bit_SSE4_1 (1 << 19) #define bit_SSE4_2 (1 << 20) #define bit_MOVBE (1 << 22) #define bit_POPCNT (1 << 23) #define bit_AES (1 << 25) #define bit_XSAVE (1 << 26) #define bit_OSXSAVE (1 << 27) #define bit_AVX (1 << 28) #define bit_F16C (1 << 29) #define bit_RDRND (1 << 30) // %edx #define bit_CMPXCHG8B (1 << 8) #define bit_CMOV (1 << 15) #define bit_MMX (1 << 23) #define bit_FXSAVE (1 << 24) #define bit_SSE (1 << 25) #define bit_SSE2 (1 << 26) /* CASE eax = 1; Processor Info and Feature Bits * Skylake: eax = 0x00050654, ebx = 0x43400800, ecx = 0x7ffefbf7, edx = 0xbfebfbff (采样于6148) * Cascade Lake : eax = 0x00050657, ebx = 0x08400800, ecx = 0x7ffefbf7, edx = 0xbfebfbff (采样于6248) */ void GetCPUFeature(unsigned int *eax, unsigned int *ebx, unsigned int *ecx, unsigned int *edx); /* %ebx */ #define bit_FSGSBASE (1 << 0) #define bit_SGX (1 << 2) #define bit_BMI (1 << 3) #define bit_HLE (1 << 4) #define bit_AVX2 (1 << 5) #define bit_BMI2 (1 << 8) #define bit_RTM (1 << 11) #define bit_MPX (1 << 14) #define bit_AVX512F (1 << 16) #define bit_AVX512DQ (1 << 17) #define bit_RDSEED (1 << 18) #define bit_ADX (1 << 19) #define bit_AVX512IFMA (1 << 21) #define bit_CLFLUSHOPT (1 << 23) #define bit_CLWB (1 << 24) #define bit_AVX512PF (1 << 26) #define bit_AVX512ER (1 << 27) #define bit_AVX512CD (1 << 28) #define bit_SHA (1 << 29) #define bit_AVX512BW (1 << 30) #define bit_AVX512VL (1u << 31) /* %ecx */ #define bit_PREFETCHWT1 (1 << 0) #define bit_AVX512VBMI (1 << 1) #define bit_PKU (1 << 3) #define bit_OSPKE (1 << 4) #define bit_AVX512VBMI2 (1 << 6) #define bit_SHSTK (1 << 7) #define bit_GFNI (1 << 8) #define bit_VAES (1 << 9) #define bit_AVX512VNNI (1 << 11) #define bit_VPCLMULQDQ (1 << 10) #define bit_AVX512BITALG (1 << 12) #define bit_AVX512VPOPCNTDQ (1 << 14) #define bit_RDPID (1 << 22) #define bit_MOVDIRI (1 << 27) #define bit_MOVDIR64B (1 << 28) /* %edx */ #define bit_AVX5124VNNIW (1 << 2) #define bit_AVX5124FMAPS (1 << 3) #define bit_IBT (1 << 20) #define bit_PCONFIG (1 << 18) /* CASE eax = 7, ecx = 0; Extended Features * Skylake: eax = 0x00000000, ebx = 0xd39ffffb, ecx = 0x00000018, edx = 0x9c002400 (采样于6148) * Cascade Lake : eax = 0x00000000, ebx = 0xd39ffffb, ecx = 0x00000818, edx = 0xbc000400 (采样于6248) */ void GetExtendCPUFeature(unsigned int *eax, unsigned int *ebx, unsigned int *ecx, unsigned int *edx); /* * GetSupportedCPUID only supported while eax = 0, eax = 1 , eax = 7 and ecx = 0 * In other cases always return 0x0; * chipID support 1,2 -- 1 for skylake server eg. 6148; 2 for Cascade Lake 6248 */ void GetSupportedCPUID(unsigned int *eax, unsigned int *ebx, unsigned int *ecx, unsigned int *edx); void RepStos(void *dest, unsigned long long src, unsigned long long len, unsigned width, int df); void RepStosB(void *dest, unsigned long long src, unsigned long long len, int DF); void RepStosW(void *dest, unsigned long long src, unsigned long long len, int DF); void RepStosD(void *dest, unsigned long long src, unsigned long long len, int DF); void RepStosQ(void *dest, unsigned long long src, unsigned long long len, int DF); void RepMovs(void *dest, void *src, unsigned long long len, unsigned width, int df); #include <arm_neon.h> #define KP_FORCE_INLINE static inline __attribute__((always_inline)) typedef union { int8x16_t vect_s8; int16x8_t vect_s16; int32x4_t vect_s32; int64x2_t vect_s64; uint8x16_t vect_u8; uint16x8_t vect_u16; uint32x4_t vect_u32; uint64x2_t vect_u64; } __kp_m128i; #define _KP_SIDD_NEGATIVE_POLARITY 0x10 // negate results #define _KP_SIDD_MASKED_NEGATIVE_POLARITY 0x30 // negate results only before end of string static uint16_t g_kp_mask_epi16[8] __attribute__((aligned(16))) = { 0x01, 0x02, 0x04, 0x08, 0x10, 0x20, 0x40, 0x80 }; static uint8_t g_kp_mask_epi8[16] __attribute__((aligned(16))) = { 0x01, 0x02, 0x04, 0x08, 0x10, 0x20, 0x40, 0x80, 0x01, 0x02, 0x04, 0x08, 0x10, 0x20, 0x40, 0x80 }; #define KP_PCMPSTR_EQ_16x8(a, b, mtx) \ { \ mtx[0].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 0)), a.vect_u16); \ mtx[1].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 1)), a.vect_u16); \ mtx[2].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 2)), a.vect_u16); \ mtx[3].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 3)), a.vect_u16); \ mtx[4].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 4)), a.vect_u16); \ mtx[5].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 5)), a.vect_u16); \ mtx[6].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 6)), a.vect_u16); \ mtx[7].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 7)), a.vect_u16); \ } #define KP_PCMPSTR_EQ_8x16(a, b, mtx) \ { \ mtx[0].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 0)), a.vect_u8); \ mtx[1].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 1)), a.vect_u8); \ mtx[2].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 2)), a.vect_u8); \ mtx[3].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 3)), a.vect_u8); \ mtx[4].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 4)), a.vect_u8); \ mtx[5].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 5)), a.vect_u8); \ mtx[6].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 6)), a.vect_u8); \ mtx[7].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 7)), a.vect_u8); \ mtx[8].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 8)), a.vect_u8); \ mtx[9].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 9)), a.vect_u8); \ mtx[10].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 10)), a.vect_u8); \ mtx[11].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 11)), a.vect_u8); \ mtx[12].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 12)), a.vect_u8); \ mtx[13].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 13)), a.vect_u8); \ mtx[14].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 14)), a.vect_u8); \ mtx[15].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 15)), a.vect_u8); \ } #define KP_PCMPSTR_RNG_U16x8(a, b, mtx) \ { \ uint16x8_t vect_b[8]; \ __kp_m128i mask; \ mask.vect_u32 = vdupq_n_u32(0xffff); \ vect_b[0] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 0)); \ vect_b[1] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 1)); \ vect_b[2] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 2)); \ vect_b[3] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 3)); \ vect_b[4] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 4)); \ vect_b[5] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 5)); \ vect_b[6] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 6)); \ vect_b[7] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 7)); \ int i; \ for (i = 0; i < 8; i++) { \ mtx[i].vect_u16 = vbslq_u16(mask.vect_u16, vcgeq_u16(vect_b[i], a.vect_u16), \ vcleq_u16(vect_b[i], a.vect_u16)); \ } \ } #define KP_PCMPSTR_RNG_S16x8(a, b, mtx) \ { \ int16x8_t vect_b[8]; \ __kp_m128i mask; \ mask.vect_u32 = vdupq_n_u32(0xffff); \ vect_b[0] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 0)); \ vect_b[1] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 1)); \ vect_b[2] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 2)); \ vect_b[3] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 3)); \ vect_b[4] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 4)); \ vect_b[5] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 5)); \ vect_b[6] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 6)); \ vect_b[7] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 7)); \ int i; \ for (i = 0; i < 8; i++) { \ mtx[i].vect_u16 = vbslq_u16(mask.vect_u16, vcgeq_s16(vect_b[i], a.vect_s16), \ vcleq_s16(vect_b[i], a.vect_s16)); \ } \ } #define KP_PCMPSTR_RNG_U8x16(a, b, mtx) \ { \ uint8x16_t vect_b[16]; \ __kp_m128i mask; \ mask.vect_u16 = vdupq_n_u16(0xff); \ vect_b[0] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 0)); \ vect_b[1] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 1)); \ vect_b[2] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 2)); \ vect_b[3] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 3)); \ vect_b[4] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 4)); \ vect_b[5] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 5)); \ vect_b[6] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 6)); \ vect_b[7] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 7)); \ vect_b[8] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 8)); \ vect_b[9] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 9)); \ vect_b[10] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 10)); \ vect_b[11] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 11)); \ vect_b[12] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 12)); \ vect_b[13] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 13)); \ vect_b[14] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 14)); \ vect_b[15] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 15)); \ int i; \ for (i = 0; i < 16; i++) { \ mtx[i].vect_u8 = vbslq_u8(mask.vect_u8, vcgeq_u8(vect_b[i], a.vect_u8), vcleq_u8(vect_b[i], a.vect_u8)); \ } \ } #define KP_PCMPSTR_RNG_S8x16(a, b, mtx) \ { \ int8x16_t vect_b[16]; \ __kp_m128i mask; \ mask.vect_u16 = vdupq_n_u16(0xff); \ vect_b[0] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 0)); \ vect_b[1] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 1)); \ vect_b[2] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 2)); \ vect_b[3] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 3)); \ vect_b[4] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 4)); \ vect_b[5] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 5)); \ vect_b[6] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 6)); \ vect_b[7] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 7)); \ vect_b[8] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 8)); \ vect_b[9] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 9)); \ vect_b[10] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 10)); \ vect_b[11] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 11)); \ vect_b[12] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 12)); \ vect_b[13] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 13)); \ vect_b[14] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 14)); \ vect_b[15] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 15)); \ int i; \ for (i = 0; i < 16; i++) { \ mtx[i].vect_u8 = vbslq_u8(mask.vect_u8, vcgeq_s8(vect_b[i], a.vect_s8), vcleq_s8(vect_b[i], a.vect_s8)); \ } \ } static int kp_aggregate_equal_any_8x16(int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j; int m = (1 << la) - 1; uint8x8_t vect_mask = vld1_u8(g_kp_mask_epi8); uint8x8_t t_lo = vtst_u8(vdup_n_u8(m & 0xff), vect_mask); uint8x8_t t_hi = vtst_u8(vdup_n_u8(m >> 8), vect_mask); uint8x16_t vect = vcombine_u8(t_lo, t_hi); for (j = 0; j < lb; j++) { mtx[j].vect_u8 = vandq_u8(vect, mtx[j].vect_u8); mtx[j].vect_u8 = vshrq_n_u8(mtx[j].vect_u8, 7); int tmp = vaddvq_u8(mtx[j].vect_u8) ? 1 : 0; res |= (tmp << j); } return res; } static int kp_aggregate_equal_any_16x8(int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j; int m = (1 << la) - 1; uint16x8_t vect = vtstq_u16(vdupq_n_u16(m), vld1q_u16(g_kp_mask_epi16)); for (j = 0; j < lb; j++) { mtx[j].vect_u16 = vandq_u16(vect, mtx[j].vect_u16); mtx[j].vect_u16 = vshrq_n_u16(mtx[j].vect_u16, 15); int tmp = vaddvq_u16(mtx[j].vect_u16) ? 1 : 0; res |= (tmp << j); } return res; } static int kp_cal_res_byte_equal_any(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_EQ_8x16(a, b, mtx); return kp_aggregate_equal_any_8x16(la, lb, mtx); } static int kp_cal_res_word_equal_any(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_EQ_16x8(a, b, mtx); return kp_aggregate_equal_any_16x8(la, lb, mtx); } static int kp_aggregate_ranges_16x8(int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j; int m = (1 << la) - 1; uint16x8_t vect = vtstq_u16(vdupq_n_u16(m), vld1q_u16(g_kp_mask_epi16)); for (j = 0; j < lb; j++) { mtx[j].vect_u16 = vandq_u16(vect, mtx[j].vect_u16); mtx[j].vect_u16 = vshrq_n_u16(mtx[j].vect_u16, 15); __kp_m128i tmp; tmp.vect_u32 = vshrq_n_u32(mtx[j].vect_u32, 16); uint32x4_t vect_res = vandq_u32(mtx[j].vect_u32, tmp.vect_u32); int t = vaddvq_u32(vect_res) ? 1 : 0; res |= (t << j); } return res; } static int kp_aggregate_ranges_8x16(int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j; int m = (1 << la) - 1; uint8x8_t vect_mask = vld1_u8(g_kp_mask_epi8); uint8x8_t t_lo = vtst_u8(vdup_n_u8(m & 0xff), vect_mask); uint8x8_t t_hi = vtst_u8(vdup_n_u8(m >> 8), vect_mask); uint8x16_t vect = vcombine_u8(t_lo, t_hi); for (j = 0; j < lb; j++) { mtx[j].vect_u8 = vandq_u8(vect, mtx[j].vect_u8); mtx[j].vect_u8 = vshrq_n_u8(mtx[j].vect_u8, 7); __kp_m128i tmp; tmp.vect_u16 = vshrq_n_u16(mtx[j].vect_u16, 8); uint16x8_t vect_res = vandq_u16(mtx[j].vect_u16, tmp.vect_u16); int t = vaddvq_u16(vect_res) ? 1 : 0; res |= (t << j); } return res; } static int kp_cal_res_ubyte_ranges(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_RNG_U8x16(a, b, mtx); return kp_aggregate_ranges_8x16(la, lb, mtx); } static int kp_cal_res_sbyte_ranges(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_RNG_S8x16(a, b, mtx); return kp_aggregate_ranges_8x16(la, lb, mtx); } static int kp_cal_res_uword_ranges(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_RNG_U16x8(a, b, mtx); return kp_aggregate_ranges_16x8(la, lb, mtx); } static int kp_cal_res_sword_ranges(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_RNG_S16x8(a, b, mtx); return kp_aggregate_ranges_16x8(la, lb, mtx); } static int kp_cal_res_byte_equal_each(__kp_m128i a, int la, __kp_m128i b, int lb) { uint8x16_t mtx = vceqq_u8(a.vect_u8, b.vect_u8); int m0 = (la < lb) ? 0 : ((1 << la) - (1 << lb)); int m1 = 0x10000 - (1 << la); int tb = 0x10000 - (1 << lb); uint8x8_t vect_mask, vect0_lo, vect0_hi, vect1_lo, vect1_hi; uint8x8_t tmp_lo, tmp_hi, res_lo, res_hi; vect_mask = vld1_u8(g_kp_mask_epi8); vect0_lo = vtst_u8(vdup_n_u8(m0), vect_mask); vect0_hi = vtst_u8(vdup_n_u8(m0 >> 8), vect_mask); vect1_lo = vtst_u8(vdup_n_u8(m1), vect_mask); vect1_hi = vtst_u8(vdup_n_u8(m1 >> 8), vect_mask); tmp_lo = vtst_u8(vdup_n_u8(tb), vect_mask); tmp_hi = vtst_u8(vdup_n_u8(tb >> 8), vect_mask); res_lo = vbsl_u8(vect0_lo, vdup_n_u8(0), vget_low_u8(mtx)); res_hi = vbsl_u8(vect0_hi, vdup_n_u8(0), vget_high_u8(mtx)); res_lo = vbsl_u8(vect1_lo, tmp_lo, res_lo); res_hi = vbsl_u8(vect1_hi, tmp_hi, res_hi); res_lo = vand_u8(res_lo, vect_mask); res_hi = vand_u8(res_hi, vect_mask); int res = vaddv_u8(res_lo) + (vaddv_u8(res_hi) << 8); return res; } static int kp_cal_res_word_equal_each(__kp_m128i a, int la, __kp_m128i b, int lb) { uint16x8_t mtx = vceqq_u16(a.vect_u16, b.vect_u16); int m0 = (la < lb) ? 0 : ((1 << la) - (1 << lb)); int m1 = 0x100 - (1 << la); int tb = 0x100 - (1 << lb); uint16x8_t vect_mask = vld1q_u16(g_kp_mask_epi16); uint16x8_t vect0 = vtstq_u16(vdupq_n_u16(m0), vect_mask); uint16x8_t vect1 = vtstq_u16(vdupq_n_u16(m1), vect_mask); uint16x8_t tmp = vtstq_u16(vdupq_n_u16(tb), vect_mask); mtx = vbslq_u16(vect0, vdupq_n_u16(0), mtx); mtx = vbslq_u16(vect1, tmp, mtx); mtx = vandq_u16(mtx, vect_mask); return vaddvq_u16(mtx); } static int kp_aggregate_equal_ordered_8x16(int bound, int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j, k; int m1 = 0x10000 - (1 << la); uint8x16_t vect_mask = vld1q_u8(g_kp_mask_epi8); uint8x16_t vect1 = vtstq_u8(vdupq_n_u8(m1), vect_mask); uint8x16_t vect_minusone = vdupq_n_u8(-1); uint8x16_t vect_zero = vdupq_n_u8(0); for (j = 0; j < lb; j++) { mtx[j].vect_u8 = vbslq_u8(vect1, vect_minusone, mtx[j].vect_u8); } for (j = lb; j < bound; j++) { mtx[j].vect_u8 = vbslq_u8(vect1, vect_minusone, vect_zero); } uint8_t enable[16] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1}; for (j = 0; j < bound; j++) { int val = 1; uint8x16_t vect_en = vld1q_u8(enable); for (k = j; k < bound && val == 1; k++) { int t = vaddvq_u8(vandq_u8(mtx[j].vect_u8, vect_en)); val = (t == bound - j) ? 1 : 0; } res = (val << j) + res; enable[bound - 1 - j] = 0; } return res; } static int kp_aggregate_equal_ordered_16x8(int bound, int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j, k; int m1 = 0x100 - (1 << la); uint16x8_t vect_mask = vld1q_u16(g_kp_mask_epi16); uint16x8_t vect1 = vtstq_u16(vdupq_n_u16(m1), vect_mask); uint16x8_t vect_minusone = vdupq_n_u16(-1); uint16x8_t vect_zero = vdupq_n_u16(0); for (j = 0; j < lb; j++) { mtx[j].vect_u16 = vbslq_u16(vect1, vect_minusone, mtx[j].vect_u16); } for (j = lb; j < bound; j++) { mtx[j].vect_u16 = vbslq_u16(vect1, vect_minusone, vect_zero); } uint16_t enable[8] = {1, 1, 1, 1, 1, 1, 1, 1}; for (j = 0; j < bound; j++) { int val = 1; uint16x8_t vect_en = vld1q_u16(enable); for (k = j; k < bound && val == 1; k++) { int t = vaddvq_u16(vandq_u16(mtx[j].vect_u16, vect_en)); val = (t == bound - j) ? 1 : 0; } res = (val << j) + res; enable[bound - 1 - j] = 0; } return res; } static int kp_cal_res_byte_equal_ordered(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_EQ_8x16(a, b, mtx); return kp_aggregate_equal_ordered_8x16(16, la, lb, mtx); } static int kp_cal_res_word_equal_ordered(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_EQ_16x8(a, b, mtx); return kp_aggregate_equal_ordered_16x8(8, la, lb, mtx); } typedef enum { KP_CMP_UBYTE_EQUAL_ANY, KP_CMP_UWORD_EQUAL_ANY, KP_CMP_SBYTE_EQUAL_ANY, KP_CMP_SWORD_EQUAL_ANY, KP_CMP_UBYTE_RANGES, KP_CMP_UWORD_RANGES, KP_CMP_SBYTE_RANGES, KP_CMP_SWORD_RANGES, KP_CMP_UBYTE_EQUAL_EACH, KP_CMP_UWORD_EQUAL_EACH, KP_CMP_SBYTE_EQUAL_EACH, KP_CMP_SWORD_EQUAL_EACH, KP_CMP_UBYTE_EQUAL_ORDERED, KP_CMP_UWORD_EQUAL_ORDERED, KP_CMP_SBYTE_EQUAL_ORDERED, KP_CMP_SWORD_EQUAL_ORDERED } _KP_MM_CMPESTR_ENUM; typedef int (*KP_CMPESTR)(__kp_m128i a, int la, __kp_m128i b, int lb); typedef struct { _KP_MM_CMPESTR_ENUM cmpintEnum; KP_CMPESTR cmpFun; } KP_CmpestrFuncList; static KP_CmpestrFuncList g_kp_cmpestrFuncList[] = {{KP_CMP_UBYTE_EQUAL_ANY, kp_cal_res_byte_equal_any}, {KP_CMP_UWORD_EQUAL_ANY, kp_cal_res_word_equal_any}, {KP_CMP_SBYTE_EQUAL_ANY, kp_cal_res_byte_equal_any}, {KP_CMP_SWORD_EQUAL_ANY, kp_cal_res_word_equal_any}, {KP_CMP_UBYTE_RANGES, kp_cal_res_ubyte_ranges}, {KP_CMP_UWORD_RANGES, kp_cal_res_uword_ranges}, {KP_CMP_SBYTE_RANGES, kp_cal_res_sbyte_ranges}, {KP_CMP_SWORD_RANGES, kp_cal_res_sword_ranges}, {KP_CMP_UBYTE_EQUAL_EACH, kp_cal_res_byte_equal_each}, {KP_CMP_UWORD_EQUAL_EACH, kp_cal_res_word_equal_each}, {KP_CMP_SBYTE_EQUAL_EACH, kp_cal_res_byte_equal_each}, {KP_CMP_SWORD_EQUAL_EACH, kp_cal_res_word_equal_each}, {KP_CMP_UBYTE_EQUAL_ORDERED, kp_cal_res_byte_equal_ordered}, {KP_CMP_UWORD_EQUAL_ORDERED, kp_cal_res_word_equal_ordered}, {KP_CMP_SBYTE_EQUAL_ORDERED, kp_cal_res_byte_equal_ordered}, {KP_CMP_SWORD_EQUAL_ORDERED, kp_cal_res_word_equal_ordered}}; KP_FORCE_INLINE int kp_neg_fun(int res, int lb, int imm8, int bound) { int m; switch (imm8 & 0x30) { case _KP_SIDD_NEGATIVE_POLARITY: res ^= 0xffffffff; break; case _KP_SIDD_MASKED_NEGATIVE_POLARITY: m = (1 << lb) - 1; res ^= m; break; default: break; } return res & ((bound == 8) ? 0xFF : 0xFFFF); } int __remill_simd__mm_cmpestri(__kp_m128i a, int la, __kp_m128i b, int lb, const int imm8, int *intRes2); __kp_m128i __remill_simd__mm_cmpestrm(__kp_m128i a, int la, __kp_m128i b, int lb, const int imm8, int *intRes2); #endif // KUNPENG_TRANS_H - 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 执行以下命令创建“KunpengTrans.cpp”文件。
- 创建“KunpengTrans.cpp”文件。
- 按“i”进入编辑模式,添加如下内容。
/* * @Description: KunpengTrans.h * @Copyright (c) Huawei Technologies Co., Ltd. 2020-2020. All rights reserved. */ #ifndef KUNPENG_TRANS_H #define KUNPENG_TRANS_H #include <string.h> #include <KunpengTrans.h> /* ATTENTION: * Please set KUNPENG_CPU_FREQUENCY_MHZ to the actual cpu frequecy of your running environment. */ const int KUNPENG_CPU_FREQUENCY_MHZ = 2600; const int EAX_LEAF = 7; const int SHIFT_THREE = 3; /* CASE eax = 0; Highest Function Parameter and Manufacturer ID */ void GetCPUManuID(unsigned int *ebx, unsigned int *edx, unsigned int *ecx) { // ID str = "KunpengHisil" char b_str[] = "Kunp"; char d_str[] = "engH"; char c_str[] = "isil"; *ebx = *(unsigned int *)b_str; *edx = *(unsigned int *)d_str; *ecx = *(unsigned int *)c_str; } // %ecx #define bit_SSE3 (1 << 0) #define bit_PCLMUL (1 << 1) #define bit_LZCNT (1 << 5) #define bit_SSSE3 (1 << 9) #define bit_FMA (1 << 12) #define bit_CMPXCHG16B (1 << 13) #define bit_SSE4_1 (1 << 19) #define bit_SSE4_2 (1 << 20) #define bit_MOVBE (1 << 22) #define bit_POPCNT (1 << 23) #define bit_AES (1 << 25) #define bit_XSAVE (1 << 26) #define bit_OSXSAVE (1 << 27) #define bit_AVX (1 << 28) #define bit_F16C (1 << 29) #define bit_RDRND (1 << 30) // %edx #define bit_CMPXCHG8B (1 << 8) #define bit_CMOV (1 << 15) #define bit_MMX (1 << 23) #define bit_FXSAVE (1 << 24) #define bit_SSE (1 << 25) #define bit_SSE2 (1 << 26) /* CASE eax = 1; Processor Info and Feature Bits * Skylake: eax = 0x00050654, ebx = 0x43400800, ecx = 0x7ffefbf7, edx = 0xbfebfbff (采样于6148) * Cascade Lake : eax = 0x00050657, ebx = 0x08400800, ecx = 0x7ffefbf7, edx = 0xbfebfbff (采样于6248) */ void GetCPUFeature(unsigned int *eax, unsigned int *ebx, unsigned int *ecx, unsigned int *edx) { *eax = 0x0; // Processor Info not defined in kunpeng; *ebx = 0x0; // Additional Info not defined in kunpeng; *ecx = bit_SSE3 | bit_LZCNT | bit_SSSE3 | bit_SSE4_1 | bit_SSE4_2 | bit_POPCNT; *edx = bit_MMX | bit_SSE | bit_SSE2; } /* %ebx */ #define bit_FSGSBASE (1 << 0) #define bit_SGX (1 << 2) #define bit_BMI (1 << 3) #define bit_HLE (1 << 4) #define bit_AVX2 (1 << 5) #define bit_BMI2 (1 << 8) #define bit_RTM (1 << 11) #define bit_MPX (1 << 14) #define bit_AVX512F (1 << 16) #define bit_AVX512DQ (1 << 17) #define bit_RDSEED (1 << 18) #define bit_ADX (1 << 19) #define bit_AVX512IFMA (1 << 21) #define bit_CLFLUSHOPT (1 << 23) #define bit_CLWB (1 << 24) #define bit_AVX512PF (1 << 26) #define bit_AVX512ER (1 << 27) #define bit_AVX512CD (1 << 28) #define bit_SHA (1 << 29) #define bit_AVX512BW (1 << 30) #define bit_AVX512VL (1u << 31) /* %ecx */ #define bit_PREFETCHWT1 (1 << 0) #define bit_AVX512VBMI (1 << 1) #define bit_PKU (1 << 3) #define bit_OSPKE (1 << 4) #define bit_AVX512VBMI2 (1 << 6) #define bit_SHSTK (1 << 7) #define bit_GFNI (1 << 8) #define bit_VAES (1 << 9) #define bit_AVX512VNNI (1 << 11) #define bit_VPCLMULQDQ (1 << 10) #define bit_AVX512BITALG (1 << 12) #define bit_AVX512VPOPCNTDQ (1 << 14) #define bit_RDPID (1 << 22) #define bit_MOVDIRI (1 << 27) #define bit_MOVDIR64B (1 << 28) /* %edx */ #define bit_AVX5124VNNIW (1 << 2) #define bit_AVX5124FMAPS (1 << 3) #define bit_IBT (1 << 20) #define bit_PCONFIG (1 << 18) /* CASE eax = 7, ecx = 0; Extended Features * Skylake: eax = 0x00000000, ebx = 0xd39ffffb, ecx = 0x00000018, edx = 0x9c002400 (采样于6148) * Cascade Lake : eax = 0x00000000, ebx = 0xd39ffffb, ecx = 0x00000818, edx = 0xbc000400 (采样于6248) */ void GetExtendCPUFeature(unsigned int *eax, unsigned int *ebx, unsigned int *ecx, unsigned int *edx) { *eax = 0x0; *ebx = 0x0; *ecx = 0x0; *edx = 0x0; } /* * GetSupportedCPUID only supported while eax = 0, eax = 1 , eax = 7 and ecx = 0 * In other cases always return 0x0; * chipID support 1,2 -- 1 for skylake server eg. 6148; 2 for Cascade Lake 6248 */ void GetSupportedCPUID(unsigned int *eax, unsigned int *ebx, unsigned int *ecx, unsigned int *edx) { unsigned int leaf = *eax; unsigned int count = *ecx; if (leaf == 0) { *eax = 0x7; GetCPUManuID(ebx, edx, ecx); } else if (leaf == 1) { GetCPUFeature(eax, ebx, ecx, edx); } else if (leaf == EAX_LEAF && count == 0) { GetExtendCPUFeature(eax, ebx, ecx, edx); } else { *eax = 0x0; *ebx = 0x0; *ecx = 0x0; *edx = 0x0; } } void RepStos(void *dest, unsigned long long src, unsigned long long len, unsigned width, int df) { unsigned n = width >> SHIFT_THREE; unsigned char *d = (unsigned char *)dest; unsigned i; unsigned j; if (df == 1) { for (i = 0; i < len; i++) { for (j = 0; j < n; j++) { d[j] = src >> (j << SHIFT_THREE); } d -= n; } } else { for (i = 0; i < len; i++) { for (j = 0; j < n; j++) { d[j] = src >> (j << SHIFT_THREE); } d += n; } } return; } void RepStosB(void *dest, unsigned long long src, unsigned long long len, int DF) { unsigned char *s = (unsigned char *)dest; unsigned char *e = (unsigned char *)dest; if (DF) { s = s - len; } else { e = e + len; } while (s < e) { *s++ = src; } } void RepStosW(void *dest, unsigned long long src, unsigned long long len, int DF) { unsigned short *s = (unsigned short *)dest; unsigned short *e = (unsigned short *)dest; if (DF) { s = s - len; } else { e = e + len; } while (s < e) { *s++ = src; } } void RepStosD(void *dest, unsigned long long src, unsigned long long len, int DF) { unsigned int *s = (unsigned int *)dest; unsigned int *e = (unsigned int *)dest; if (DF) { s = s - len; } else { e = e + len; } while (s < e) { *s++ = src; } } void RepStosQ(void *dest, unsigned long long src, unsigned long long len, int DF) { unsigned long long *s = (unsigned long long *)dest; unsigned long long *e = (unsigned long long *)dest; if (DF) { s = s - len; } else { e = e + len; } while (s < e) { *s++ = src; } } void RepMovs(void *dest, void *src, unsigned long long len, unsigned width, int df) { unsigned n = len * (width >> SHIFT_THREE); char *d = NULL; char *s = NULL; if (df == 1) { d = (char *)dest - (n - 1); s = (char *)src - (n - 1); } else { d = (char *)dest; s = (char *)src; } memcpy(d, s, n); // 非安全函数, 如有需要,请修改为安全函数 return; } #include <arm_neon.h> #define KP_FORCE_INLINE static inline __attribute__((always_inline)) typedef union { int8x16_t vect_s8; int16x8_t vect_s16; int32x4_t vect_s32; int64x2_t vect_s64; uint8x16_t vect_u8; uint16x8_t vect_u16; uint32x4_t vect_u32; uint64x2_t vect_u64; } __kp_m128i; #define _KP_SIDD_NEGATIVE_POLARITY 0x10 // negate results #define _KP_SIDD_MASKED_NEGATIVE_POLARITY 0x30 // negate results only before end of string static uint16_t g_kp_mask_epi16[8] __attribute__((aligned(16))) = { 0x01, 0x02, 0x04, 0x08, 0x10, 0x20, 0x40, 0x80 }; static uint8_t g_kp_mask_epi8[16] __attribute__((aligned(16))) = { 0x01, 0x02, 0x04, 0x08, 0x10, 0x20, 0x40, 0x80, 0x01, 0x02, 0x04, 0x08, 0x10, 0x20, 0x40, 0x80 }; #define KP_PCMPSTR_EQ_16x8(a, b, mtx) \ { \ mtx[0].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 0)), a.vect_u16); \ mtx[1].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 1)), a.vect_u16); \ mtx[2].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 2)), a.vect_u16); \ mtx[3].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 3)), a.vect_u16); \ mtx[4].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 4)), a.vect_u16); \ mtx[5].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 5)), a.vect_u16); \ mtx[6].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 6)), a.vect_u16); \ mtx[7].vect_u16 = vceqq_u16(vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 7)), a.vect_u16); \ } #define KP_PCMPSTR_EQ_8x16(a, b, mtx) \ { \ mtx[0].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 0)), a.vect_u8); \ mtx[1].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 1)), a.vect_u8); \ mtx[2].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 2)), a.vect_u8); \ mtx[3].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 3)), a.vect_u8); \ mtx[4].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 4)), a.vect_u8); \ mtx[5].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 5)), a.vect_u8); \ mtx[6].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 6)), a.vect_u8); \ mtx[7].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 7)), a.vect_u8); \ mtx[8].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 8)), a.vect_u8); \ mtx[9].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 9)), a.vect_u8); \ mtx[10].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 10)), a.vect_u8); \ mtx[11].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 11)), a.vect_u8); \ mtx[12].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 12)), a.vect_u8); \ mtx[13].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 13)), a.vect_u8); \ mtx[14].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 14)), a.vect_u8); \ mtx[15].vect_u8 = vceqq_u8(vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 15)), a.vect_u8); \ } #define KP_PCMPSTR_RNG_U16x8(a, b, mtx) \ { \ uint16x8_t vect_b[8]; \ __kp_m128i mask; \ mask.vect_u32 = vdupq_n_u32(0xffff); \ vect_b[0] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 0)); \ vect_b[1] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 1)); \ vect_b[2] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 2)); \ vect_b[3] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 3)); \ vect_b[4] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 4)); \ vect_b[5] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 5)); \ vect_b[6] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 6)); \ vect_b[7] = vdupq_n_u16(vgetq_lane_u16(b.vect_u16, 7)); \ int i; \ for (i = 0; i < 8; i++) { \ mtx[i].vect_u16 = vbslq_u16(mask.vect_u16, vcgeq_u16(vect_b[i], a.vect_u16), \ vcleq_u16(vect_b[i], a.vect_u16)); \ } \ } #define KP_PCMPSTR_RNG_S16x8(a, b, mtx) \ { \ int16x8_t vect_b[8]; \ __kp_m128i mask; \ mask.vect_u32 = vdupq_n_u32(0xffff); \ vect_b[0] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 0)); \ vect_b[1] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 1)); \ vect_b[2] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 2)); \ vect_b[3] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 3)); \ vect_b[4] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 4)); \ vect_b[5] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 5)); \ vect_b[6] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 6)); \ vect_b[7] = vdupq_n_s16(vgetq_lane_s16(b.vect_s16, 7)); \ int i; \ for (i = 0; i < 8; i++) { \ mtx[i].vect_u16 = vbslq_u16(mask.vect_u16, vcgeq_s16(vect_b[i], a.vect_s16), \ vcleq_s16(vect_b[i], a.vect_s16)); \ } \ } #define KP_PCMPSTR_RNG_U8x16(a, b, mtx) \ { \ uint8x16_t vect_b[16]; \ __kp_m128i mask; \ mask.vect_u16 = vdupq_n_u16(0xff); \ vect_b[0] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 0)); \ vect_b[1] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 1)); \ vect_b[2] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 2)); \ vect_b[3] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 3)); \ vect_b[4] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 4)); \ vect_b[5] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 5)); \ vect_b[6] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 6)); \ vect_b[7] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 7)); \ vect_b[8] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 8)); \ vect_b[9] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 9)); \ vect_b[10] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 10)); \ vect_b[11] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 11)); \ vect_b[12] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 12)); \ vect_b[13] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 13)); \ vect_b[14] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 14)); \ vect_b[15] = vdupq_n_u8(vgetq_lane_u8(b.vect_u8, 15)); \ int i; \ for (i = 0; i < 16; i++) { \ mtx[i].vect_u8 = vbslq_u8(mask.vect_u8, vcgeq_u8(vect_b[i], a.vect_u8), vcleq_u8(vect_b[i], a.vect_u8)); \ } \ } #define KP_PCMPSTR_RNG_S8x16(a, b, mtx) \ { \ int8x16_t vect_b[16]; \ __kp_m128i mask; \ mask.vect_u16 = vdupq_n_u16(0xff); \ vect_b[0] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 0)); \ vect_b[1] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 1)); \ vect_b[2] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 2)); \ vect_b[3] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 3)); \ vect_b[4] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 4)); \ vect_b[5] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 5)); \ vect_b[6] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 6)); \ vect_b[7] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 7)); \ vect_b[8] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 8)); \ vect_b[9] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 9)); \ vect_b[10] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 10)); \ vect_b[11] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 11)); \ vect_b[12] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 12)); \ vect_b[13] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 13)); \ vect_b[14] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 14)); \ vect_b[15] = vdupq_n_s8(vgetq_lane_s8(b.vect_s8, 15)); \ int i; \ for (i = 0; i < 16; i++) { \ mtx[i].vect_u8 = vbslq_u8(mask.vect_u8, vcgeq_s8(vect_b[i], a.vect_s8), vcleq_s8(vect_b[i], a.vect_s8)); \ } \ } static int kp_aggregate_equal_any_8x16(int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j; int m = (1 << la) - 1; uint8x8_t vect_mask = vld1_u8(g_kp_mask_epi8); uint8x8_t t_lo = vtst_u8(vdup_n_u8(m & 0xff), vect_mask); uint8x8_t t_hi = vtst_u8(vdup_n_u8(m >> 8), vect_mask); uint8x16_t vect = vcombine_u8(t_lo, t_hi); for (j = 0; j < lb; j++) { mtx[j].vect_u8 = vandq_u8(vect, mtx[j].vect_u8); mtx[j].vect_u8 = vshrq_n_u8(mtx[j].vect_u8, 7); int tmp = vaddvq_u8(mtx[j].vect_u8) ? 1 : 0; res |= (tmp << j); } return res; } static int kp_aggregate_equal_any_16x8(int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j; int m = (1 << la) - 1; uint16x8_t vect = vtstq_u16(vdupq_n_u16(m), vld1q_u16(g_kp_mask_epi16)); for (j = 0; j < lb; j++) { mtx[j].vect_u16 = vandq_u16(vect, mtx[j].vect_u16); mtx[j].vect_u16 = vshrq_n_u16(mtx[j].vect_u16, 15); int tmp = vaddvq_u16(mtx[j].vect_u16) ? 1 : 0; res |= (tmp << j); } return res; } static int kp_cal_res_byte_equal_any(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_EQ_8x16(a, b, mtx); return kp_aggregate_equal_any_8x16(la, lb, mtx); } static int kp_cal_res_word_equal_any(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_EQ_16x8(a, b, mtx); return kp_aggregate_equal_any_16x8(la, lb, mtx); } static int kp_aggregate_ranges_16x8(int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j; int m = (1 << la) - 1; uint16x8_t vect = vtstq_u16(vdupq_n_u16(m), vld1q_u16(g_kp_mask_epi16)); for (j = 0; j < lb; j++) { mtx[j].vect_u16 = vandq_u16(vect, mtx[j].vect_u16); mtx[j].vect_u16 = vshrq_n_u16(mtx[j].vect_u16, 15); __kp_m128i tmp; tmp.vect_u32 = vshrq_n_u32(mtx[j].vect_u32, 16); uint32x4_t vect_res = vandq_u32(mtx[j].vect_u32, tmp.vect_u32); int t = vaddvq_u32(vect_res) ? 1 : 0; res |= (t << j); } return res; } static int kp_aggregate_ranges_8x16(int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j; int m = (1 << la) - 1; uint8x8_t vect_mask = vld1_u8(g_kp_mask_epi8); uint8x8_t t_lo = vtst_u8(vdup_n_u8(m & 0xff), vect_mask); uint8x8_t t_hi = vtst_u8(vdup_n_u8(m >> 8), vect_mask); uint8x16_t vect = vcombine_u8(t_lo, t_hi); for (j = 0; j < lb; j++) { mtx[j].vect_u8 = vandq_u8(vect, mtx[j].vect_u8); mtx[j].vect_u8 = vshrq_n_u8(mtx[j].vect_u8, 7); __kp_m128i tmp; tmp.vect_u16 = vshrq_n_u16(mtx[j].vect_u16, 8); uint16x8_t vect_res = vandq_u16(mtx[j].vect_u16, tmp.vect_u16); int t = vaddvq_u16(vect_res) ? 1 : 0; res |= (t << j); } return res; } static int kp_cal_res_ubyte_ranges(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_RNG_U8x16(a, b, mtx); return kp_aggregate_ranges_8x16(la, lb, mtx); } static int kp_cal_res_sbyte_ranges(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_RNG_S8x16(a, b, mtx); return kp_aggregate_ranges_8x16(la, lb, mtx); } static int kp_cal_res_uword_ranges(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_RNG_U16x8(a, b, mtx); return kp_aggregate_ranges_16x8(la, lb, mtx); } static int kp_cal_res_sword_ranges(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_RNG_S16x8(a, b, mtx); return kp_aggregate_ranges_16x8(la, lb, mtx); } static int kp_cal_res_byte_equal_each(__kp_m128i a, int la, __kp_m128i b, int lb) { uint8x16_t mtx = vceqq_u8(a.vect_u8, b.vect_u8); int m0 = (la < lb) ? 0 : ((1 << la) - (1 << lb)); int m1 = 0x10000 - (1 << la); int tb = 0x10000 - (1 << lb); uint8x8_t vect_mask, vect0_lo, vect0_hi, vect1_lo, vect1_hi; uint8x8_t tmp_lo, tmp_hi, res_lo, res_hi; vect_mask = vld1_u8(g_kp_mask_epi8); vect0_lo = vtst_u8(vdup_n_u8(m0), vect_mask); vect0_hi = vtst_u8(vdup_n_u8(m0 >> 8), vect_mask); vect1_lo = vtst_u8(vdup_n_u8(m1), vect_mask); vect1_hi = vtst_u8(vdup_n_u8(m1 >> 8), vect_mask); tmp_lo = vtst_u8(vdup_n_u8(tb), vect_mask); tmp_hi = vtst_u8(vdup_n_u8(tb >> 8), vect_mask); res_lo = vbsl_u8(vect0_lo, vdup_n_u8(0), vget_low_u8(mtx)); res_hi = vbsl_u8(vect0_hi, vdup_n_u8(0), vget_high_u8(mtx)); res_lo = vbsl_u8(vect1_lo, tmp_lo, res_lo); res_hi = vbsl_u8(vect1_hi, tmp_hi, res_hi); res_lo = vand_u8(res_lo, vect_mask); res_hi = vand_u8(res_hi, vect_mask); int res = vaddv_u8(res_lo) + (vaddv_u8(res_hi) << 8); return res; } static int kp_cal_res_word_equal_each(__kp_m128i a, int la, __kp_m128i b, int lb) { uint16x8_t mtx = vceqq_u16(a.vect_u16, b.vect_u16); int m0 = (la < lb) ? 0 : ((1 << la) - (1 << lb)); int m1 = 0x100 - (1 << la); int tb = 0x100 - (1 << lb); uint16x8_t vect_mask = vld1q_u16(g_kp_mask_epi16); uint16x8_t vect0 = vtstq_u16(vdupq_n_u16(m0), vect_mask); uint16x8_t vect1 = vtstq_u16(vdupq_n_u16(m1), vect_mask); uint16x8_t tmp = vtstq_u16(vdupq_n_u16(tb), vect_mask); mtx = vbslq_u16(vect0, vdupq_n_u16(0), mtx); mtx = vbslq_u16(vect1, tmp, mtx); mtx = vandq_u16(mtx, vect_mask); return vaddvq_u16(mtx); } static int kp_aggregate_equal_ordered_8x16(int bound, int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j, k; int m1 = 0x10000 - (1 << la); uint8x16_t vect_mask = vld1q_u8(g_kp_mask_epi8); uint8x16_t vect1 = vtstq_u8(vdupq_n_u8(m1), vect_mask); uint8x16_t vect_minusone = vdupq_n_u8(-1); uint8x16_t vect_zero = vdupq_n_u8(0); for (j = 0; j < lb; j++) { mtx[j].vect_u8 = vbslq_u8(vect1, vect_minusone, mtx[j].vect_u8); } for (j = lb; j < bound; j++) { mtx[j].vect_u8 = vbslq_u8(vect1, vect_minusone, vect_zero); } uint8_t enable[16] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1}; for (j = 0; j < bound; j++) { int val = 1; uint8x16_t vect_en = vld1q_u8(enable); for (k = j; k < bound && val == 1; k++) { int t = vaddvq_u8(vandq_u8(mtx[j].vect_u8, vect_en)); val = (t == bound - j) ? 1 : 0; } res = (val << j) + res; enable[bound - 1 - j] = 0; } return res; } static int kp_aggregate_equal_ordered_16x8(int bound, int la, int lb, __kp_m128i mtx[16]) { int res = 0; int j, k; int m1 = 0x100 - (1 << la); uint16x8_t vect_mask = vld1q_u16(g_kp_mask_epi16); uint16x8_t vect1 = vtstq_u16(vdupq_n_u16(m1), vect_mask); uint16x8_t vect_minusone = vdupq_n_u16(-1); uint16x8_t vect_zero = vdupq_n_u16(0); for (j = 0; j < lb; j++) { mtx[j].vect_u16 = vbslq_u16(vect1, vect_minusone, mtx[j].vect_u16); } for (j = lb; j < bound; j++) { mtx[j].vect_u16 = vbslq_u16(vect1, vect_minusone, vect_zero); } uint16_t enable[8] = {1, 1, 1, 1, 1, 1, 1, 1}; for (j = 0; j < bound; j++) { int val = 1; uint16x8_t vect_en = vld1q_u16(enable); for (k = j; k < bound && val == 1; k++) { int t = vaddvq_u16(vandq_u16(mtx[j].vect_u16, vect_en)); val = (t == bound - j) ? 1 : 0; } res = (val << j) + res; enable[bound - 1 - j] = 0; } return res; } static int kp_cal_res_byte_equal_ordered(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_EQ_8x16(a, b, mtx); return kp_aggregate_equal_ordered_8x16(16, la, lb, mtx); } static int kp_cal_res_word_equal_ordered(__kp_m128i a, int la, __kp_m128i b, int lb) { __kp_m128i mtx[16]; KP_PCMPSTR_EQ_16x8(a, b, mtx); return kp_aggregate_equal_ordered_16x8(8, la, lb, mtx); } typedef enum { KP_CMP_UBYTE_EQUAL_ANY, KP_CMP_UWORD_EQUAL_ANY, KP_CMP_SBYTE_EQUAL_ANY, KP_CMP_SWORD_EQUAL_ANY, KP_CMP_UBYTE_RANGES, KP_CMP_UWORD_RANGES, KP_CMP_SBYTE_RANGES, KP_CMP_SWORD_RANGES, KP_CMP_UBYTE_EQUAL_EACH, KP_CMP_UWORD_EQUAL_EACH, KP_CMP_SBYTE_EQUAL_EACH, KP_CMP_SWORD_EQUAL_EACH, KP_CMP_UBYTE_EQUAL_ORDERED, KP_CMP_UWORD_EQUAL_ORDERED, KP_CMP_SBYTE_EQUAL_ORDERED, KP_CMP_SWORD_EQUAL_ORDERED } _KP_MM_CMPESTR_ENUM; typedef int (*KP_CMPESTR)(__kp_m128i a, int la, __kp_m128i b, int lb); typedef struct { _KP_MM_CMPESTR_ENUM cmpintEnum; KP_CMPESTR cmpFun; } KP_CmpestrFuncList; static KP_CmpestrFuncList g_kp_cmpestrFuncList[] = {{KP_CMP_UBYTE_EQUAL_ANY, kp_cal_res_byte_equal_any}, {KP_CMP_UWORD_EQUAL_ANY, kp_cal_res_word_equal_any}, {KP_CMP_SBYTE_EQUAL_ANY, kp_cal_res_byte_equal_any}, {KP_CMP_SWORD_EQUAL_ANY, kp_cal_res_word_equal_any}, {KP_CMP_UBYTE_RANGES, kp_cal_res_ubyte_ranges}, {KP_CMP_UWORD_RANGES, kp_cal_res_uword_ranges}, {KP_CMP_SBYTE_RANGES, kp_cal_res_sbyte_ranges}, {KP_CMP_SWORD_RANGES, kp_cal_res_sword_ranges}, {KP_CMP_UBYTE_EQUAL_EACH, kp_cal_res_byte_equal_each}, {KP_CMP_UWORD_EQUAL_EACH, kp_cal_res_word_equal_each}, {KP_CMP_SBYTE_EQUAL_EACH, kp_cal_res_byte_equal_each}, {KP_CMP_SWORD_EQUAL_EACH, kp_cal_res_word_equal_each}, {KP_CMP_UBYTE_EQUAL_ORDERED, kp_cal_res_byte_equal_ordered}, {KP_CMP_UWORD_EQUAL_ORDERED, kp_cal_res_word_equal_ordered}, {KP_CMP_SBYTE_EQUAL_ORDERED, kp_cal_res_byte_equal_ordered}, {KP_CMP_SWORD_EQUAL_ORDERED, kp_cal_res_word_equal_ordered}}; KP_FORCE_INLINE int kp_neg_fun(int res, int lb, int imm8, int bound) { int m; switch (imm8 & 0x30) { case _KP_SIDD_NEGATIVE_POLARITY: res ^= 0xffffffff; break; case _KP_SIDD_MASKED_NEGATIVE_POLARITY: m = (1 << lb) - 1; res ^= m; break; default: break; } return res & ((bound == 8) ? 0xFF : 0xFFFF); } int __remill_simd__mm_cmpestri(__kp_m128i a, int la, __kp_m128i b, int lb, const int imm8, int *intRes2) { int bound = (imm8 & 0x01) ? 8 : 16; __asm__ __volatile__ ( "eor w0, %w[a], %w[a], asr31 \n\t" "sub %w[a], w0, %w[a], asr31 \n\t" "eor w1, %w[b], %w[b], asr31 \n\t" "sub %w[b], w1, %w[b], asr31 \n\t" "cmp %w[a], %w[bd] \n\t" "csel %w[a], %w[bd], %w[a], gt \n\t" "cmp %w[b], %w[bd] \n\t" "csel %w[b], %w[bd], %w[b], gt \n\t" :[a]"+r"(la), [b]"+r"(lb) :[bd]"r"(bound) :"w0", "w1"); int r2 = g_kp_cmpestrFuncList[imm8 & 0x0f].cmpFun(a, la, b, lb); r2 = kp_neg_fun(r2, lb, imm8, bound); *intRes2 = r2; return (r2 == 0) ? bound : ((imm8 & 0x40) ? (31 - __builtin_clz(r2)) : __builtin_ctz(r2)); } __kp_m128i __remill_simd__mm_cmpestrm(__kp_m128i a, int la, __kp_m128i b, int lb, const int imm8, int *intRes2) { __kp_m128i dst; int bound = (imm8 & 0x01) ? 8 : 16; __asm__ __volatile__ ( "eor w0, %w[a], %w[a], asr31 \n\t" "sub %w[a], w0, %w[a], asr31 \n\t" "eor w1, %w[b], %w[b], asr31 \n\t" "sub %w[b], w1, %w[b], asr31 \n\t" "cmp %w[a], %w[bd] \n\t" "csel %w[a], %w[bd], %w[a], gt \n\t" "cmp %w[b], %w[bd] \n\t" "csel %w[b], %w[bd], %w[b], gt \n\t" :[a]"+r"(la), [b]"+r"(lb) :[bd]"r"(bound) :"w0", "w1"); int r2 = g_kp_cmpestrFuncList[imm8 & 0x0f].cmpFun(a, la, b, lb); r2 = kp_neg_fun(r2, lb, imm8, bound); *intRes2 = r2; dst.vect_u8 = vdupq_n_u8(0); if (imm8 & 0x40) { if (bound == 8) { uint16x8_t tmp = vtstq_u16(vdupq_n_u16(r2), vld1q_u16(g_kp_mask_epi16)); dst.vect_u16 = vbslq_u16(tmp, vdupq_n_u16(-1), dst.vect_u16); } else { uint8x16_t vect_r2 = vcombine_u8(vdup_n_u8(r2), vdup_n_u8(r2 >> 8)); uint8x16_t tmp = vtstq_u8(vect_r2, vld1q_u8(g_kp_mask_epi8)); dst.vect_u8 = vbslq_u8(tmp, vdupq_n_u8(-1), dst.vect_u8); } } else { if (bound == 16) { dst.vect_u16 = vsetq_lane_u16(r2 & 0xffff, dst.vect_u16, 0); } else { dst.vect_u8 = vsetq_lane_u8(r2 & 0xff, dst.vect_u8, 0); } } return dst; } #endif // KUNPENG_TRANS_H - 按“Esc”键,输入:wq!,按“Enter”保存并退出编辑。
- 将“KunpengTrans.h”和“KunpengTrans.cpp”上传到Muscle源码的“src”目录。
- 执行以下命令进行编译。
make
编译成功后,可执行文件生成在“/muscle/src/o”目录下。