多副本
Ceph分布式存储采用数据多副本备份机制来保证数据的可靠性,默认保存为3个副本(可修改)。Ceph采用
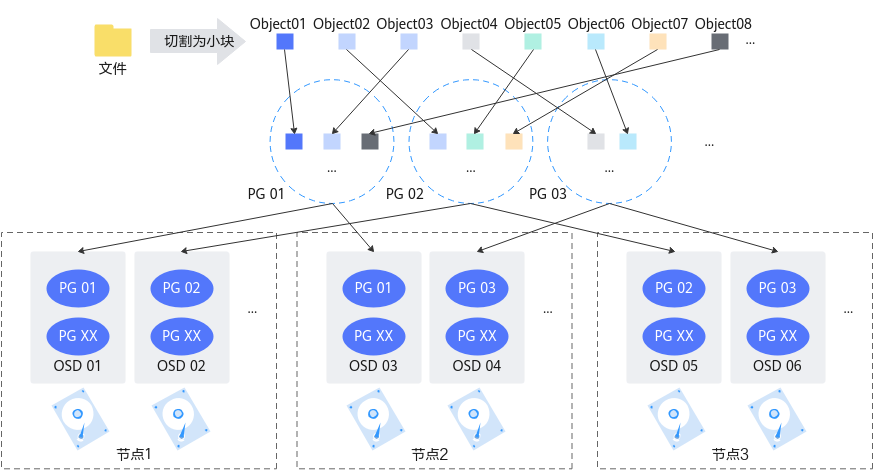
- 当用户要将数据存储到Ceph集群时,数据先被分割成多个object(每个object一个object id,大小可设置,默认是4MB),object是Ceph存储的最小存储单元。
- 由于object的数量很多,为了有效减少object到OSD的索引表、降低元数据的复杂度,使得写入和读取更加灵活,引入了PG(Placement Group):PG用来管理object,每个object通过Hash,映射到某个pg中,一个PG可以包含多个object。
- PG再通过CRUSH计算,映射到OSD中。如果是三副本的,则每个pg都会映射到三个OSD,保证了数据的冗余。
图1 CRUSH算法资源划分示意图(以2副本为例)
CRUSH算法并不是绝对不变的,会受其他因素影响,影响因素主要有:
- 当前系统状态(Cluster Map)
- 存储策略配置(存储策略主要与数据安全相关)
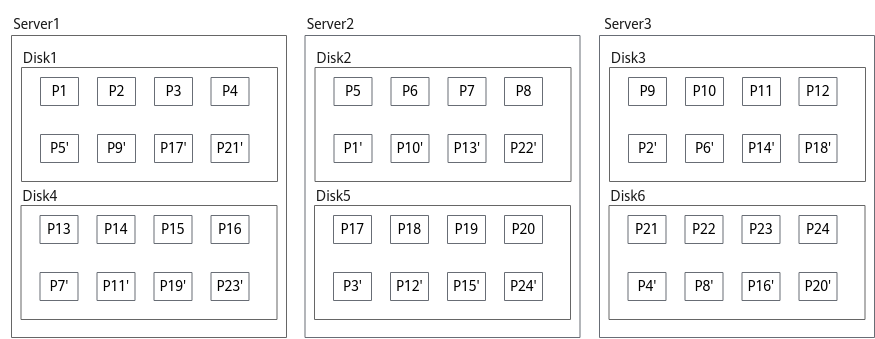
通过策略可以指定同一个PG的3个OSD分别位于数据中心的不同服务器甚至不同机柜上,从而更加完善存储的可靠性。
如图2所示,对于节点Server1的磁盘Disk1上的数据块P1,它的数据备份为节点Server2的磁盘Disk2上P1',P1和P1'构成了同一个数据块的两个副本。例如,当P1所在的硬盘故障时,P1'可以继续提供存储服务。
父主题: 公共特性