鲲鹏BoostKit应用加速
鲲鹏BoostKit提供性能倍增的应用加速软件包,使能数据处理极致性能、数据访问极致高效和云手机极致体验。
鲲鹏BoostKit应用加速软件包,详细介绍与最新内容请参见鲲鹏应用使能套件BoostKit -> 应用加速软件包。
云手机
鲲鹏BoostKit云手机利用ARM指令集同构优势,支持移动应用无损上云,同时将多年技术积累浓缩到Kbox云手机容器、指令流引擎、视频流引擎核心能力等组件,形成了云手机Turbo套件,降低了开发难度,提升整机的密度,降低云手机单路成本,其中HostOS支持Ubuntu和openEuler,GuestOS支持android-9.0.0_r55和android-11.0.0_r48,用户可以基于云手机Turbo套件进行二次开发,从而实现云手机极致的性能和业务体验。
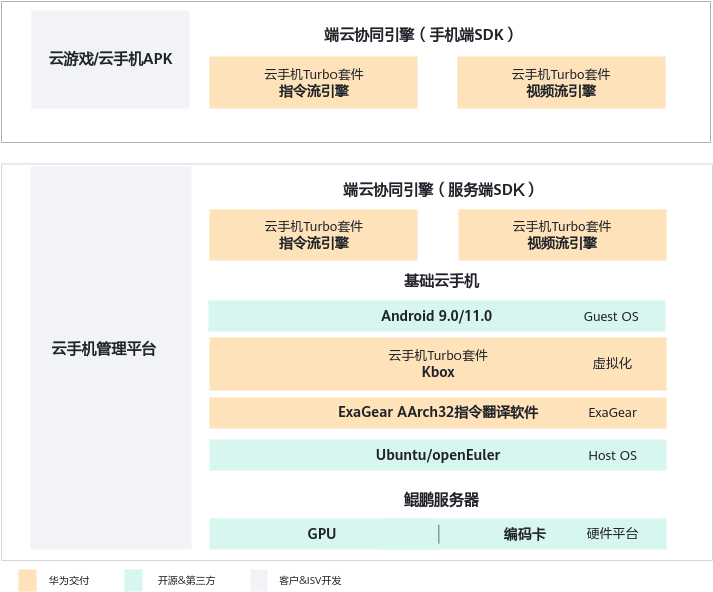
- ExaGear AArch32指令翻译软件
ExaGear AArch32指令翻译软件为鲲鹏服务器提供AArch32特性,基于鲲鹏服务器在云手机场景下能够完全兼容AArch32的应用,保障AArch32 V8.0指令应用100%兼容。同时也支持pre-translator特性,优化翻译后的APP启动时间,提升客户体验。
- Kbox云手机容器
Kbox云手机容器提供了软件定义手机的基础能力,其基于鲲鹏服务器,在Docker容器技术和Android开源项目(AOSP)基础上,实现了将GPU设备直通到容器的轻量级设备仿真层架构方案,提供了基于Android系统的云手机容器参考方案。可实现在鲲鹏服务器支持100路720p@30fps的Kbox云手机容器高并发(以托管场景为例,云手机并发密度取决于客户云手机实际应用),具有高密度、高兼容性等商业价值。
- 视频流引擎
视频流云手机方案基于视频流的端云协同引擎,提供了低时延的云手机画面同步能力,支持H.264和H.265硬编码,在画质相当的情况下,可实现H.265编码带宽减少30%+,其实现原理是利用云端强大的能力将应用和游戏的运行、渲染成最终的画面,并进行视频的压缩流化后,发送到终端播放显示。视频流引擎支持视频编码能力、视频解码播放能力、云手机图像截屏能力、触控和音频抓取/播放能力等核心功能,客户可以基于这些引擎进行二次开发,实现在移动终端上进行操控应用和游戏等操作。云端采用专业显卡进行渲染,可以获取高画质的业务体验;对终端的要求极低,只要求有视频解码能力即可;提供统一API,降低二次开发难度,易集成。
- 指令流引擎
指令流云手机方案采用业界独创的端云分离渲染技术,可实现云侧免GPU部署,整机硬件成本下降10%,其实现原理是云手机利用云端强大的算力,通过引擎实现云端复制应用和游戏的渲染指令,并进行渲染指令和纹理数据压缩流化,在端侧使用手机终端的GPU把这些指令渲染出来图像。指令流引擎,支持指令分离渲染、纹理数据视频流化、触控和音频抓取/释放能力等核心功能,客户可以基于这些引擎进行二次开发,实现在移动终端上进行操控应用和游戏等操作。通过指令流引擎技术,可以支持云手机全系统渲染,并提供近乎无损的画质,在1080P/2k/4k分辨率下均不影响传输带宽,并通过资源缓存技术,有效降低网络带宽50%+;突破云端GPU能力限制,实现无GPU高密运行机制,单路硬件成本降低40%,支持图形渲染状态机的本地执行与远端同步,实现1080P 30FPS低响应时延的用户体验。
大数据
鲲鹏BoostKit大数据聚焦大数据查询效率低、性能优化难等挑战,提供大数据组件的开源使能和调优、OmniRuntime、机器学习和图分析算法加速库等应用加速软件包,提升大数据分析效率。

- openEuler和毕昇JDK性能优化
适用Hive 2.X/3.X、Spark 2.X,openEuler操作系统基于大数据核心组件Hive、Spark通过磁盘IO、网络IO的调度策略优化、NEON指令优化等实现大数据计算性能提升。毕昇JDK性能优化基于鲲鹏处理器构建开源JDK社区,通过AppCDS、GC算法优化、编译优化等提升大数据核心组件Hive、Spark的计算性能。Hive性能提升2%~25%,Spark性能提升3%~25%。
- OmniRuntime
大数据OmniRuntime是鲲鹏BoostKit大数据面向应用加速推出的一系列特性,包括OmniData算子下推、OmniOperator算子加速、OmniShuffle Shuffle加速、OmniMV物化视图、OmniAdvisor参数调优和OmniHBaseGSI全局二级索引,旨在通过插件化的形式,端到端提升数据加载、数据计算和数据交换的性能,从而提升大数据分析的性能。Spark使用OmniRuntime加速特性执行SQL计算,相比不使能OmniRuntime加速特性执行SQL计算,性能提升20%~40%,具体包括组件如下:
- OmniData算子下推
适用于存算分离场景或大规模存算融合场景,支持Spark 3.0.0、Spark 3.1.1、Hive 3.1.0(Tez 0.10.0),是一种将大数据引擎的算子下推到存储节点或卸载节点的服务,从而实现了近数据计算,减少了网络带宽,将该特性集成到Spark后,基于TPC-H测试用例12条算子下推的SQL性能平均提升40%。集成到Hive后,基于TPC-H测试用例4条算子下推SQL性能平均提升20%。
- OmniOperator算子加速
适用于虚拟化场景,支持Spark 3.1.1、Spark 3.3.1、Spark 3.4.3、Spark 3.5.2、Hive 3.1.0版本,其采用Native Code(C/C++)实现大数据SQL算子来提高查询性能的特性,通过列式存储和向量化执行技术,同时利用鲲鹏加速库,提升算子的执行效率,将该特性集成到Spark后,基于TPC-DS 99条SQL验证,可实现Spark性能提升30%。
- OmniShuffle Shuffle加速
适用于虚拟化场景,支持RDMA和TCP两种网络模式,支持Spark 3.1.1、Spark 3.3.1、Hive 3.1.0版本,其基于TCP/RDMA等网络介质,优化数据分析过程中跨节点的数据写入、传输和读取流程,提升Shuffle性能,支持数据分析过程性能提升,将该特性及算子加速特性集成到Spark后,基于TPC-DS 99条SQL验证,可实现Spark性能提升40%。
- OmniMV物化视图
适用于虚拟化场景,支持Spark 3.1.1、Spark 3.4.3版本,支持ClickHouse 22.3.6.5版本,其通过AI算法从历史SQL查询中推荐出最优物化视图,并在Spark中自动对用户SQL进行物化视图匹配,将匹配成功的物化视图替换用户执行计划的部分SQL,大幅减少重复计算,提升查询性能,在将该特性集成到Spark后,基于TPC-DS基准测试用例实现了Spark组件计算性能平均提升30%,集成到ClickHouse后,基于Star Schema BenchMark实现ClickHouse计算性能平均提升数倍。
- OmniAdvisor参数调优
适用于虚拟机场景,支持Spark 3.1.1和Hive 3.1.0(只支持Hive on Tez模式),因Spark/Hive引擎参数众多,取值范围大,人工调优存在调优效率低,调优效果不佳,OmniAdvisor旨在通过AI的方式,实现参数的自动推荐,从而提升调优效率和调优效果。集成该特性后,基于TPC-DS 10条SQL可实现Spark性能提升10%。
- OmniHBaseGSI全局二级索引
适用于虚拟机场景,支持HBase 2.4.14版本,因HBase开源版本提供了主键索引,但若使用非Rowkey进行查询,则需要进行全表扫描,不仅耗费大量资源,查询时延也很长,OmniHBaseGSI全局二级索引,可以在非Rowkey列上创建全局二级索引,从而极大加速非Rowkey列的查询性能,集成该特性后,可实现在100并发下,平均时延小于30ms,P99时延小于300ms。
- OmniScheduler Yarn负载调度算法
适用于Hadoop集群节点间负载不均衡场景,支持Hadoop 3.3.4版本,Yarn负载调度算法优化开源版本Capacity Scheduler调度器,基于集群节点物理资源权重计算及排序结果进行资源调度,实现资源的均衡配置和高效利用。
- OmniData算子下推
- 机器学习和图分析算法
兼容Spark开源版本机器学习和图分析算法的API接口,支持适配Spark 2.3.2、Spark 2.4.5、Spark 2.4.6版本,部分算法支持Spark 3.1.1和Spark 3.3.1版本,基于算法原理和芯片特征针对机器学习和图分析算法进行深入优化,从而可以大幅提升了大数据算法场景的计算性能。基于鲲鹏CPU的机器学习&图分析算法加速库相比基于友商的Spark开源版本MLlib和GraphX,相同精度下计算性能提升20%以上。
分布式存储
鲲鹏BoostKit分布式存储使能套件聚焦开源Ceph存储的性能低、成本高等关键挑战,通过存储加速算法库和存储Ceph加速库等特性提升系统性能和降低存储成本,充分发挥鲲鹏算力优势,提供高性价比存储方案。
- 压缩算法
- 存储加速算法库
支持Ceph 14.2.8版本,其采用鲲鹏优化的算法代替主流开源算法,提升存储性能。当前包括EC算法、CRC16 T10DIF算法和CRC32C算法,具体介绍如下:
- EC算法
基于华为自研向量化EC编解码方案,通过同构映射将EC编码过程中所需的高阶有限域GF(2^w)乘法操作替换为二元矩阵乘法,进而将查表实现的复杂有限域乘法操作替代为XOR(Exclusive OR)操作,同时采用编码编排算法在校验块计算过程中对中间结果进行复用,减少XOR操作数,配合鲲鹏向量化指令实现编码加速。相比开源EC算法,KSAL EC算法性能更好。与主流开源EC算法相比,编码性能提升1倍以上。
- CRC16 T10DIF算法和CRC32C算法
通过大数求余算法和配合鲲鹏向量化指令实现编码加速,相比开源算法,CRC16 T10DIF算法4K性能提升130%,CRC32C算法4K性能提升30%。
- memcpy算法
- DAS智能预取算法
- Ceph百亿对象存储元数据ZSTD压缩算法
- EC算法
- 存储维护工具库
存储维护工具库(KSML)是华为自研的存储维护工具库,包括HDD/SSD故障预测与HDD/SSD慢盘检测功能,基于机器学习算法,通过收集SMART数据训练模型,预测与识别存储集群潜在故障盘,通过采集系统磁盘的svctm完成慢盘检测。
- KAE使能SPDK
SPDK的BDEV设备作为虚拟设备层对接底层多种设备类型(虚拟设备、物理设备),通过在BDEV设备中使能压缩和加解密能够支持所有SPDK设备。鲲鹏KAE通过Zlib和OpenSSL提供压缩和加解密,通过在BDEV设备中支持Zlib和OpenSSL的KAE加速实现对应能力的硬件卸载。
- EC Turbo
支持Ceph 14.2.8版本,适用于使用块存储或对象存储服务场景,不支持Bcache,该特性是针对开源Ceph的EC流程进行优化,降低了数据读写流程中的IO放大比例,从而使得整体性能更高。相对于Ceph开源EC,在均衡型配置下,对于块存储服务,EC Turbo性能可达到x86三副本80%以上,存储成本降低50%;对于对象存储服务,EC Turbo(4+2)性能达到x86三副本80%以上,大IO存储成本比三副本降低50%,小IO成本与三副本持平。
- 智能写Cache
支持Ceph 14.2.8版本,适用于块存储和对象存储服务写场景,其支持通过IO直通、QoS控制策略、Writeback控制策略以及GC控制策略,提升Bcache场景下的Ceph集群写性能。在块存储随机写场景下,IOPS性能可提升20%以上。
- IO直通
IO直通工具是针对Ceph均衡型场景下的一个流程优化工具,可以自动对Ceph集群进行性能优化。在均衡型配置场景下,使用IO直通特性可提升存储性能15%以上。
- 数据压紧
通过消除补零对齐操作带来的数据浪费问题,结合压紧封装、空间计数分配、粒度分流、聚合提交、批量回调等手段提升数据缩减率并提升系统整体IOPS,实现成本性能双收益。数据压紧可将数据压缩率再提高20%以上,对系统性能无损失。
- 元数据加速
元数据加速特性在RocksDB的基础上,结合华为自研算法进行了性能加速优化,在使能鲲鹏加速特性时可以获取更佳的性能。较开源RocksDB,混合读写场景性能提升超过30%。
- Ucache智能读缓存
智能读缓存通过IO智能预取精准识别热点请求并针对顺序、间隔等IO流进行IO预取,将IO提前载入读缓存,同时读缓存通过LRU算法淘汰冷数据,从而提高缓存的IO命中率,提升读性能。Ucache智能读缓存可提高读请求IO命中率以提升读性能。热点、顺序、间隔等IO流下性能提升100%。
- BoostIO
在存算分离架构下,BoostIO利用计算侧的内存和磁盘资源构建分布式多级缓存,写缓存通过RDMA高速通信、缓存亲和策略、副本冗余和线性布局等特性提升业务写性能,提高数据可靠性;读缓存通过数据预取提前将热点数据加载缓存磁盘中,通过LRU淘汰策略和冷热识别提高读缓存命中率,从而提升业务读性能。
- RDMA网络加速
通过在Ceph网络框架AsyncMessage中新增插件支持UCX网络框架,实现Ceph全闪存场景支持网络全RDMA化。UCX通信处理层主要包含ceph与UCX接口适配,并根据RNDV协议的特点,实现了零拷贝,提升大块写的性能。
机密计算
鲲鹏BoostKit机密计算TrustZone套件是基于ARM TrustZone技术的一个机密计算软件套件,包含华为自研TEE(Trusted Execution Environment,可信执行环境)安全操作系统iTrustee,鲲鹏服务器iBMC和BIOS等,结合开源的操作系统驱动以及SDK,旨在帮助伙伴更便捷地为行业客户构建机密计算解决方案,从而为用户的关键数据提供完整性、机密性保护和可信使用。
普通鲲鹏服务器默认不带有机密计算TrustZone完整套件,需要在购买鲲鹏服务器时明确带有TEE功能,支持TEE功能的服务器会在出厂阶段完成TrustZone套件预置安装。
iTrustee基于TrustZone技术实现了整套安全解决方案,包含正常模式的客户端应用(Client Application,CA)、安全模式的可信应用(Trusted Application,TA)、安全模式下的可信操作系统。
iTrustee应用于金融大数据数据挖掘场景,可保证数据处理过程中的机密性。可应用于一体化大数据中心场景,确保数据可信交易,同样也可用于行业隐私计算认证场景,确保计算过程中避免泄漏个人隐私信息。
iTrustee安全可靠,其基于华为自研的微内核实现,安全OS已在手机侧商用近10年,用户数已过亿,同时安全性获得CC EAL4+认证,兼容性获得GlobalPlatform认证。在规格方面也较为灵活,其中TEE侧安全内存支持按需配置,最大可配512GB,可支持大数据、AI等大型应用运行。
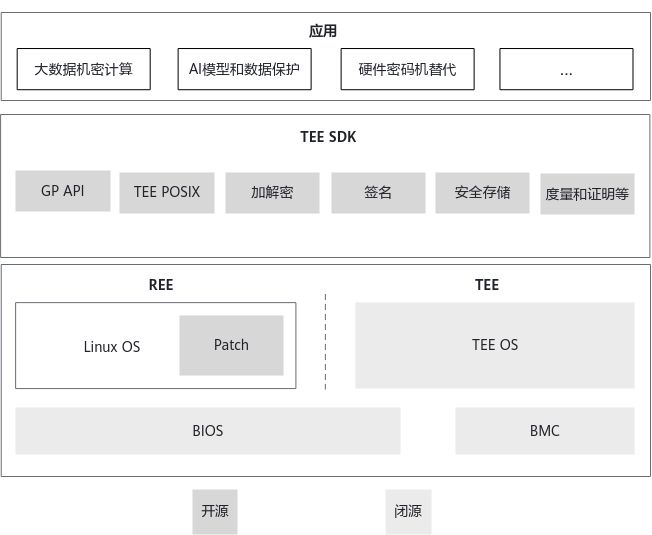
- TEE SDK:提供机密计算REE(Rich Execution Environment,富执行环境)侧和TEE的接口、TA/CA加密和签名工具、参考代码和接口说明等,方便用户快速构建应用。
- REE Patch:操作系统的驱动,包括内核模块以及用户接口库。
- TEE OS:华为自研安全操作系统,为可信应用提供加解密、安全存储等服务,并确保TA的完整性和机密性。
- BIOS:完成对TEE OS的解密以及验证,确保TEE OS的机密性以及完整性。
- BMC:支持对TEE OS的升级维护。
鲲鹏BoostKit机密计算TEE套件(简称TEE套件)基于S-EL2在TEE侧实现机密虚拟机( Confidential VM,cVM)能力,实现现有普通虚拟机中的软件栈无需整改即可迁移到机密环境中。鲲鹏BoostKit机密计算TEE套件主要包括KVM模块、TMI模块和TMM模块,整体系统架构如图6所示。

|
类别 |
子类 |
说明 |
|---|---|---|
|
行业客户 |
Host/Guest OS |
自行选择支持VirtCCA的Linux OS进行Host/Guest OS的安装部署。Host和Guest OS目前已开源到openEuler社区。
|
|
华为交付件 |
TMM |
运行在TEE内的虚拟化组件,负责机密虚拟机的CPU和内存的虚拟化管理。正常情况下,若已购买支持TEE套件的鲲鹏服务器,TMM会内置于硬件平台内,后续可以通过升级TMM更新版本。 |
|
硬件Firmware |
为支持TEE套件特性,硬件Firmware版本也进行了相关的适配:
|
|
|
TEE套件SDK |
为支持TEE套件远程证明功能、以及密钥派生功能被客户应用集成,TEE套件提供了对应的SDK方便客户开发,其中包括:
|
- 度量启动
- 采用鲲鹏硬件高安全子系统HSM作为可信根,将鲲鹏设备启动过程中与TEE相关的固件进行度量,并将最终结果放到高安子系统的SRAM中,形成平台度量报告。
- 将虚拟机启动过程的Kernel、启动参数等进行度量,形成虚拟机级度量报告。
- 将整体报告打包后形成完整的度量Token,提供远程证明能力。
- 远程证明
鲲鹏机密计算TEE套件远程证明目标主要是向用户证明机密虚拟机(cVM)和机密计算平台的可信程度。包括:
- cVM是否运行在真实的机密计算环境。
- cVM配置参数与cVM中运行的代码是否被篡改过。
- Sealing Key
TEE套件机密虚拟机支持密钥封印(Sealing Key)功能,机密虚拟机可以生成一个与虚拟机绑定的密钥,虚拟机重启后该密钥保持不变。
- 安全存储
机密计算通常是为了保障运行时的数据安全,但是由于用户在使用数据时需要保障其存储数据本身的机密性,因此通过对存储镜像的加密并结合远程证明的功能,来实现机密计算的安全存储功能。
- 机密容器
机密容器是基于机密虚拟机的核心能力,通过复用Kata/Coco社区的基础功能,使能机密容器的加解密、签名验签、Nydus镜像加速以及远程证明的整套能力,从而达到对容器端到端的保护。机密容器的能力主要通过k8s+containerd+Kata+QEMU+KVM的整套软件栈进行构建,结合Coco社区当前已经提供的KBS+AS组件来实现端到端的功能。由于管理面仍然使用k8s+containerd,整体使用和普通容器保持一致。
- 设备直通
设备直通是基于华为鲲鹏芯片通过预埋在PCIe Root Complex里的PCIe保护组件,在PCIe总线上增加选通器,对CPU与外设间的通信进行选通,即对SMMU的Outbound Traffic和Inbound Traffic的控制流和数据流进行控制。在机密计算场景下,支持PCIe设备直通TEE安全域,数据免中转免拷贝,以此保证整体数据链路的安全性。并且基于该技术点,鲲鹏机密计算能支持异构机密计算,无需设备改造。
- 国密加密
国密硬件加速是基于华为鲲鹏芯片,通过KAE加速器能力复用到安全侧,并采用openEuler UADK用户态加速器框架,提供客户机密虚拟机内国密加速性能提升以及算法卸载的能力。
数据库
鲲鹏BoostKit数据库对开源MySQL OLAP查询效率低、OLTP场景高并发下锁导致的性能问题等关键挑战,提供MySQL可插拔向量化分析引擎、MySQL无锁优化、MySQL可插拔线程池和MySQL CRC32指令优化等加速软件包,深度优化了OLAP查询分析效率和OLTP在线交易事务处理能力,同时新增针对Milvus向量数据库的优化特性,充分发挥多核算力极致性能。提供主流开源和商业数据库最佳实践,帮助开发者高效完成开源组件迁移和调优。
- NVMe SSD原子写
适用MySQL各版本,通过SSD硬件原子写特性消除Doublewrite双写软件冗余提升数据库的性能,通过SSD硬件原子写特性密集写场景性能预计提升15%。
- Gazelle网络优化
适用MySQL各版本,基于DPDK在用户态直接读写网卡报文,共享大页内存传递报文,使用轻量级LwIP协议栈。能够大幅提高应用的网络IO吞吐能力,通过Gazelle网络优化,TPC-C综合性能预计提升10%。
- 鲲鹏GCC CFGO反馈优化
适用MySQL各版本,采用多模态(源代码、汇编码、二进制)、全生命周期(编译、链接、后链接)的持续优化手段,获取性能更优的目标程序。使数据库TPC-C综合性能提升10%。
- KAEzip压缩解压缩优化
支持使用zlib进行压缩和解压的Greenplum版本,使用鲲鹏硬加速模块实现压缩、解压缩算法,结合无损用户态驱动框架从而提升查询性能。采用KAEzip可以在到达硬件瓶颈之前,在同一时间只处理一个请求、IO占比多的场景下,端到端的性能提升10%。
- MySQL并行查询优化
支持MySQL 8.0.20、MySQL 8.0.25版本,MySQL单SQL查询只能调度单线程,多核CPU无法使用,单查询性能差,难以满足查询场景的性能要求,通过并行查询优化提升查询性能。可实现查询性能提升>1倍(性能提升与并行度有关)。
- MySQL无锁优化
支持MySQL 8.0.20版本,在MySQL OLTP场景下DML语句(Insert、Update、Delete)大量并发操作trx_sys全局结构体中的关键数据结构,造成临界区的竞争和同步瓶颈。MySQL无锁优化改造后使用无锁哈希表维护事务单元,减少锁冲突,提升并发度,可实现Sysbench写场景下性能提升20%。
- MySQL细粒度锁优化
支持MySQL 8.0.20版本,在MySQL OLTP场景下DML语句(Insert,Update,Delete)大量并发操作访问lock_sys->mutex全局锁保护的关键数据结构,造成锁竞争严重导致性能下降。替换成细粒度hash桶锁。减少锁冲突,提升并发度。可实现TPC-C综合性能预计提升10%。
- MySQL NUMA调度优化
支持MySQL 8.0.20、MySQL 8.0.25版本,在MySQL OLTP场景下高并发下系统默认的线程调度使得线程频繁跨NUMA的访问,这种情况导致CPU开销增大,性能提升受限制,需要对用户处理线程做动态绑定固定NUMA CPU减少跨NUMA访问,同时需要保证CPU访问的负载必须均衡,后台线程静态绑定固定NUMA CPU减少跨NUMA访问,提升后台线程效率。可实现OLTP场景性能提升10%。
- MySQL可插拔线程池
支持MySQL 5.7.27、8.0.20、8.0.25、8.0.30和8.0.35版本,仅基于MySQL 8.0.25、8.0.30和8.0.35的线程池特性支持可插拔动态加载。在MySQL OLTP场景下,高并发下线程数过多,CPU消耗在无效的资源竞争和频繁切换上,线程池方案通过队列方式管理任务,所有的任务先放入等待执行队列,按系统执行能力取出任务队列让CPU执行,每个CPU同时处理任务个数是有限的,一般2~5个最优,从而保持稳定的业务处理能力。可实现OLTP TPC-C场景性能10000并发性能下降到最优的10%左右,开启线程池功能,性能可维持在85%。
- CRC32指令优化
提供支持MySQL 8.0.25版本的补丁包,该特性采用鲲鹏CRC32硬件指令替换CRC32算法的软件实现,从而提高系统业务的性能。通过CRC32指令优化特性,MySQL Sysbench写场景性能有5%的提升。
- MySQL可插拔在线向量化分析引擎
支持MySQL 8.0.25版本,该特性是MySQL预留接口第二执行引擎(Secondary Engine)的一种轻量实现,通过执行计划的并行计算,充分发挥鲲鹏CPU多核的优势,使OLAP性能倍级提升,且具有可插拔性,支持动态加载。采用并行加速技术,可将OLAP查询性能提升到3倍以上。
- Milvus KScaNN优化
支持Milvus 2.4.5版本,该特性通过Milvus预留接口,通过对接鲲鹏自研召回算法KScaNN,发挥鲲鹏优势,使查询性能(QPS)在高召回率(0.95以上)的前提下,获得30%以上的提升。
- Milvus KBest优化
支持Milvus 2.4.5版本,该特性通过Milvus预留接口,对接鲲鹏自研召回算法KBest,发挥鲲鹏优势,使查询性能(QPS)在高召回率(0.99)的前提下,获得30%以上的提升。
- Milvus向量指令优化
支持Milvus 2.4.5版本,该特性使用SEV指令集和软硬件预取实现,通过减小了距离函数计算的开销,可以将Milvus查询性能(QPS)在高召回率(0.99)前提下提升20%。
虚拟化
鲲鹏BoostKit虚拟化使能套件聚焦虚拟化轻载性能低、网络损耗大、资源碎片严重及开源生态可用性等关键痛点,提供了OVS流表网卡加速等特性提升系统性能,充分发挥鲲鹏多核架构、核间完全隔离的优势,释放鲲鹏极致算力。
- OVS流表网卡加速
在虚拟化场景下,将OVS转发流表卸载到网卡硬件上,利用硬件的查表能力来提升流表的查找速度,提高虚拟化网络的处理能力,可实现虚拟化网络的转发性能提升10倍。
- 虚拟化调度优化
- KAE加速热迁移
适用于虚拟机热迁移场景,KAE的压缩模块提供了zlib标准接口KAEZlib,使用KAE压缩模块可以替代原生zlib库加速虚拟机热迁移,相比于原生Zlib,KAE在虚拟机热迁移压缩与解压缩中能够显著节省CPU资源,在同CPU资源下,KAE能显著提升虚拟机热迁移速度。
- 虚拟化硬件辅助加速
适用于网络和IO密集型业务,该特性通过在鲲鹏920新型号处理器使能GICv4.1的直接注入虚拟中断和直接注入vSGI的中断直通类型,可以显著降低中断响应时延,提升网络/IO密集型业务吞吐量。
- 热插拔
- vCPU热插拔:虚拟机vCPU依照ACPI规范,模拟ACPI GED设备。在vCPU调整时,通过中断和处理函数方式,动态模拟CPU上下电。
- QEMU虚拟机内存热插:该特性使得虚拟机的XML配置文件中可以包含一个初始内存配置为0的NUMA节点,并且允许后续通过内存热插相关命令,动态地向该NUMA节点增加内存。
- MPAM插件
通过限制离线业务对内存带宽和L3缓存容量的占用,避免离线业务干扰实时业务的性能:
- 每个计算节点上部署MPAM插件,YAML文件中配置资源组,每个资源组可指定内存带宽和L3缓存容量。
- 部署离线业务时,在YAML文件中指定该业务归属的资源组。
- MPAM插件侦听到部署任务后,将容器中业务的进程ID配置到对应的资源组中(限制信息会通过OS配置到硬件芯片上)。

MPAM插件涉及的共享资源包括:L2 Cache、L3 Cache和DMC带宽。
- K8s NUMA亲和性调度插件
适用于容器超分场景,支持K8s 1.28.4和Containerd 1.7.14版本,其通过容器运行时的NRI模式捕捉容器请求,依照调度策略设置容器cgroup参数,以实现NUMA亲和性管理,增加Kubernetes容器超分场景下的NUMA亲和机制,提升容器在超分场景下的5%~10%的性能。
- K8s SR-IOV直通插件
适用于K8s下网络、加解密性能提升场景,该特性通过Devices Plugin管理SR-IOV设备,简化容器直通SR-IOV设备的操作,目前支持直通网卡、KAE设备,可加速容器场景的加解密、网络性能。
- vKAE
适用于鲲鹏虚拟机中频繁使用加解密和解压缩的业务,鲲鹏加速引擎KAE(Kunpeng Accelerator Engine)是基于鲲鹏处理器提供的硬件加速解决方案,包含了KAE加解密和KAEzip。vKAE也可以在虚拟机或者容器中使用KAE能力。其中KAE加解密和KAEzip分别用于加速SSL(Secure Sockets Layer)/TLS(Transport Layer Security)应用和数据压缩,可以显著降低处理器消耗,提高处理器效率。此外,加速引擎对应用层屏蔽了其内部实现细节,用户通过OpenSSL、zlib标准接口即可以实现快速迁移现有业务。
搜推广
鲲鹏BoostKit搜推广使能套件旨在为互联网的搜索、推荐、广告业务场景提供基于鲲鹏平台的全栈解决方案的加速能力,组件涵盖召回场景核心检索算法、排序场景模型推理TensorFlow框架软件全栈及其AI核心算子库等。
- 鲲鹏召回算法库
鲲鹏召回算法库SRA_Recall是华为提供的基于鲲鹏平台优化的召回算法库,包含KBest和KScaNN:
- KBest(Kunpeng Blazing-fast embedding similarity search thruster)鲲鹏图检索算法,是鲲鹏自研的高效的图检索算法。通过量化、向量指令等方法优化了最近邻搜索的性能和精度,用于多维向量近似最近邻搜索,提供对标开源Faiss HNSW算法的检索能力,适用于网络搜索、多模态搜索、推荐系统和RAG等场景;
- KScaNN(Kunpeng Scalable Nearest Neighbors)是基于倒排索引,结合鲲鹏架构深度优化索引布局、算法流程和计算流程,充分挖掘芯片潜力形成的向量检索算法,提供对标开源ScaNN的完整检索能力,适用于网络搜索、多模态搜索、推荐系统和RAG等场景;
- 鲲鹏推理加速套件
鲲鹏推理加速套件SRA_Inference是华为提供的基于鲲鹏平台优化的推理加速套件,当前主要包含鲲鹏TensorFlow算子库:
- KTFOP(Kunpeng TensorFlow Operator)鲲鹏TensorFlow算子库,是鲲鹏自研的高效的TensorFlow算子库。通过SIMD(Single Instruction Multiple Data)指令、多核调度等方法,提高CPU侧算子性能,减少CPU侧计算资源的占用,从而提高在线推理端到端整体的吞吐量,适用于搜索、推荐、广告等推理场景;
- 鲲鹏推理AI算子库
鲲鹏AI库KAIL(Kunpeng Artificial Intelligence Library)是华为提供的基于鲲鹏平台优化的高性能AI算子库,主要完成深度神经网络算子库和拓展算子库,拓展算子包括softmax、random_choice等。
- KAIL_DNN,深度神经网络算子库(Deep Neural Network Library),结合鲲鹏处理器微架构特性,通过向量化、汇编、算法优化等手段,提升DNN核心算子性能,并通过插件化形式对接开源oneDNN库提供完整能力,适用于AI、HPC领域;
- KAIL_DNN_EXT,深度神经网络算子拓展库(Deep Neural Network Extension Library),旨在作为KAIL_DNN的拓展库,深度优化softmax、random_choice等算子,为AI特定场景封装为Python语言接口库直接提供给用户调用,适用于AI领域;
HPC
HPC聚焦资源调度效率低、应用性能优化难等关键挑战,通过全栈架构创新、软硬件自研、基础软件优化和行业应用性能调优等技术构建全栈高性能计算基础平台,帮助客户释放平台算力,缩短产品上市周期,提升企业产品竞争力。
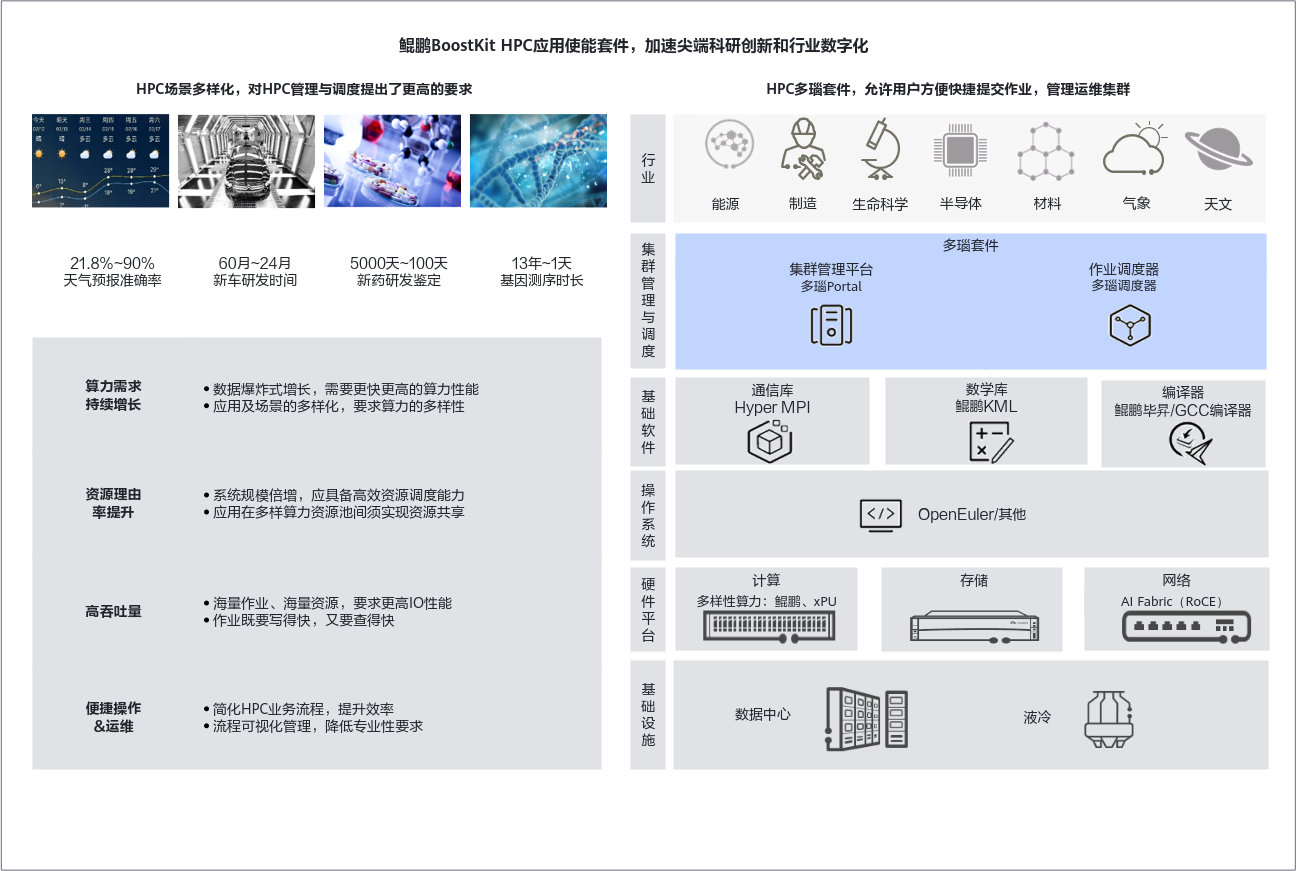
- 多瑙Portal是HPC集群管理平台,通过可视化界面为用户提供了便捷的HPC集群系统数据管理和软硬件资源管理功能,串联整个工作流程,帮助用户合理地进行作业调度和资源分配,提升集群系统计算能力利用率。
- 操作系统桌面风格:Web界面桌面风格布局,多窗口多任务高效操作。
- 设计计算一体化:支持基于Linux平台的远程2D/3D可视化,打通设计与计算全流程。
- 资源分析与监控:多维度分析集群运行历史,实时监控集群资源使用。
- 异构多集群管理:同时管理多瑙调度集群和第三方调度集群,数据与资源统一管理。
- 多瑙调度器提供大规模集群下的高资源利用率、高吞吐量的作业调度能力:
- 超大规模调度:最大支持3000节点/38万核超大规模集群调度。
- 高吞吐量作业:端到端吞吐量高,达到每小时400万+个作业。
- 高资源分配率:高效灵活的调度框架,资源分配率达到90%+。
- HPCKit集成华为高性能通信库(Hyper MPI)、鲲鹏数学库(KML)、鲲鹏毕昇/GCC编译器等针对鲲鹏平台深度优化的HPC基础软件,实现一键部署和最优协同,使能HPC领域应用实现极致性能。
- Hyper MPI是基于Open MPI 4.1.1和Open UCX 1.10.1,支持MPI-V3.1标准的并行计算API接口,新增了优化的集合通信框架。同时,Hyper MPI对数据密集型和高性能计算提供了网络加速能力,使能了节点间高速通信网络和节点内共享内存机制,以及优化的集合通信算法。Hyper MPI的UCX COLL通信框架能够支持的最大数据包长度为2^32字节。
- 鲲鹏数学库(KML)是基于华为鲲鹏处理器深度优化的高性能数学计算加速库,支持快速傅里叶变换、矩阵计算、向量化运算、三角函数、对数等常用数学函数,由KML_BLAS、KML_SPBLAS、KML_VML、KML_MATH、KML_FFT、KML_LAPACK、KML_SVML、KML_SOLVER、KML_JAVA、KML_SCALAPACK、KML_VSL、KML_NUMPY、KML_EIGENSOLVER和KML_IPL等十四个子库组成,可提供业务需求集成使用。
- 毕昇编译器基于开源LLVM开发,并进行了优化和改进,同时支持Fortran语言前端,是针对鲲鹏平台的高性能编译器。除LLVM通用功能和优化外,对中端及后端的关键技术点进行了深度优化,并集成AutoTuner特性支持编译器自动调优。