调优思路
编译器精度优化的思路如下:
- 优先设置鲲鹏和x86两个平台的编译选项为-O1,并且使用统一的开源sleef数学库。在此条件下,查看鲲鹏和x86是否可以做到精度完全一致或者相比-O3有精度提升。因为ICC会有循环合并BUG,所以可能需要针对特定文件使用-O1选项。图1 ICC循环合并BUG
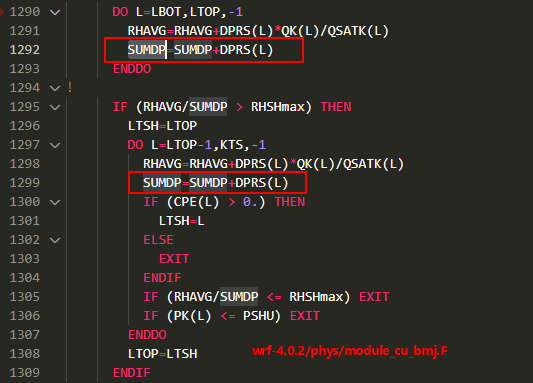
根据代码语义,在该循环中,SUMDP的计算过程是将若干个数按照数组索引的顺序相加。测试发现,ICC在 -O3、-O0/-O1编译配置下,SUMDP计算结果会出现差异。
以六个数顺序相加结果的二进制差异为例(通过手工运算得出的正确结果 0b01000110010110001100000000110100):
- ICC使用 -fp-model precise -O3 编译配置,得到结果是: 0b01000110010110001100000000110011
- ICC使用 -fp-model precise -O0或-O1 编译配置,得到结果是: 0b01000110010110001100000000110100
- 毕昇使用 -O3或-O0 编译配置,得到的结果都是: 0b01000110010110001100000000110100
因此可以推测:ICC使用-fp-model precise -O3编译配置,在对循环进行合优化时会损失精度。该优化与-fp-model precise相矛盾,是ICC编译器的BUG。
WRF源码中会出现此Bug的代码有:
- physics/module_cu_bmj.F(对应物理参数:cu_physics=2)
- physics/module_cu_gf_deep.F(对应物理参数:cu_physics=3)
- physics/module_ra_goddard.F(对应物理参数:ra_lw_physics=5/ra_sw_physics=5)
- 排除O1的选项差异之后,按照之前的精度基准,基于表1选择不同的编译选项进行调试。在如下这些策略中,最常用的是最优精度模式。
表1 精度调试策略 精度公式
x86选项
毕昇选项
精度最好结果
最优性能模式
O3
O3 ffp-model=fast
近似
最优精度模式
O3 -fp-model=precise
-no-ftz -init=zero -init=arrays
O3 -faarch64-pow-alt-precision=21 -enable--alt-precision-math-functions km_l9 -Hx,124,0xc00000 -ffp-contract=off -finit-zero -mllvm -disable-sincos-opt -MflushZ
或者
-O3 -ffp-compatibility=18/21 -finit-zero -lkm_l9
相等
精度性能折中模式
去除-no-ftz -init=zero -init=arrays等精度选项中的若干
去除-ffp-contract=off 、-finit-zero、 -disable-sincos-opt等精度选项中的若干
相等
表2 影响精度的主要编译选项 分类
精度编译选项
x86精度选项
毕昇精度选项
毕昇优化选项
精度影响
编译器
编译器版本
2018/2021
2.1~3.1
2.1~3.1
编译器版本差异可能导致结果不一致,intel不同版本编译器在fast模式下关于浮点精度处理不一致导致关键指标波动,且鲲鹏无法拟合,所以一定要优先使用客户指定版本编译器,毕昇优先选择高版本。
优化选项
优化选项
O0-O3-Ofast
O0-O2
O3-Ofast
O0选项会关闭所有优化。该选项对性能影响很大,不建议开启。在O3选项前提下对精度进行调整,当出现ICC循环合并BUG时,仅针对文件使用-O1选项。
浮点模型
运算重排序
无
默认不开启
funsafe-math-optimizations
允许打开如下重排序编译选项。
-fno-signed-zeros
-fno-trapping-math
-fassociative-math
-freciprocal-math
快速运算
ffast-math
默认不开启
ffast-math
默认使能。
-fno-honor-infinities
-fno-honor-nans
-fno-math-errno
-ffinite-math
-fassociative-math
-freciprocal-math
-fno-signed-zeros
-fno-trapping-math
-ffp-contract=fast
统一精度选项
无
ffp-compatibility
默认不开启
-ffp-compatibility=18/21 打开该选项,且不对相关精度选项做设置的情况下,等价于打开如下选项:
-ffp-compatibility=21 -fp-model=precise等价于-ffp-contract=off -faarch64-pow-alt-precision=21 -Hx,124,0xc00000 -mllvm -enable-alt-precision-math-functions
毕昇对标Intel 2018精度选项如下所示
-ffp-compatibility=18 -fp-model=precise等价于-ffp-contract=off -faarch64-pow-alt-precision=21 -Hx,124,0x800000 -mllvm -enable-alt-precision-math-functions -enable-18-math-compatibility
如下精度选项因特殊原因,未加入-ffp-compatibility选项。
- -finit-zero,将fortran中未初始化的变量初始化为0,intel编译器使用单独选项控制,且存在应用使用intel编译器编译加了该选项后无法正常运行的情况,此时对齐精度,毕昇也不能打开对应选项,因此不加入-ffp-compatibility选项控制。
- -fp-model=,考虑到后续-ffp-compatibility可能会支持-fp-model=fast,根据-fp-model调整-ffp-compatibility的行为,分别拟合ICC的precise和fast,因此不加入-ffp-compatibility选项控制。
- -mllvm -disable-sincos-opt在-fp-model=precise会默认打开。
- -enable-alt-precision-math-functions -enable-18-math-compatibility选项会生成kml精度接口调用,需要与kml绑定使用。
浮点精度选项
fp-model=precise
默认ffp-model=precise
ffp-model=fast
ffp-model有如下三种模式:
- 精度模式“precise”(默认)等价于
-ffp-contract=fast -fno-rounding-math
- 严格模式“strict”等价于
-ftrapping-math -frounding-math -ffp-exception-behavior=strict
- 性能模式“fast”等价于
-menable-no-infs -menable-no-nans -menable-unsafe-fp-math -fno-signed-zeros -mreassociate
-freciprocal-math -ffp-contract=fast -fno-rounding-math -ffast-math -ffinite-math-only
数学函数
数学函数-sincos函数优化
无
disable-sincos-opt
默认
毕昇会对连续出现的sin和cos计算进行合并处理,这个过程会导致精度差异。
min/max函数优化
无
faarch64-minmax-alt-precision
默认
用于更改对于min/max函数的优化策略,使得min/max函数的计算结果与非Arm平台保持一致。
recip倒数指令优化
无
mllvm -aarch64-recip-alt-precision
默认
使用软浮点补偿,使得recip倒数指令的计算结果与非Arm平台保持一致。
rsqrt倒数开方指令优化
无
mllvm -aarch64-rsqrt-alt-precision
默认
使用软浮点补偿,使得rsqrt倒数开方指令的计算结果与非Arm平台保持一致。
倒平方根优化
无
mllvm -disable-recip-sqrt-opt=<true|false>
默认
在fastmath场景下,对A = (C / sqrt(Y));B = A * A的形式进行优化,使用更少的指令完成运算。该精度选项设置为true表示关闭该优化,默认false表示使能该优化。
融合乘加
无
ffma-combine-fdiv
默认
通用选项,用于将表达式a/b+c优化为fma(a, 1/b, c),有利于保持计算结果与非Arm平台保持一致,仅在-ffp-contract=fast时起效。
融合乘加
无
ffma-reverse-associative
默认
通用选项,用于将表达式ab+cd优化为fma(a, b, c*d) ,有利于保持计算结果与非Arm平台保持一致,仅在-ffp-contract=fast时起效。
允许交换律结合律
无
fassociative-math
默认
允许交换律结合律。
除法函数优化
无
freciprocal-math
默认
允许通过倒数将除法转换为乘法。
松散的内联数学函数优化
无
frelaxed-math
默认
使用内联数学函数。
舍入误差
fp-port
fno-rounding-math
默认frounding-math
是否使用IEEE754标准的四舍五入,默认舍入到最近的值。
crc32计算优化
无
mllvm -enable-gzipcrc32=false
默认mllvm -enable-gzipcrc32=true
识别代码中的crc32计算逻辑,使用处理器内置指令进行替代以加速计算。设为true开启该优化,false关闭优化,默认开启。
INF的优化
无
ffinite-math-only
默认
假设没有无穷大或NaN。clang版本相当于-fno-honor-nans -fno-honor-inifinities。
数学函数优化
无
默认
menable-unsafe-fp-math
允许不安全的浮点数学函数优化,可能会降低精度。
数学库
数学库-csqrtf和zsqrtf函数拟合
默认IMF
faarch64-pow-alt-precision=18/21
默认libm/pgmath
复数开根号的结果在两个平台表现不一致。
数学函数-pow函数拟合
默认IMF的80位精度版本powr8i4
faarch64-pow-alt-precision=18/21
默认libm
代码中常见如a**4 或者 2**a一类的计算指数类型的表达式,这类表达式的优化时由编译器决定的,这导致ICC与毕昇在这种表达式中造成了大量的差异,针对这种问题编译器端开发了-faarch64-pow-alt-precision=18/21选项用来拟合ICC的优化行为。此选项可以使各类pow优化表达式在O0-Ofast等优化等级下与ICC保持一致。参数为18则与ICC 2018.1版本保持一致,参数为21则与ICC 2021保持一致。
数学库-使能精度数学函数log
默认IMF
默认不开启
mllvm -enable-18-math-compatibility
作用是将数学函数tgammaf、cbrt、log和log10 等换作有_18后缀的函数,从而实现控制数学函数精度的效果(需要结合KML数学库使用)。此选项仅可以在O1及以上优化,且开启-mllvm -enable-alt-precision-math-functions时起效。
数学库-使能精度数学函数sin/cos
默认IMF
enable-alt-precision-math-functions km_l9
默认使用libm
不同数学库对同一个数学函数(如asindf、cosdf、cbrt、powr8i4、exp2等)的实现略有差异。虽然差异数量少,差异位数少(比如仅最后一位有差异),但是误差也会在应用的反复迭代计算中不断累积和放大。
WRF测试发现:atan2f一例输出数据的最后一位出现误差,该误差在WRF计算中不断累积,最终导致24小时气象预报结果中累计降水指标的误差超过50mm(24小时累计降水达到50mm是暴雨级别)。
按照ICC数学库算法实现函数,并通过足量数据覆盖进行验证,注意此选项只在O1及以上优化等级可以起效,作用是将数学函数__mth_i_cosd,__mth_i_asind及__pd_powi_1的函数名替换为cosdf、asindf及powr8i4。
浮点控制
立即数精度BUG修复
无
124,0xc00000
默认不修复
代码中有一些立即数,其中有少量立即数被不同编译器访问时,其读取到内存里的数据会出现不一致。以0.002362E12_8为例:
ICC编译器读取到内存时,其值为(十六进制):41E1992860000000
毕昇编译器读取到内存时,其值为(十六进制) :41E1992840000000
GCC编译器读取到内存时,其值为(十六进制) :41E1992840000000
增加此编译选项可以解决此问题。
FMA
[no-]fma
ffp-contract=off
默认ffp-contract=on
是否生成融合乘加运算。
拟合ftz
[no-]ftz
clang: fdenormal-fp-math=[ieee|preserve-signs|positive-zero]
flang-SSE-x86: Mflushz
flang: -Mdaz
默认不处理
x86与鲲鹏处理器在FTZ指令的处理方式上存在差异,差异表现在:
- 先做舍入还是先做FTZ判断。x86是先舍入后判断,而鲲鹏是先判断后舍入。
- FTZ边界值定义也不同。x86符合-IEEE标准,即默认极小数(subnormal number)不会被处理,而鲲鹏按照如下规则处理边界值:
- preserve-signs保留极小数的符号
- positive-zero/Mdaz将极小数刷为正0
未初始化数组
init=zero -init=arrays
finit-zero
默认随机初始化
未初始化的场景是由编译器进行初始化的,但是fortran的语言标准在这一块缺乏规范,所以初始化的范围、方式就缺乏一致性,毕昇编译器针对这些场景做了大量的开发,当前可使用-finit-zero选项实现安全的初始化。
绝对值求和运算
无
mllvm -sad-pattern-recognition=false
mllvm -sad-pattern-recognition=true
对差值的绝对值求和运算(sum += abs(a[i] - b[i]))进行优化,生成更简单高效的运算序列。该精度选项设为true表示开启该优化,默认开启。
矢量化的运算
无
mllvm -aarch64-hadd-generation=false
mllvm -aarch64-hadd-generation=true
对于矢量化的运算 (x[i] + y[i] + 1) >> 1,使用一条ARM NEON指令URHADD完成运算,从而生成更优的代码。设为true开启该优化,默认开启。
规约顺序
无
mllvm -instcombine-reorder-sum-of-reduce-add=false
mllvm -instcombine-reorder-sum-of-reduce-add=true
通过更改reduction操作的顺序生成更优的reduction代码。设为true开启该优化,默认开启。
未定义移位行为溢出处理
无
foverflow-shift-alt-behavior
默认关闭fno-overflow-shift-alt-behavior
对于超出整型数据类型位宽大小的未定义移位行为,如(int) a << 40,毕昇编译器将表达式提前优化为整型常量,以避免在不同优化遍中会被识别优化成不同的值,该选项默认关闭。
统一控制
无
ffp-compatibility=17/18/21
ffp-compatibility=17/18/21
通用选项,用于统一控制为保持计算结果与非Arm平台保持一致需要打开的所有选项。
浮点数默认精度
无
fdefault-double-8
默认单精度
默认浮点数为单精度,使能改选项之后改为双精度。
浮点转换
无
freal-10-real-16
freal-10-real-4
freal-10-real-8
默认不转换
将10位浮点转换为16/4/8位。
寄存器优化
无
modd-spreg
默认mno-odd-spreg
禁用/开启奇数位单精度浮点寄存器。
符号0的优化
无
fsigned-zeros
默认fno-signed-zeros
允许优化忽略带符号零的差异。
NAN的优化
无
fhonor-nans
默认fno-honor-nans
假设所有NaN都是无影响的。clang版本也忽略无影响的NaN。
INF的优化
无
fhonor-infinities
默认fno-honor-infinities
假设没有无限大的值。