Cruiser悟合
工具介绍
Cruiser 是一款智能精度分析工具,可以自动分析和插入源代码,并快速找到源代码中精度的差异。工具分为两个部分,包括自动定位程序和精度分析库,目前已集成至DevKit工具链中。
是一款智能精度分析工具,可以自动分析和插入源代码,并快速找到源代码中精度的差异。工具分为两个部分,包括自动定位程序和精度分析库,目前已集成至DevKit工具链中。
Cruiser的两个组成部分的功能如下:
- 自动定位程序
- 分析NLP程序源码
- 建立索引调用链
- 监视变量全生命周期
- 自动插入分析语句
- 精度分析库
- 分析语句具体实现,提供底层精度分析能力
- 包括值差异和异常值(NaN/INF)校验
约束条件
源代码可以在x86平台和鲲鹏平台编译并成功运行。
使用指导
- 获取计算精度工具Cruiser(https://gitee.com/openeuler/hpcrunner/tree/master/software/utils/cruiser,包含linux_x86及linux_arm版本)
- 使用Cruiser工具完成对源码的插桩
- 将源代码及Cruiser工具上传到同一服务器上
- 运行以下命令完成对源码的自动插桩
1./cruiser.exe --hook-mode main --root APP_DIR
- 将插桩后的源码分别在x86平台和鲲鹏平台上编译运行,生成日志文件
- 使用Cruiser工具分析计算精度差异
- 将源代码、Cruiser工具以及在x86平台和鲲鹏平台上运行生成的日志文件上传到同一服务器上
- 运行以下命令分析不同平台间的计算精度差异
1./cruiser.exe --root APP_DIR --log-arm ARM_LOG_DIR --log-x86 x86_LOG_DIR --log OUT_LOG_DIR
优化案例
案例1:气象鹰眼MASNUM调优
通过工具自动插桩分析,定位到max函数在鲲鹏和x86平台的输出不一致。
插桩之前

插桩之后

修改方式:确保max函数的所有参数都是双精度

修改之后核心指标ee要求精度和x86可以做到完全一致


案例2:某碳源汇应用精度调优
源码的调优原理:悟合利用NLP技术对源码进行解析并建立源码的拓扑关系。接着,以指定的主函数或者分析差异日志后的差异点为根节点,对全生命周期进行监视,并在此拓扑关系上建立根的索引调用链。之后,依据此调用链自动插入分析语句。在Arm平台和x86平台运行后,悟合将分析日志以获得差异点的位置,并针对最终差异点进行针对性的优化。其工作原理图如下
- 建立根的索引调用链

- 自动分析差异点
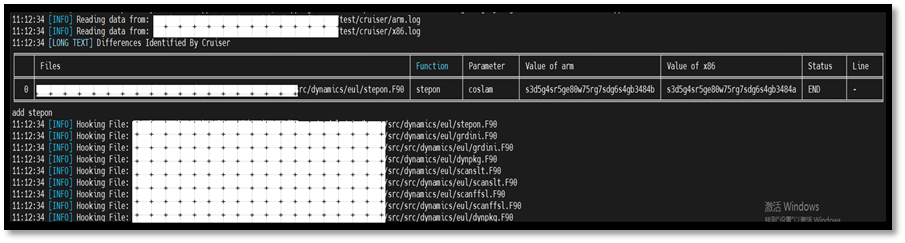
- 源码中插入分析语句
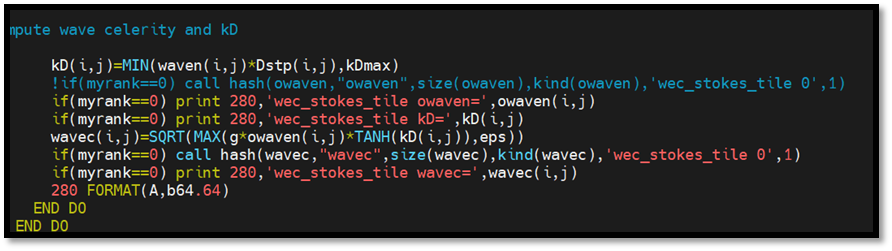
- 最终定位出如下问题:
- 程序存在融合乘加运算,且运算结果前后不一致。
- 存在使用一些数学库场景,前后结果不一致。
- 程序中存在大量网格数据结构及数组,可优化程序内存使用。
- 按照定位结果给出优化方案:
- 去除精度不友好选项
删除原arch/configure_new.defaults编译文件中精度不友好选项‘-ffast-math’,该会使用激进的方式对程序进行优化,但是会对程序中变量的精度参数影响。
- 添加精度友好选项
- 关闭融合乘加计算优化
添加关闭融合乘加计算优化的编译选项‘-ffp-contract=off’,编译器默认会对融合乘加运算进行激进的性能优化,会产生精度差异,使用此选项进行关闭。
- 优化内存使用
- 使用数学库进行优化
优化效果:经过悟合介入优化后,鲲鹏集群模式预测值与地面观测站观测到的真实数据的差值综合最小。
- 去除精度不友好选项
案例3:集合卡曼滤波(EnKF)-NaN值问题定位
集合卡曼滤波(EnKF)是一种资料同化方法,其在卡曼滤波中利用集合预报的方法估计背景误差协方差,以最小化观测值和模拟值的误差协方差为约束条件,对目标进行最优估计。
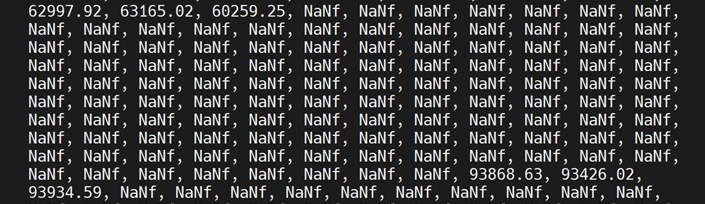
查看输出结果文件,存在大量NaNf值。
向源码中插入nan值检查的分析语句。
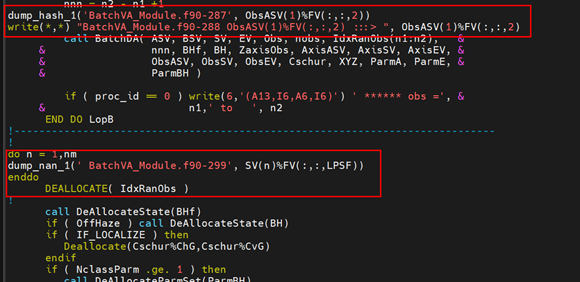
通过工具分析变量是否存在NaN值。

定位过程
- 经过源码溯源,NaN值发生点位于bva_p/Util_Module.f90文件的AddState函数中的乘加计算,原因为XB%FV的输入异常导致。
- 通过监视发现:该NaN值问题在程序bva_p/BatchVA_Module.f90文件的BatchDA函数循环中发生,且在第15轮次循环时发生精度偏差(过程数组变量计算存在NaN值),通过后续迭代计算逐渐放大,最终影响结果文件中的PSFC变量的结果。继续溯源源码,定位出因为bva_p/ObsReject.f90文件的Obs1Reject函数中的DD变量计算异常,导致Ireject变量未能被赋值为IdxRejct的值,返回为0。从而,bva_p/ObtainBH_Module.f90文件中的上层函数ObtainBH未能执行,因此未能继续执行bva_p/BatchVA_Module.f90文件BatchDA函数中的循环,所以缺少一轮循环计算。
- 继续溯源源码,定位出上个问题是由于bva_p/INTP_Bilinear.f90文件中INTP_Bilinear函数中的以下代码中Pij的值影响,而该方法的差异是由PP数组引入的。
- 继续溯源源码,最终定位到PP变量是在bva_p/Util_Module.f90文件的AllocateState函数中初始化的,并后续无更改。
- 输出该变量的第三维度第二层数据,即输出‘XA%FV(:,:,2)’。发现该变量申请内存后,变量内全是随机值。
- 最终定位出是该块数据的内存在申请时存在脏数据,影响后续使用。
优化方案
- 根据以上定位推断,客户程序在内存使用方面存在缺陷。加上内存优化的库“-ljemalloc”,重新编译。
- 并发现程序在融合乘加运算时会发生精度差异,加上“-ffp-model=precise -ffp-contract=off”编译选项进行优化。
- 此外加上“-mcpu=tsv110 -ffp-compatibility=18 -fconvert=big-endian”编译选项进行常规性能优化和精度优化。