鲲鹏流水线
三级流水线的执行容易被打断,导致指令执行效率低,后面发展起来的五级指令流水线技术被认为是经典的处理器设置方式,已经在多种RISC处理器中广泛使用,它在三级流水线(取指、译码、执行)的基础上,增加了两级处理,将“执行”动作进一步分解为执行、访存、回写,解决了三级流水线中存储器访问指令在指令执行阶段的延迟问题,但是容易出现寄存器互锁等问题导致流水线中断。鲲鹏920处理器采用八级流水线结构,首先是提取指令,然后通过解码、寄存器重命名和调度阶段。一旦完成调度,指令将无序发射到八个执行管道中的一个,每个执行管道每个周期都可以接受并完成一条指令,最后就是访存和回写操作。
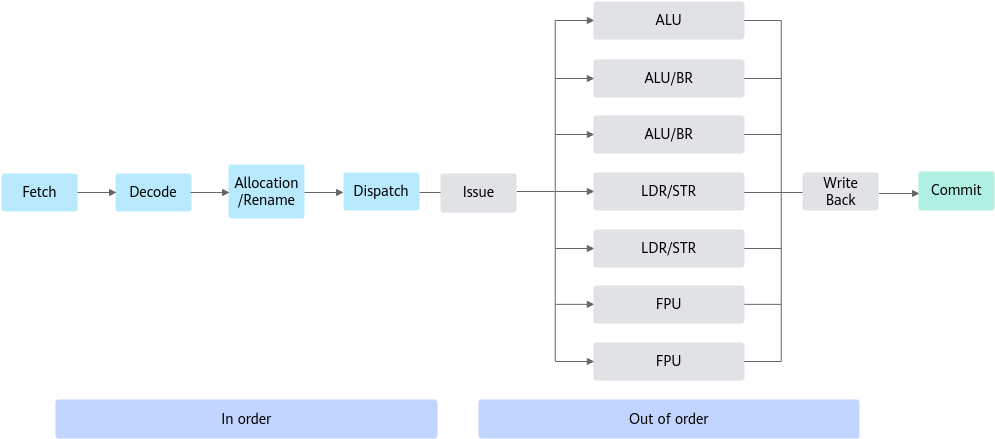
鲲鹏的执行管道支持多种不同的操作指令,如表1所示。
执行管道(助记符) |
功能 |
|---|---|
ALU1 (ALU) |
整型运算 |
ALU2/3/BRU1/2 (ALU/BRU) |
整型运算,分支跳转 |
Multi-cycle (MDU) |
整型移位、乘法、除法、CRC运算 |
LoadStore 0/1 (LS) |
存取运算 |
FP/ASIMD 1 (FSU1) |
ASIMD ALU,ASIMD misc,ASIMD integer multiply,FP convert,FP misc,FP add,FP multiply,FP divide,crypto uops,Hivector |
FP/ASIMD 2 (FSU2) |
ASIMD ALU,ASIMD misc,FP convert,FP misc,FP add,FP multiply,FP sqrt,ASIMD shift uops,Hivector |
无论流水线设计得多么完美,还是会不可避免地发生中断,从而影响流水线的执行效率,下面介绍几种常见的流水线中断场景及解决方案。
分支跳转
代码中经常会用到一些打断程序顺序执行的语句。例如:if、switch、for、while、return等语句都会打断代码的顺序执行,编译器编译处理之后,变成了B、BL、BX、BLX等跳转指令。这些跳转指令会阻塞流水线的执行,如图2所示。
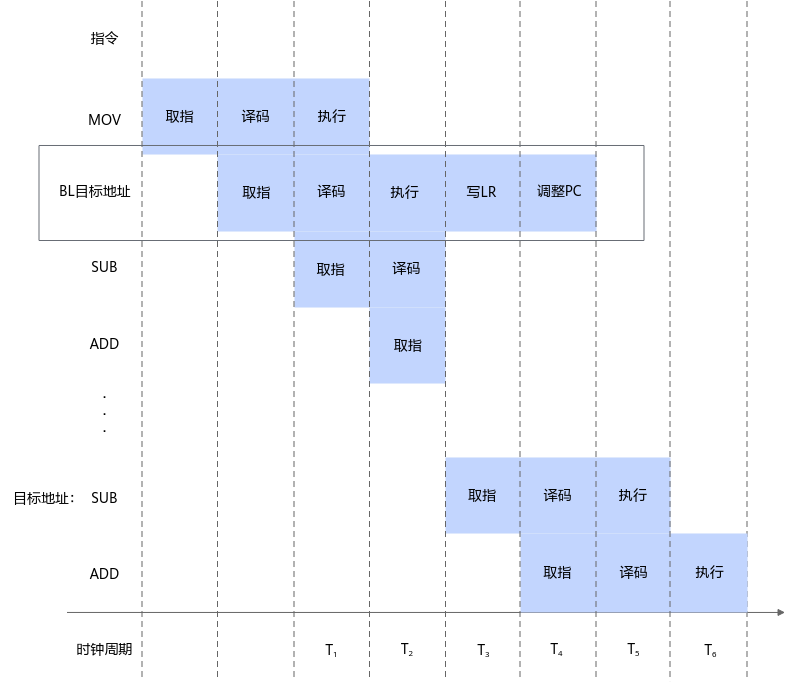
在BL指令执行时,后面的两条指令ADD、SUB指令也已经进入到流水线中,但是并不能被执行。因为BL指令执行完后,会根据计算出来的目标地址调整PC指针,然后从PC指向的地址中重新取指令进入流水线执行,之前进入流水线的ADD、SUB指令被清洗掉,原本处于译码和取指的流水线被阻断。
现在的处理器使用分支预测技术来降低跳转指令对流水线的影响,包含静态预测和动态预测。静态预测是在编译时处理的。动态预测是在代码执行的过程中,在取指阶段,局部范围内预先判断下一条待取指令最有可能的位置,以便达到取指部件所取的指令是按照指令代码的执行顺序取入,而不是完全按照程序指令在存储器中的存放顺序取入。
程序开发人员可以利用静态预测的方法来提升分支预测的准确性。例如查看Linux内核源码可以发现,Linux内核定义了likely()与unlikely()这两个宏:
# ifndef likely # define likely(x) (__builtin_expect(!!(x), 1)) # endif # ifndef unlikely # define unlikely(x) (__builtin_expect(!!(x), 0)) # endif
if (likely(sem->count > 0)) sem->count--; else __down(sem);
但是,有很多的代码分支是跟业务运行场景强相关,无法人为判断代码的分支走向,这种情况怎么办呢?针对这种问题,业界普遍的做法是在源码编译时,编译器自动在代码分支处增加变量,然后将编译出来的程序在真实或者模拟真实环境上长时间运行采样,统计代码各分支进入的次数,计算各分支进入的比例,将此数据反馈给编译器,编译器根据这些统计数据重排代码顺序,将执行概率高的代码紧跟在分支跳转语句之后,以此来减少分支跳转语句对流水线的阻塞,达到提升流水线执行效率和性能的目的。
处理器中断
系统运行的过程中,中断随时都有可能产生,跟当前执行的指令没有任何关系。在中断发生时,处理器不会中断当前正在执行的指令,总是会执行完当前正在执行的指令之后去响应中断,如图3所示(以三级流水线为例)。

假设当前正在执行ADD指令时产生中断,处理器会自动跳转到从0地址开始的异常中断向量表0x18处(B目标地址),保存中断现场,然后跳转到具体中断服务程序(SUB)中处理中断。这个过程中总共发生了两次跳转,再加上中断返回,浪费了很多的CPU周期,大大降低了流水线的效率。
因中断的到来具有不可预知性,所以我们无法通过编译器重排代码来达到优化流水线的目的,但是可以人为干预中断的行为。例如,某些场景下,我们可以修改内核参数,通过合并中断的方式来适当减少中断数。或者对中断进行绑核,使用特定的CPU核专门处理中断,业务进程所在的核可以更专心地处理业务数据而不被中断打断。