锁优化
原理
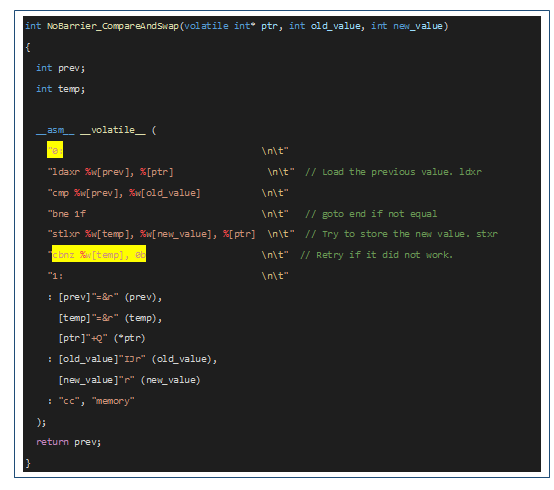
自旋锁和CAS指令都是基于原子操作指令实现,当应用程序执行原子操作失败后,并不会释放CPU资源,而是一直循环运行直到原子操作执行成功为止,导致CPU资源浪费。如下图代码的黄色部分是一个循环等待过程。
修改方式
可以通过perf top分析占用CPU资源靠前的函数,如果锁的申请和释放在5%以上,可以考虑优化锁的实现,修改思路如下:
- 大锁变小锁:并发任务高的场景下,如果系统中存在唯一的全局变量,那么每个CPU核都会申请这个全局变量对应的锁,导致这个锁的竞争严重。可以基于业务逻辑,为每个CPU核或者线程分配对应的资源。
- 使用ldaxr+stlxr两条指令实现原子操作时,可以同时保证内存一致性,而ldxr+stxr指令并不能保证内存一致性,从而需要内存屏障指令(dmb ish)配合来实现内存一致性。从测试情况看,ldaxr+stlxr指令比ldxr+stxr+dmb ish指令的性能高。
- 减少线程并发数:参考调整线程并发数章节。
- 对锁变量使用CacheLine对齐:对于高频访问的锁变量,实际是对锁变量进行高频的读写操作,容易发生伪共享问题。具体优化可以参考CacheLine优化章节。
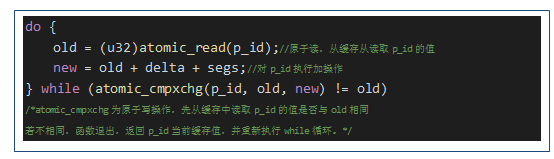
- 优化代码中原子操作的实现。下图代码为某软件的代码实现:
从函数调用逻辑上看,在while循环中会重复执行原子读、变量加以及原子写入操作,代码语句较为冗长。优化思路:使用atomic_add_return指令替换这个代码流程,简化指令,提高性能。替换后的代码如下图:

父主题: 优化方法