OpenMP并行化
原理
OpenMP是一个应用程序编程接口(API),用于在不同平台上使用C、C++和Fortran语言进行独立于平台的共享内存并行编程。作为一个API,它在低级多线程原语上提供了一个高级抽象层。它的编程模型和接口可移植到不同的编译器和硬件体系结构,可在任意数量的CPU核心上扩展。因此,它适用的场景较为广泛,从具有几个CPU核心的台式PC到使用多达数百个核心的超级计算机中的计算节点。现代编译器(GCC 4.4+/Clang 3.8+)通常默认支持OpenMP,无需安装依赖库,使用方便。
OpenMP的基本理念是通过使用特殊的、类似注释的编译器指令(通常称为pragma)来增强顺序代码,向编译器提供如何并行化代码的提示。只需添加适当的pragma,就可以轻松地用于并行化现有的顺序代码。

当遇到下面两种场景时,需要重新设计并行算法。
- 数据的处理顺序不能有依赖关系。并行化意味着同时处理不同的数据,如果此时处理的数据依赖于前一时刻处理的结果,逻辑上就不具备并行化的条件。
- 并行作用域中不存在竞争条件。OpenMP是一个在共享内存体系结构上运行的框架,每个线程都可以访问在并行作用域之外声明的任何变量或数组。如果多个线程同时操作一个数据,那么执行结果就会是随机的,加锁又会使性能下降,与并行的初衷背道而驰。
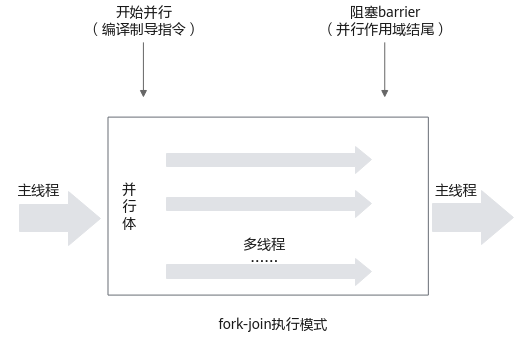
OpenMP采用fork-join的执行模式。开始只存在一个主线程,当需要进行并行计算时,OpenMP会派生出若干个分支线程来执行并行任务。当并行代码执行完成后,分支线程会合,并把控制流程交给单独的主线程。一个典型的fork-join执行模型如图1所示。
修改方式
OpenMP最常用的是并行化for循环,下面以矩阵乘法为例,简要介绍用法。
- 包含OpenMP头文件,例如:include <omp.h>。
- 在需要并行的for循环前,加上编译指导指令。OpenMP并行化测试用例如下图所示。
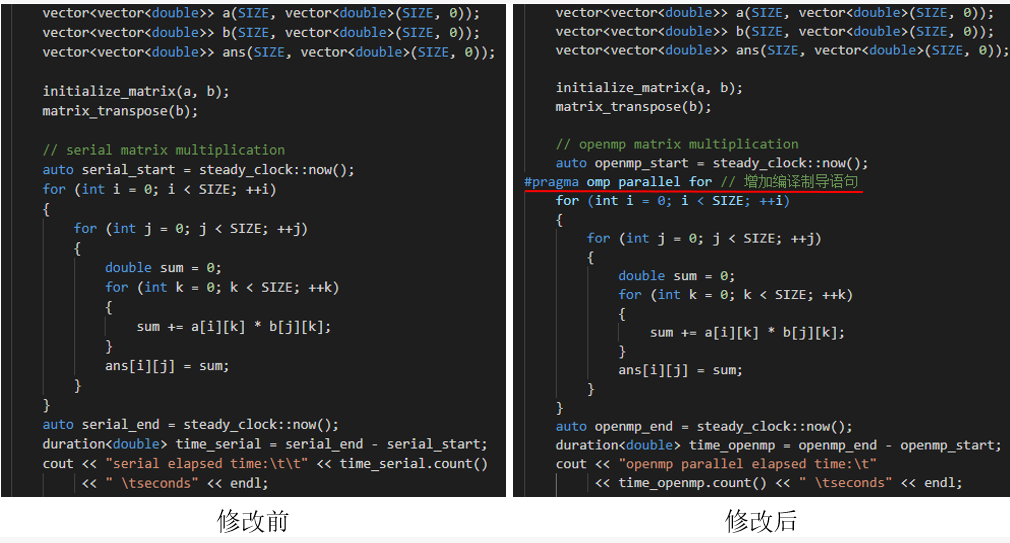
并行作用域前定义的变量默认是公有的,并行作用域中定义的变量默认是私有的。紧跟制导语句的循环变量只能是私有的,检查并行作用域中的其他变量是否需要通过private显式私有化,避免出现竞争的情况。
在本例中,变量i、j、k、sum为私有变量,数组a、b、ans为不存在竞争的公有变量。
- 编译程序。编译器对OpenMP API的支持由编译器标志-fopenmp指定,编译命令为:
1g++ -O2 -std=c++11 -fopenmp matrix_multiplication.cpp -o matrix_multiplication
- 执行程序。在运行时,默认线程数通常等于操作系统看到的逻辑CPU核心数。这里我们使用环境变量OMP_NUM_THREADS来修改它(也可以使用专用接口set_num_threads()或专用子句在源代码中进一步指定线程数量),执行的命令为:
1OMP_NUM_THREADS=2 ./matrix_multiplication
本例在鲲鹏芯片上测试,当SIZE为3000时,串行执行时间56s。OpenMP两个线程并行执行,即0~1499与1500~2999次循环分别在两个线程中并行执行,执行时间为38s,性能提升显著。