集群环境
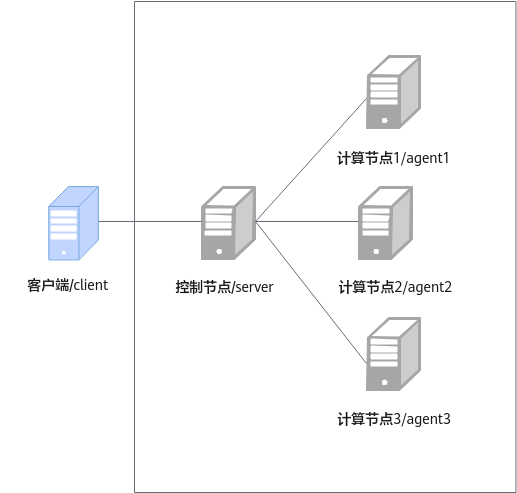
集群规划的环境由五台服务器组成,分别是客户端(1台)、控制节点(1台)、计算节点(3台),组网图如图1所示。其中控制节点作为大数据集群的server端,计算节点分别是大数据集群的agent1、agent2和agent3。在POC测试场景下,客户端可部署在控制节点上。
集群硬件配置
集群内所有节点使用的环境如表1所示:
集群软件版本
使用到的相关软件版本如下表2所示:
|
项目 |
节点类型 |
要求 |
|---|---|---|
|
OS |
所有节点 |
openEuler 22.03 LTS SP1 |
|
JDK |
所有节点 |
毕昇JDK 1.8.0_342 |
|
ZooKeeper |
计算节点 |
3.6.2 |
|
Hadoop |
所有节点 |
3.2.0 |
|
Spark |
所有节点 |
Spark 3.3.1 |

- 集群部署可参考《Spark集群 部署指南(CentOS 7.6&openEuler 20.03)》,Spark部署模式为Spark on Yarn。
- 当前鲲鹏算法库兼容Spark 3.3.1(仅支持部分算法,详情请参见约束与限制),其他平台暂未验证,基于安全诉求,建议使用高版本。
父主题: Spark鲲鹏集群部署