组件参数配置
Web配置
如果需要修改参数,Ambari通常可以通过集群网页进行操作。以Yarn组件为例,只需单击右侧需修改参数的Yarn组件,然后进入其“CONFIGS”页签,在“CONFIGS”页签中找到“SETTING”和“ADVANCED”,即可找到所需参数并进行修改,如图1所示。
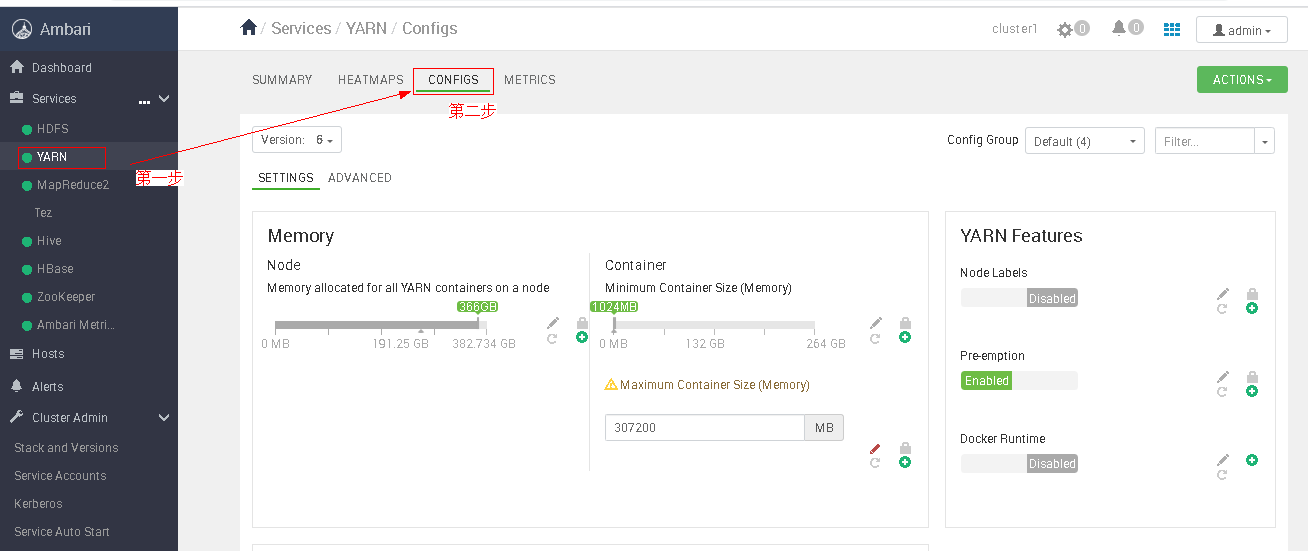
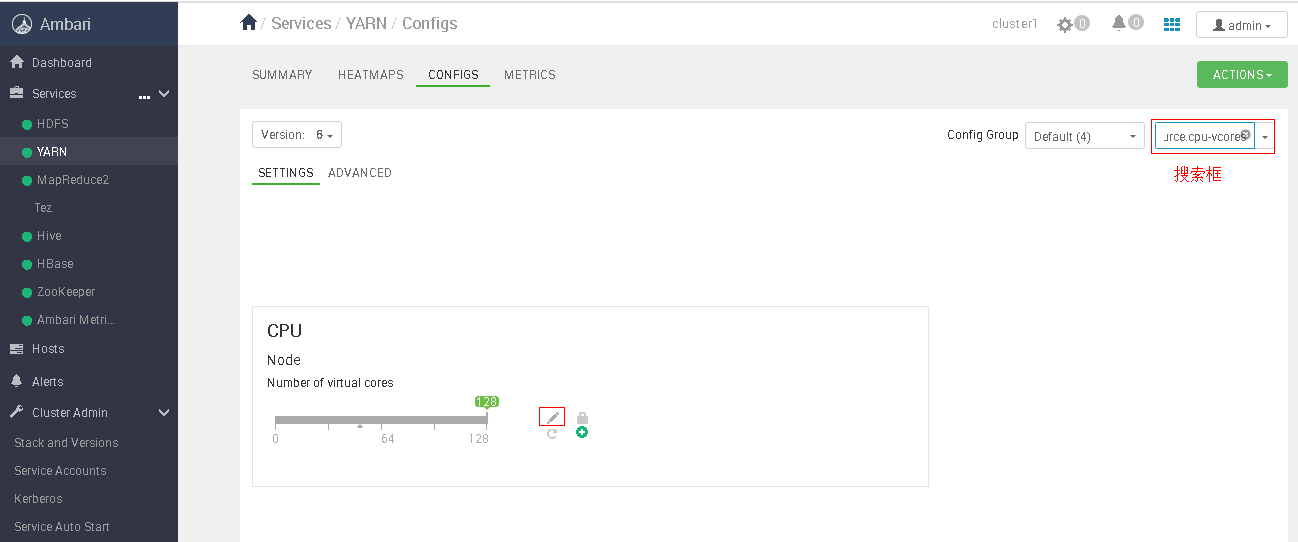
当要修改具体的参数的时候,主要分两种情况,第一种对于参数原本就在网页设置了初始值的,只需要在“CONFIGS”页面的搜索栏直接搜索、修改即可,例如修改Yarn中的yarn.nodemanager.resource.cpu-vcores,只需要在搜索框搜索yarn.nodemanager.resource.cpu-vcores,单击修改按钮,并设置对应的参数即可。
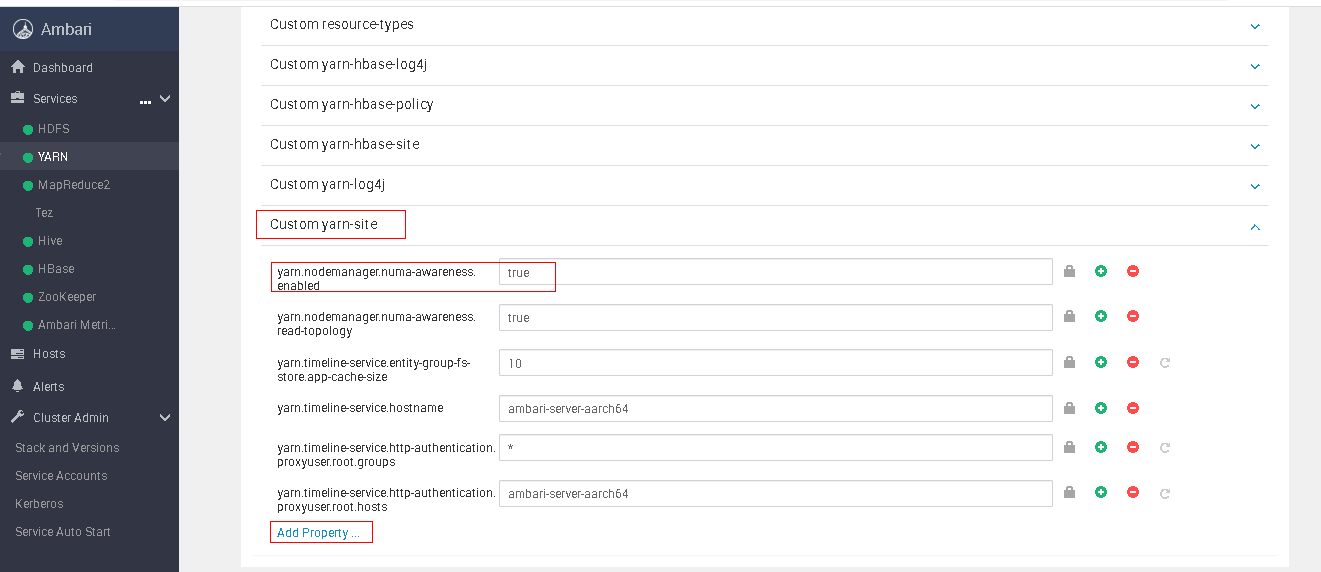
第二种对于原本页面上没有设置初始值的参数,例如yarn.nodemanager.numa-awareness.enabled这一参数,就需要在对应组件的Custom yarn-site中手动添加(其余组件需要手动添加的也是在对应的Custom ***-site文件中)。
具体的各个组件的参数设置如表1所示。
|
组件 |
参数名 |
推荐值 |
修改原因 |
|---|---|---|---|
|
Yarn ->NodeManager Yarn ->ResourceManager |
ResourceManager Java heap size |
1024 |
修改JVM内存大小,保证内存水平较高,减少GC的频率。
说明:
非固定值,需要根据GC的释放情况来调大或调小Xms及Xmx的值。 |
|
NodeManager Java heap size |
1024 |
||
|
Yarn ->NodeManager |
yarn.nodemanager.resource.cpu-vcores |
鲲鹏计算平台48核环境推荐值48。 |
可分配给Container的CPU核数。 |
|
Yarn ->NodeManager |
yarn.nodemanager.resource.memory-mb |
与实际数据节点物理内存总量相等。 |
可分配给Container的内存。 |
|
Yarn ->NodeManager |
yarn.nodemanager.numa-awareness.enabled |
True |
NodeManager启动Container时的NUMA感知。 |
|
Yarn ->NodeManager |
yarn.nodemanager.numa-awareness.read-topology |
True |
NodeManager的NUMA拓扑自动感知。 |
|
MapReduce2 |
mapreduce.map.memory.mb |
7168 |
一个Map Task可使用的内存上限。 |
|
MapReduce2 |
mapreduce.reduce.memory.mb |
14336 |
一个Reduce Task可使用的资源上限。 |
|
MapReduce2 |
mapreduce.job.reduce.slowstart.completedmaps |
0.35 |
当Map完成的比例达到该值后才会为Reduce申请资源。 |
|
HDFS ->NameNode |
NameNode Java heap size |
3072 |
修改JVM内存大小,保证内存水平较高,减少GC的频率。
说明:
非固定值,需要根据GC的释放情况来调大或调小Xms及Xmx的值。 |
|
NameNode new generation size |
384 |
||
|
NameNode maximum new generation size |
384 |
||
|
HDFS ->DataNode |
dfs.datanode.handler.count |
512 |
DataNode服务线程数,可适量增加。 |
|
HDFS ->NameNode |
dfs.namenode.service.handler.count |
32 |
NameNode RPC服务端监测DataNode和其他请求的线程数,可适量增加。 |
|
HDFS ->NameNode |
dfs.namenode.handler.count |
1200 |
NameNode RPC服务端监测客户端请求的线程数,可适量增加。 |
|
TEZ |
tez.am.resource.memory.mb |
7168 |
等同于yarn.scheduler.minimum-allocation-mb,默认7168。 |
|
TEZ |
tez.runtime.io.sort.mb |
1892MB |
设置为40%*hive.tez.container.size,一般不超过2G。 |
|
TEZ |
tez.am.container.reuse.enabled |
true |
Container重用开关。 |
|
TEZ |
tez.runtime.unordered.output.buffer.size-mb |
537 |
10%* hive.tez.container.size。 |
|
TEZ |
tez.am.resource.cpu.vcores |
10 |
使用的虚拟CPU数量,默认1,需要手动添加。 |
|
TEZ |
tez.container.max.java.heap.fraction |
0.85 |
基于Yarn提供的内存,分配给Java进程的百分比,默认是0.8,需要手动添加。 |
客户端配置
以下是针对TPC-DS的99条SQL查询的Hive通用参数调优建议,仅列出需要修改的调优参数,调优建议如表2所示。
|
参数名称 |
参数含义 |
建议取值 |
|---|---|---|
|
hive.execution.engine |
指定Hive的查询执行引擎为Tez。若不配置,Hive默认使用MapReduce,适合简单任务,但复杂任务性能较差。 |
tez |
|
hive.cbo.enable |
启用成本优化器。CBO会根据表的统计信息(如数据量、字段基数和数据分布)计算“最优执行计划”(如选择Join顺序、Join类型),而非依赖固定规则。 |
TRUE |
|
hive.exec.compress.intermediate |
启用中间数据压缩。减少中间数据的磁盘占用和网络传输量,提升任务速度。 |
TRUE |
|
hive.exec.reducers.max |
指定Hive任务的最大Reduce数量。Reduce数量决定了聚合/Join任务的并发度:数量过少会导致单个Reduce处理数据量过大(任务慢、OOM);数量过多会导致小文件过多、资源碎片化; |
500 |
|
hive.map.aggr |
启用Map端聚合,对聚合类查询(如GROUP BY),在Map端先对局部数据做聚合(如先统计每个Map内的“用户数”),再将聚合结果发送到Reduce端,减少Reduce端的数据量,降低网络IO;适合数据重复率高的场景。 |
TRUE |
|
hive.vectorized.execution.enabled |
启用向量执行,从逐行处理数据改为批量处理数据,减少CPU的指令开销,提升计算效率。仅支持ORC文件格式和部分算子(如过滤、聚合、Join),非ORC表无法享受该优化。 |
TRUE |
|
hive.auto.convert.join |
启用自动转换Join类型。Hive会根据表的大小自动选择最优Join策略:
|
TRUE |
|
hive.auto.convert.join.noconditionaltask |
启用 无条件任务的Join合并。当多个MapJoin(如3个小表 + 1个大表)可以合并为一个任务执行时,Hive会自动合并,避免创建多个独立的MapJoin任务。 |
TRUE |
|
hive.cli.tez.session.async |
禁用Hive CLI的Tez会话异步模式。当Hive CLI提交Tez任务时,异步模式”会让CLI立即返回(任务在后台执行),同步模式会让CLI等待任务结束,实时显示任务日志。 |
FALSE |
|
hive.tez.container.size |
指定Tez任务的容器内存大小(单位:MB)。 |
7168 |
|
tez.am.resource.memory.mb |
指定Tez的AM内存大小(单位:MB)。 |
7168 |
|
tez.task.resource.memory.mb |
指定Tez的单个Task(任务)内存大小(单位:MB)。 |
7168 |
|
tez.am.container.reuse.enabled |
启用Tez AM容器复用。默认情况下,每个Tez任务会创建一个新的AM容器,任务结束后销毁;启用复用后,同一个用户的多个Tez任务可复用同一个AM容器; |
TRUE |
修改$HIVE_HOME/conf/hive-site.xml,或在hive命令行中设置,或在查询语句前添加以下参数。
- 方式一:修改$HIVE_HOME/conf/hive-site.xml配置文件。

这种方式配置的参数需要重启Hive才能生效。
- 在hive-site.xml配置文件中配置目标参数的值。示例:配置“hive.execution.engine”的参数值为“tez”。
<property> <name>hive.execution.engine</name> <value>tez</value> </property>
- 重启Hive。
- 在hive-site.xml配置文件中配置目标参数的值。示例:配置“hive.execution.engine”的参数值为“tez”。
- 方式二:在hive命令行中设置。
这种方式配置的参数退出会话后失效。再次进入会话需重新设置。
- 登录hive命令行。
hive
- 逐条执行set命令。示例:配置“hive.execution.engine”的参数值为“tez”。
set hive.execution.engine=tez; set hive.cbo.enable=true;
- 登录hive命令行。
- 方式三:在查询语句前添加。
这种方式仅针对您输入的查询语句生效。
通过hive命令提交查询时,将参数作为命令行参数传入。示例:对SELECT * FROM your_table LIMIT 10语句配置“hive.execution.engine”的参数值为“tez”。
hive \ --hiveconf hive.execution.engine=tez \ --hiveconf hive.cbo.enable=true \ -e "SELECT * FROM your_table LIMIT 10;"